溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
hdfs namenode HA高可用方案
1、hadoop-ha 集群運作機制介紹
所謂HA,即高可用(7*24 小時不中斷服務) //hadoop 2.x 內置了 HA 方案
實現高可用最關鍵的是消除單點故障
hadoop-ha 嚴格來說應該分成各個組件的HA 機制
提示:
在之前沒有HA機制的時候,secondary namenode 和standay namenode 有很大的區別
secondary namenode 不可以替代namenode;而standay namenode 可以完全的替代namenode
HA技術要點 :元數據管理 2個namenode的狀態管理 如何防止腦裂
HDFS 的HA 機制
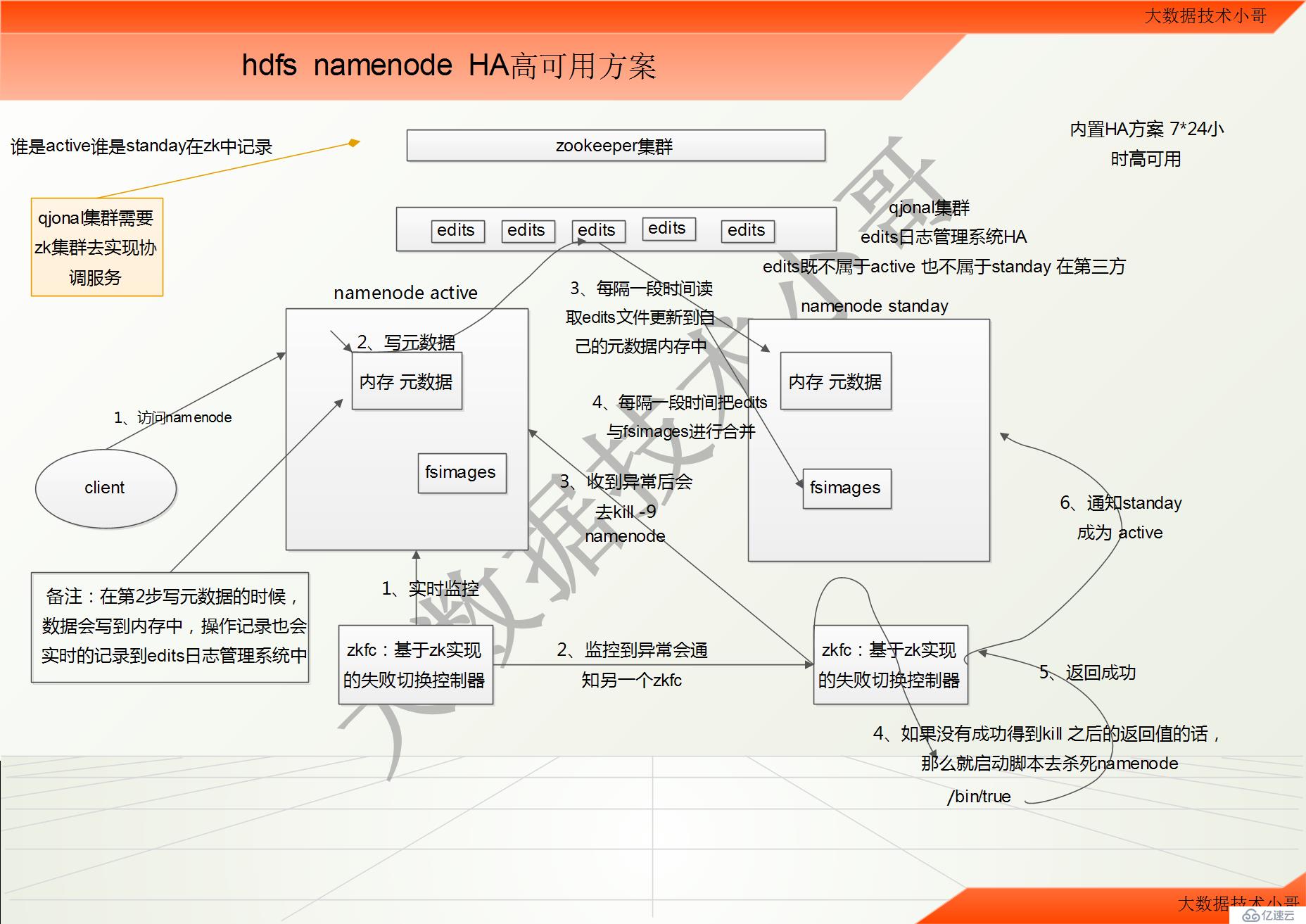
通過雙namenode 消除單點故障
雙namenode 協調工作的要點:
A、元數據管理方式需要改變:
內存中各自保存一份元數據
Edits 日志只能有一份,只有Active 狀態的namenode 節點可以做寫操作
兩個namenode 都可以讀取edits
共享的edits 放在一個共享存儲中管理(qjournal 和NFS 兩個主流實現)
1、客戶端訪問active namenode //雙namenode中的fsimages一開始初始化的時候,都是完全一樣,都是空的
2、寫數據的時候,寫入數據寫到active namenode中內存元數據的時候,也會實時的更新到qjonal集群edits日志文件系統中
3、standay 會沒隔一段時間去讀取edits文件,并更新到自己的元數據內存中,保持和active最小差異
4、每隔一段時間,standay中的fsimage會和edits更新一次,保持在本地
備注:edits既不屬于active也不屬于standay 依靠第三方qjonal集群 完全獨立
假設 active namenode 宕機了,此時 standay 和active有點差異,但是差異很小,standay迅速從edits日志系統中更新最新一次老的active的操作,完全和老active一樣的元數據,那么就要可以迅速的對外來提供服務。
B、需要一個狀態管理功能模塊
實現了一個zkfailover,常駐在每一個namenode 所在的節點
每一個zkfailover 負責監控自己所在的namenode 節點,利用zk 進行狀態標識
當需要進行狀態切換時,由zkfailover 來負責切換
切換時需要防止brain split 現象的發生
1、active上的zkfc實時監控自己namenode的狀態健康信息
2、如果發生了異常之后會控制standay的zkfc
3、standay的zkfc收到異常之后會去kill -9 active namenode
4、如果standay的zkfc沒有成功得到kill -9 之后的返回值的話,那么就啟動腳本去殺死active namenode 腳本位置為/bin/true
5、殺死active namenode之后,就成功得到訪問值
6、standay的zkfc通知standay namenode稱為active 對外服務。
什么是zkfc:就是基于zookeeper實現的失敗切換控制器
如何在狀態切換時避免brain split(腦裂)?
腦裂:active namenode工作不正常后,zkfc在zookeeper中寫入一些數據,表明異常,這時standby namenode中的zkfc讀到異常信息,并將standby節點置為active。但是,如果之前的active namenode并沒有真的死掉,出現了假死(死了一會兒后又正常了),這樣,就有兩臺namenode同時工作了。這種現象稱為腦裂。
解決方案:standby namenode感知到主用節點出現異常后并不會立即切換狀態,zkfc會首先通過ssh遠程殺死active節點的 namenode進程(kill -9 進程號)。如果在一段時間內standby的namenode節點沒有收到kill執行成功的回執,standby節點會執行一個自定義腳本,盡量保證不會出現腦裂問題!這個機制在hadoop中稱為fencing(包括ssh發送kill指令,執行自定義腳本兩道保障)。從解決方案中可知;當發生active節點崩壞時;hadoop會進行以下兩個操作:
1)通過ssh kill掉active節點的namenode進程
2)執行自定義腳本
原文:https://blog.csdn.net/qq_22310551/article/details/85700978
如何沒有及時得到kill的成功返回信息,在調用一個用戶指定的shell腳本程序。
[root@hadoop-node01 bin]# ls -l /bin/true //腳本位置在bin下面
-rwxr-xr-x. 1 root root 21112 10月 15 2014 /bin/true
在cdh中這個程序在
HDFS High Availability 防御方法
dfs.ha.fencing.methods
用于服務防御的防御方法列表。shell(./cloudera_manager_agent_fencer.py) 是一種設計為使用 Cloudera Manager Agent 的防御機制。sshfence 方法使用 SSH。如果使用自定義防御程序(可能與共享存儲、電源裝置或網絡交換機通信),則使用 shell 調用它們。
Cloudera Manager 防御策略的超時時限
dfs.ha.fencing.cloudera_manager.timeout_millis 10000
基于 Cloudera Manager 代理的防御程序使用的超時時限(毫秒)
zookeeper在HA機制中的作用
1、QJN集群需要zk實現協調服務
2、namenode中誰是active誰是standay記錄在zk中
3、zkfc基于zookeeper實現失敗切換控制器
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





