溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么基于k8s 進行開發高可靠服務,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
應用的設計和開發不能脫離業務需求,對 MySQL 應用的需求如下:
數據高可靠
服務高可用
易使用
易運維
為了實現上述需求,需要依靠 k8s 和應用兩方面協同工作,即開發基于 k8s 高可靠應用,既需要 k8s 相關的知識,也需要應用領域內的知識。
下述將根據上述需求來分析相應的解決方案。
1.數據高可靠
數據的高可靠一般依賴于這幾方面: ? 冗余 ? 備份/恢復
我們使用 Percona XtraDB Cluster 作為 MySQL 集群方案,它是 multi-master 的 MySQL 架構,實例間基于 Galera Replication 技術實現數據的實時同步。這種集群方案可以避免 master-slave 架構的集群在主從切換時可能出現的數據丟失現象,進一步提升數據的可靠性。 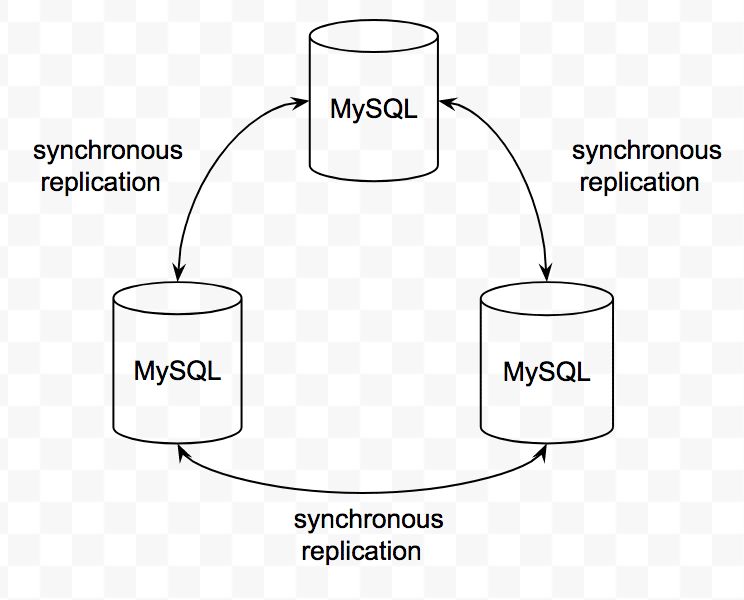
??備份方面,我們使用 xtrabackup 作為備份/恢復方案,實現數據的熱備份,在備份期間不影響用戶對集群的正常訪問。
提供「定時備份」的同時,我們也提供「手動備份」,以滿足業務對備份數據的需求。
2.服務高可用
這里從「數據鏈路」和「控制鏈路」兩個角度來分析。
「數據鏈路」是用戶訪問 MySQL 服務的鏈路,我們使用 3 主節點的 MySQL 集群方案,通過 TLB (七牛自研的四層負載均衡服務) 對用戶提供訪問入口。TLB 既實現了訪問層面對 MySQL 實例的負載均衡,又實現了對服務的健康檢測,自動摘除異常的節點,同時在節點恢復時自動加入該節點。如下圖: 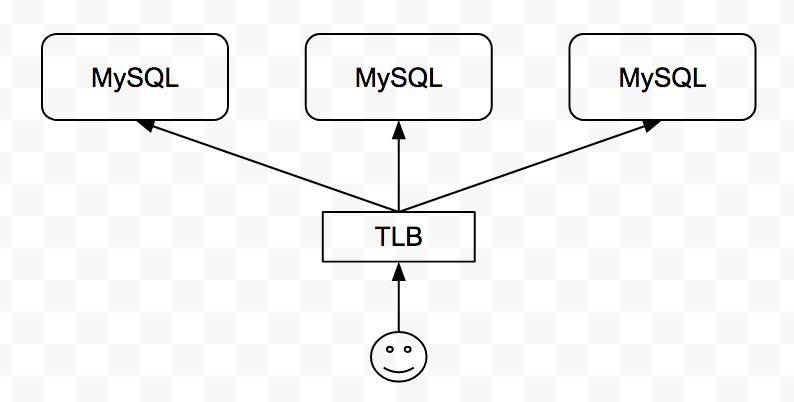
??基于上述 MySQL 集群方案和 TLB,一個或兩個節點的異常不會影響用戶對 MySQL 集群的正常訪問,確保 MySQL 服務的高可用。
「控制鏈路」是 MySQL 集群的管理鏈路,分為兩個層面: ? 全局控制管理 ? 每個 MySQL 集群的控制管理 全局控制管理主要負責「創建/刪除集群」「管理所有 MySQL 集群狀態」等,基于 Operator 的理念來實現。每個 MySQL 集群有一個控制器,負責該集群的「任務調度」「健康檢測」「故障自動處理」等。
這種拆解將每個集群的管理工作下放到每個集群中,降低了集群間控制鏈路的相互干擾,同時又減輕了全局控制器的壓力。 如下圖: 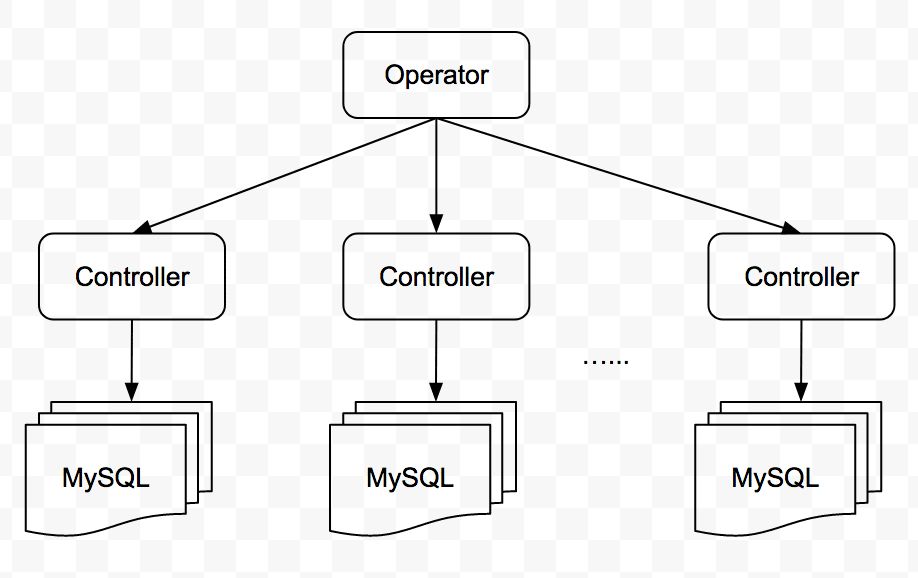
??這里簡單介紹下 Operator 的理念和實現。
Operator 是 CoreOS 公司提出的一個概念,用來創建、配置、管理復雜應用,由兩部分構成: Resource ? 自定義資源 ? 為用戶提供一種簡單的方式描述對服務的期望 Controller ? 創建 Resource ? 監聽 Resource 的變更,用來實現用戶對服務的期望
工作流程如下圖所示: 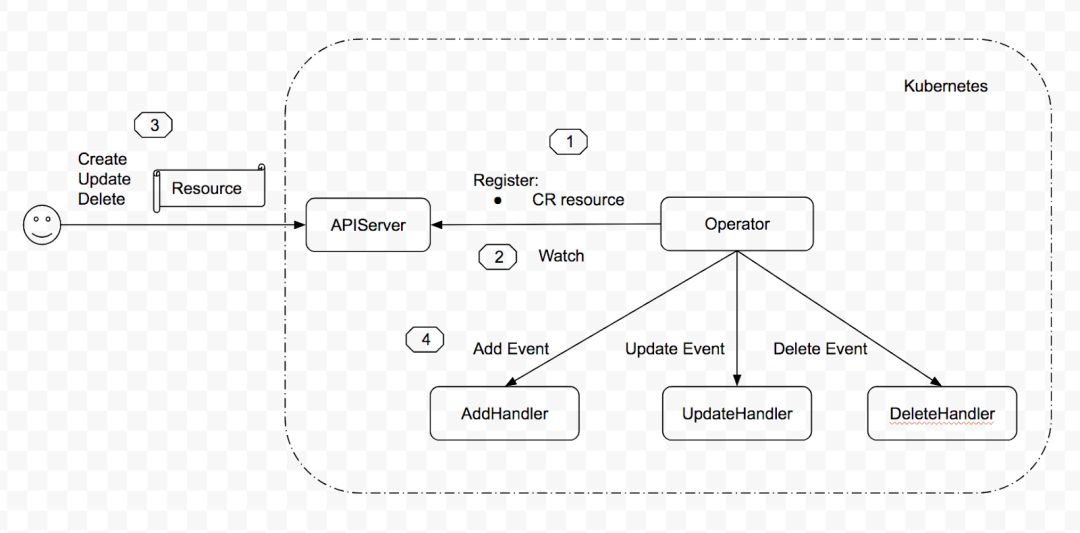
??即:
注冊 CR (CustomResource) 資源
監聽 CR objects 的變更
用戶對該 CR 資源進行 CREATE/UPDATE/DELETE 操作
觸發相應的 handler 進行處理
我們根據實踐,對開發 Operator 做了如下抽象:??
CR抽象為這樣的結構體:??
對 CR ADD/UPDATE/DELETE events 的操作,抽象為如下接口:??
在上述抽象的基礎上,七牛提供了一個簡單的 Operator 框架,透明化了創建 CR、監聽 CR events 等的操作,將開發 Operator 的工作變的更為簡單。
我們開發了 MySQL Operator 和 MySQL Data Operator,分別用來負責「創建/刪除集群」和「手動備份/恢復」工作。
由于每個 MySQL 集群會有多種類型的任務邏輯,如「數據備份」「數據恢復」「健康檢測」「故障自動處理」等,這些邏輯的并發執行可能會引發異常,故需要任務調度器來協調任務的執行,Controller 起到的就是這方面的作用: ?
通過 Controller 和各類 Worker,每個 MySQL 集群實現了自運維。
在「健康檢測」方面,我們實現了兩種機制: ? 被動檢測 ? 主動檢測 「被動檢測」是每個 MySQL 實例向 Controller 匯報健康狀態,「主動檢測」是由 Controller 請求每個 MySQL 實例的健康狀態。這兩種機制相互補充,提升健康檢測的可靠度和及時性。
對于健康檢測的數據,Controller 和 Operator 均會使用,如下圖所示: ??
Controller 使用健康檢測數據是為了及時發現 MySQL 集群的異常,并做相應的故障處理,故需要準確、及時的健康狀態信息。它在內存中維護所有 MySQL 實例的狀態,根據「主動檢測」和「被動檢測」的結果更新實例狀態并做相應的處理。
Operator 使用健康檢測數據是為了向外界反映 MySQL 集群的運行情況,并在 Controller 異常時介入到 MySQL 集群的故障處理中。
在實踐中,由于健康檢測的頻率相對較高,會產生大量的健康狀態,若每個健康狀態都被持久化,那么 Operator 和 APIServer 均會承受巨大的訪問壓力。由于這些健康狀態僅最新的數據有意義,故在 Controller 層面將待向 Operator 匯報的健康狀態插入到一個有限容量的 Queue 中,當 Queue 滿時,舊的健康狀態將被丟棄。
當 Controller 檢測到 MySQL 集群異常時,將會進行故障自動處理。
先定義故障處理原則: ? 不丟數據 ? 盡可能不影響可用性 ? 對于已知的、能夠處理的故障進行自動處理 ? 對于未知的、不能夠處理的故障不自動處理,人工介入 在故障處理中,有這些關鍵問題: ? 故障類型有哪些 ? 如何及時檢測和感知故障 ? 當前是否出現了故障 ? 出現的故障是哪種故障類型 ? 如何進行處理 針對上述關鍵問題,我們定義了 3 種級別的集群狀態:
Green ? 可以對外服務 ? 運行節點數量符合預期 Yellow ? 可以對外服務 ? 運行節點數量不符合預期 Red ? 不能對外服務
同時針對每個 mysqld 節點,定義了如下狀態:
Green ? 節點在運行 ? 節點在 MySQL 集群中 Yellow ? 節點在運行 ? 節點不在 MySQL 集群中 Red-clean ? 節點優雅退出 Red-unclean ? 節點非優雅退出 Unknown ? 節點狀態不可知
Controller 收集到所有 MySQL 節點狀態后,會根據這些節點的狀態推算 MySQL 集群的狀態。當檢測到 MySQL 集群狀態不是 Green 時,會觸發「故障處理」邏輯,該邏輯會根據已知的故障處理方案進行處理。若該故障類型未知,人工介入處理。整個流程如下圖: 
??由于每種應用的故障場景和處理方案不同,這里不再敘述具體的處理方法。
3.易使用
我們基于 Operator 的理念實現了高可靠的 MySQL 服務,為用戶定義了兩類資源,即 QiniuMySQL 和 QiniuMySQLData。前者描述用戶對 MySQL 集群的配置,后者描述手動備份/恢復數據的任務,這里以 QiniuMySQL 為例。
用戶可通過如下簡單的 yaml 文件觸發創建 MySQL 集群的操作:
在集群創建好后,用戶可通過該 CR object 的 status 字段獲取集群狀態:??
這里再引入一個概念:Helm。
Helm 是為 k8s 提供的包管理工具,通過將應用打包為 Chart,標準化了 k8s 應用的交付、部署和使用流程。
Chart 本質上是 k8s yaml 文件和參數文件的集合,這樣可以通過一個 Chart 文件進行應用的交付。Helm 通過操作 Chart,可一鍵部署、升級應用。
由于篇幅原因及 Helm 操作的通用性,這里不再描述具體的使用過程。
4.易運維
除了上述實現的「健康檢測」「故障自動處理」以及通過 Helm 管理應用的交付、部署,在運維過程中還有如下問題需要考慮: ? 監控/告警 ? 日志管理
我們通過 prometheus + grafana 做監控/告警服務,服務將 metric 數據以 HTTP API 暴露給 prometheus,由 prometheus server 定時拉取。開發人員在 grafana 上將 prometheus 中的監控數據可視化,根據對監控圖表和應用的把握,在監控圖中設置告警線,由 grafana 實現告警。
這種先可視化監控后告警的方式,極大程度上增強了我們對應用運行特征的把握,明確需要關注的指標和告警線,降低無效告警的產生量。
在開發中,我們通過 gRPC 實現服務間的通信。在 gRPC 生態系統中,有個名為 go-grpc-prometheus 的開源項目,通過在服務中插入幾行簡單的代碼,就可以實現對 gRPC server 所有 rpc 請求的監控打點。
對于容器化服務,日志管理包括「日志收集」和「日志滾動」兩方面維度。
我們將服務日志打到 syslog 中,再通過某種手段將 syslog 日志轉入到容器的 stdout/stderr 中,方便外部采用常規的方式進行日志收集。同時,在 syslog 中配置了 logrotate 功能,自動進行日志的滾動操作,避免日志占滿容器磁盤空間引發服務異常。
為了提升開發效率,我們使用 https://github.com/phusion/baseimage-docker 作為基礎鏡像,其中內置了 syslog 和 lograte 服務,應用只關心把日志打入 syslog 即可,不用關心日志的收集和日志滾動問題。
通過上述描述,完整的 MySQL 應用架構如下: 
在開發基于 k8s 的高可靠 MySQL 應用過程中,隨著對 k8s 和 MySQL 理解的深入,我們不斷進行抽象,逐步將如下通用的邏輯和最佳實踐以模塊的方式實現: ? Operator 開發框架 ? 健康檢測服務 ? 故障自動處理服務 ? 任務調度服務 ? 配置管理服務 ? 監控服務 ? 日志服務 ? etc.
隨著這些通用邏輯和最佳實踐的模塊化,在開發新的基于 k8s 的高可靠應用時,開發者可像「搭積木」一樣將與 k8s 相關的交互快速搭建起來,這樣的應用由于已經運用了最佳實踐,從一開始就具備高可靠的特性。同時,開發者可將注意力從 k8s 陡峭的學習曲線轉移到應用自身領域,從應用自身加強服務的可靠性。
關于怎么基于k8s 進行開發高可靠服務問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





