溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下 pandas計算工具有哪些 ,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
序列(Series)、數據框(DataFrame)和Panel(面板)都有pct_change方法來計算增長率(需要先使用fill_method來填充空值)
Series.pct_change(periods=1, fill_method=’pad’, limit=None, freq=None, **kwargs)
periods參數控制步長
In [1]: ser = pd.Series(np.random.randn(8))In [2]: ser.pct_change()Out[2]: 0 NaN1 -1.6029762 4.3349383 -0.2474564 -2.0673455 -1.1429036 -1.6882147 -9.759729dtype: float64
序列Series對象有cov方法來計算協方差
Series.cov(other, min_periods=None)
In [5]: s1 = pd.Series(np.random.randn(1000))In [6]: s2 = pd.Series(np.random.randn(1000))In [7]: s1.cov(s2)Out[7]: 0.00068010881743108746
數據框DataFrame對象的cov方法
DataFrame.cov(min_periods=None)
In [8]: frame = pd.DataFrame(np.random.randn(1000, 5), columns=['a', 'b', 'c', 'd', 'e'])In [9]: frame.cov()Out[9]: a b c d e a 1.000882 -0.003177 -0.002698 -0.006889 0.031912b -0.003177 1.024721 0.000191 0.009212 0.000857c -0.002698 0.000191 0.950735 -0.031743 -0.005087d -0.006889 0.009212 -0.031743 1.002983 -0.047952e 0.031912 0.000857 -0.005087 -0.047952 1.042487
相關系數有三種計算方法
| Method name | Description |
|---|---|
| pearson?(default) | Standard correlation coefficient |
| kendall | Kendall Tau correlation coefficient |
| spearman | Spearman rank correlation coefficient |
Series.corr(other, method=’pearson’, min_periods=None)
DataFrame.corr(method=’pearson’, min_periods=1)
In [15]: frame = pd.DataFrame(np.random.randn(1000, 5), columns=['a', 'b', 'c', 'd', 'e'])In [19]: frame.corr()Out[19]: a b c d e a 1.000000 0.013479 -0.049269 -0.042239 -0.028525b 0.013479 1.000000 -0.020433 -0.011139 0.005654c -0.049269 -0.020433 1.000000 0.018587 -0.054269d -0.042239 -0.011139 0.018587 1.000000 -0.017060e -0.028525 0.005654 -0.054269 -0.017060 1.000000
DataFrame.corrwith(other, axis=0, drop=False)
Series.rank(axis=0, method=’average’, numeric_only=None, na_option=’keep’, ascending=True, pct=False)
In [31]: s = pd.Series(np.random.np.random.randn(5), index=list('abcde'))In [32]: s['d'] = s['b'] # so there's a tieIn [33]: s.rank()Out[33]:
a 5.0b 2.5c 1.0d 2.5e 4.0dtype: float64DataFrame.rank(axis=0, method=’average’, numeric_only=None, na_option=’keep’, ascending=True, pct=False)
axis=0則是按行排序,axis=1按列排序
ascending=True為升序,False為降序
In [34]: df = pd.DataFrame(np.random.np.random.randn(10, 6)) In [35]: df[4] = df[2][:5] # some ties In [36]: df Out[36]: 0 1 2 3 4 50 -0.904948 -1.163537 -1.457187 0.135463 -1.457187 0.294650 1 -0.976288 -0.244652 -0.748406 -0.999601 -0.748406 -0.800809 2 0.401965 1.460840 1.256057 1.308127 1.256057 0.876004 3 0.205954 0.369552 -0.669304 0.038378 -0.669304 1.140296 4 -0.477586 -0.730705 -1.129149 -0.601463 -1.129149 -0.211196 5 -1.092970 -0.689246 0.908114 0.204848 NaN 0.463347 6 0.376892 0.959292 0.095572 -0.593740 NaN -0.069180 7 -1.002601 1.957794 -0.120708 0.094214 NaN -1.467422 8 -0.547231 0.664402 -0.519424 -0.073254 NaN -1.263544 9 -0.250277 -0.237428 -1.056443 0.419477 NaN 1.375064 In [37]: df.rank(1) Out[37]: 0 1 2 3 4 50 4.0 3.0 1.5 5.0 1.5 6.0 1 2.0 6.0 4.5 1.0 4.5 3.0 2 1.0 6.0 3.5 5.0 3.5 2.0 3 4.0 5.0 1.5 3.0 1.5 6.0 4 5.0 3.0 1.5 4.0 1.5 6.0 5 1.0 2.0 5.0 3.0 NaN 4.0 6 4.0 5.0 3.0 1.0 NaN 2.0 7 2.0 5.0 3.0 4.0 NaN 1.0 8 2.0 5.0 3.0 4.0 NaN 1.0 9 2.0 3.0 1.0 4.0 NaN 5.0
Series.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0)
window:移動窗口的大小
min_periods:??
center:是否在中間設置標簽,默認False
win type=??
In [38]: s = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
r = s.rolling(window=60)
In [42]: r
Out[42]: Rolling [window=60,center=False,axis=0]
In [43]: r.mean()
Out[43]:
2000-01-01 NaN2000-01-02 NaN2000-01-03 NaN2000-01-04 NaN2000-01-05 NaN2000-01-06 NaN2000-01-07 NaN... 2002-09-20 -62.6941352002-09-21 -62.8121902002-09-22 -62.9149712002-09-23 -63.0618672002-09-24 -63.2138762002-09-25 -63.3750742002-09-26 -63.539734Freq: D, dtype: float64
In [44]: s.plot(style='k--')
Out[44]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff282080dd0>
In [45]: r.mean().plot(style='k')
Out[45]: <matplotlib.axes._subplots.AxesSubplot at 0x7ff282080dd0>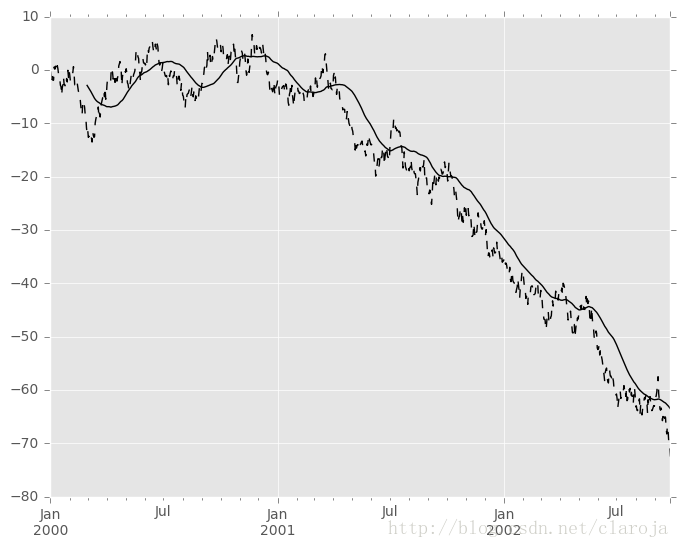
在數據框匯總將會作用于每一列
DataFrame.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0)
In [46]: df = pd.DataFrame(np.random.randn(1000, 4),
....: index=pd.date_range('1/1/2000', periods=1000),
....: columns=['A', 'B', 'C', 'D'])
....:
In [47]: df = df.cumsum()In [48]: df.rolling(window=60).sum().plot(subplots=True)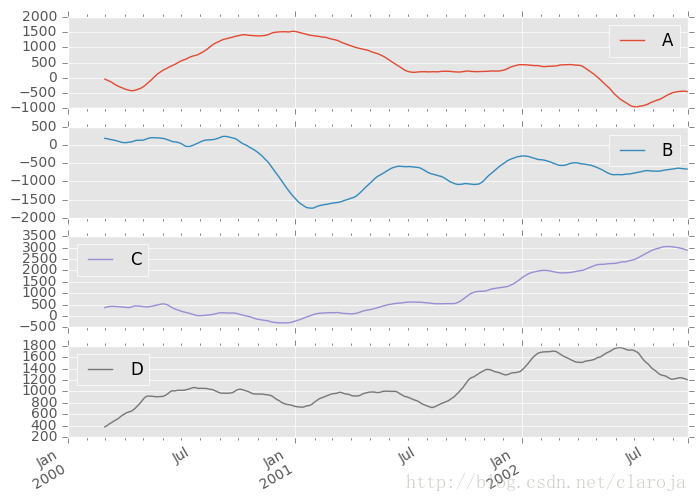
| Method | Description |
|---|---|
| count() | Number of non-null observations |
| sum() | Sum of values |
| mean() | Mean of values |
| median() | Arithmetic median of values |
| min() | Minimum |
| max() | Maximum |
| std() | Bessel-corrected sample standard deviation |
| var() | Unbiased variance |
| skew() | Sample skewness (3rd moment) |
| kurt() | Sample kurtosis (4th moment) |
| quantile() | Sample quantile (value at %) |
| apply() | Generic apply |
| cov() | Unbiased covariance (binary) |
| corr() | Correlation (binary) |
apply()方法可以應用在滾動窗口中。apply()的參數函數必須是指產生一個值,假設我們需要計算均值絕對離差:
In [49]: mad = lambda x: np.fabs(x - x.mean()).mean()In [50]: s.rolling(window=60).apply(mad).plot(style='k')
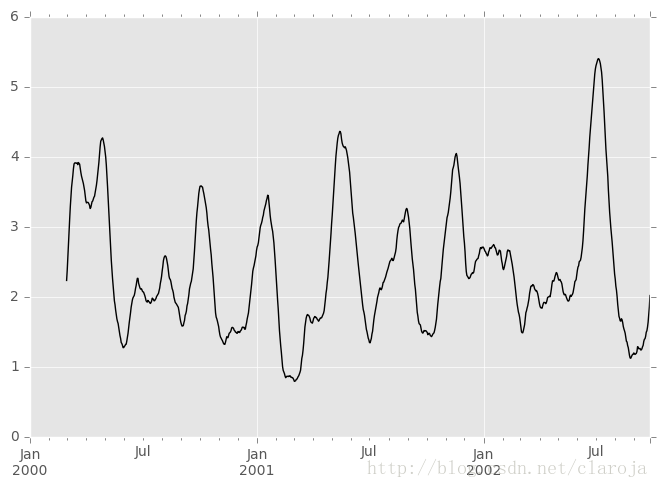
以上是“ pandas計算工具有哪些 ”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





