溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何理解R語言高級算法中的支持向量機,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
1.支持向量機原理解析
機器學習本質上就是一種對所研究問題真實模型的逼近,通常會假設一個近似模型,然后根據適當的原理將這個近似模型不斷逼近真實模型.結構風險就是指近似模型與真實模型之間的差距.
我們可以用某些方法來逼近真實模型,最直觀的想法就是使用分類器在樣本數據上的分類結果與真實結果之間的差值來表示,這個差值統計上為經驗風險Remp(W).
在過去的機器學習方法中,通常將經驗風險最小化作為努力目標,但是由于過度擬合,而使得模型無推廣能力.統計學因而引進了泛化誤差界的概念.所謂泛化誤差界是指真實風險應該由兩部分內容刻畫:一是經驗風險,代表了分類器在給定樣本上的誤差;二是置信風險,代表了我們在多大程度上可以信任分類器在未知樣本上分類的結果.統計學習的目標就是從經驗風險最小化變為了尋求經驗風險與置信風險之和最小化,即結構風險最小化(Structural Risk Minimization).支持向量機就是努力尋求最小化結構風險的算法.
我們可以把支持向量機理解為高級的線性回歸或線性判別。
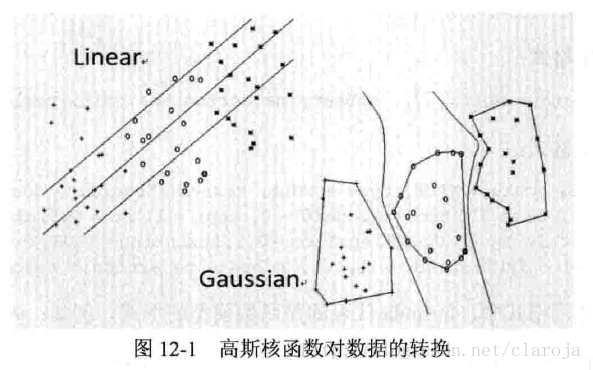
2.在R語言中的應用
支持向量機算法我們主要用到了R語言e1071包里面的svm(formula,data,type,kernel,degree,gamma,coef,nu)函數
type取值有C-classification/nu-classification/one-classification/eps-regression/nu-regression.前三種是針對字符型結果變量的分類方式,其中第三種是邏輯判別,即輸出結果是是否屬于該類別,后兩種則是針對數量型結果變量的分類方式.
kernel有四個參數,線性核函數linear/多項式核函數ploynomial/徑向基核函數(高斯函數)radial basis/神經網絡核函數sigmoid.經研究發現,識別率最高/性能最好的是高斯函數,其次是多項式函數,而最差的是神經網絡函數.高斯函數是局部函數,學習能力強,但泛化能力弱;多項式函數則是全局性函數。
3.以iris數據集為例進行支持向量機判別分析
1)應用模型并觀察結果
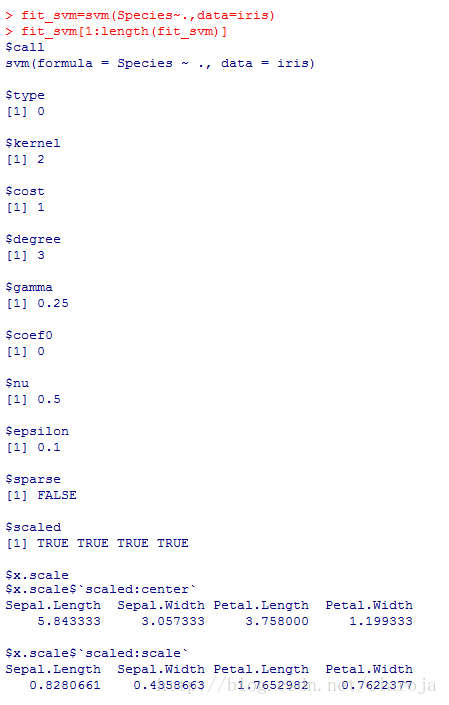
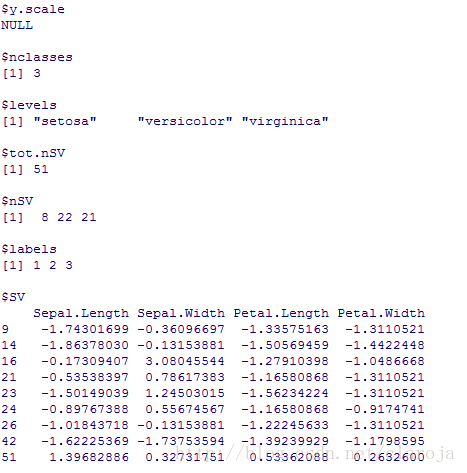
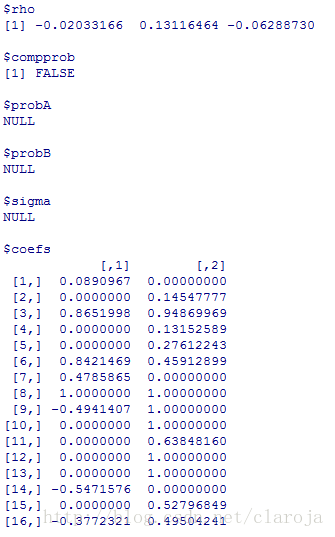
fit_svm=svm(Species~.,data=iris)
fit_svm[1:length(fit_svm)]




2)進行預測和模型評測

關于如何理解R語言高級算法中的支持向量機問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





