溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關怎樣在自定義數據集上訓練YOLOv5,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
YOLO系列的目標檢測模型隨著YOLOv5的引入變得越來越強大。我們將介紹如何訓練YOLOv5為你的定制用例識別定制對象。

非常感謝Ultralytics將此存儲庫組合在一起。我們相信,與干凈的數據管理工具相結合,任何希望在其項目中部署計算機視覺項目的開發人員都可以輕松地使用此技術。
我們使用公共血細胞檢測數據集,你可以自己導出。你也可以在自己的自定義數據上使用本教程。
為了訓練探測器,我們采取以下步驟:
安裝YOLOv5依賴項
下載自定義YOLOv5對象檢測數據
定義YOLOv5模型配置和架構
訓練一個定制的YOLOv5探測器
評估YOLOv5性能
可視化YOLOv5訓練數據
對測試圖像運行YOLOv5推斷
導出保存的YOLOv5權重以供將來推斷
就在兩個月前,我們對googlebrain引入EfficientDet感到非常興奮,并寫了一些關于EfficientDet的博客文章。我們認為這個模型可能會超越YOLO家族在實時目標探測領域的突出地位——事實證明我們錯了。
三周內,YOLOv4在Darknet框架下發布,我們還寫了更多關于分解YOLOv4研究的文章。
在寫這篇文章之前幾個小時,YOLOv5已經發布,我們發現它非常清晰明了。
YOLOv5是在Ultralytics-Pythorch框架中編寫的,使用起來非常直觀,推理速度非常快。事實上,我們和許多人經常將YOLOv3和YOLOv4 Darknet權重轉換為Ultralytics PyTorch權重,以便使用更輕的庫更快地進行推理。
YOLOv5比YOLOv4表現更好嗎?我們很快會向你介紹,你可能對YOLOv5和YOLOv4有了初步的猜測。
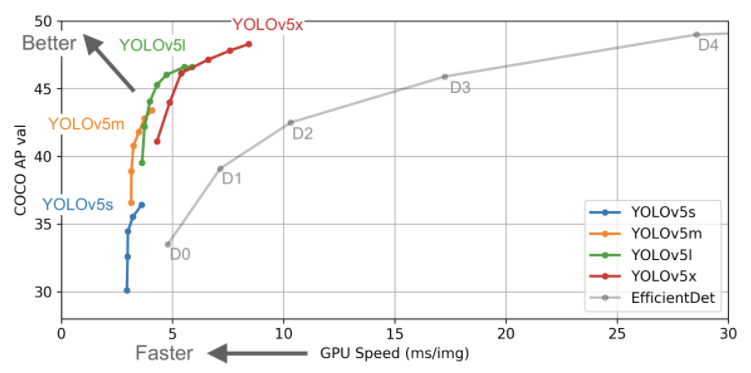 YOLOv5與EfficientDet的性能對比
YOLOv5與EfficientDet的性能對比
YOLOv4顯然沒有在YOLOv5存儲庫中進行評估。也就是說,YOLOv5更易于使用,而且它在我們最初運行的定制數據上表現非常出色。
我們建議你在 YOLOv5 Colab Notebook 中同時進行接下來的操作。
https://colab.research.google.com/drive/1gDZ2xcTOgR39tGGs-EZ6i3RTs16wmzZQ
從YOLOv5開始,我們首先克隆YOLOv5存儲庫并安裝依賴項。這將設置我們的編程環境,準備好運行對象檢測訓練和推理命令。
!git clone https://github.com/ultralytics/yolov5 # clone repo !pip install -U -r yolov5/requirements.txt # install dependencies %cd /content/yolov5
然后,我們可以看看我們的訓練環境免費提供給我們的谷歌Colab。
import torch
from IPython.display import Image # for displaying images
from utils.google_utils import gdrive_download # for downloading models/datasets
print('torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))很可能你會從谷歌Colab收到一個 Tesla P100 GPU。以下是我收到的:
torch 1.5.0+cu101 _CudaDeviceProperties(name='Tesla P100-PCIE-16GB', major=6, minor=0, total_memory=16280MB, multi_processor_count=56)
GPU可以讓我們加快訓練時間。Colab也很好,因為它預裝了torch和cuda。如果你嘗試在本地上使用本教程,可能需要執行其他步驟來設置YOLOv5。
在本教程中,我們將從Roboflow下載YOLOv5格式的自定義對象檢測數據。在本教程中,我們使用公共血細胞檢測數據集訓練YOLOv5檢測血流中的細胞。你可以使用公共血細胞數據集或上傳你自己的數據集。
Roboflow:https://roboflow.ai/
公共血細胞數據集:https://public.roboflow.ai/object-detection/bccd
如果你有未標記的圖像,則首先需要標記它們。對于免費的開源標簽工具,我們推薦 LabelImg入門 或 CVAT注釋工具入門 的指南。嘗試標記約50幅圖像再繼續本教程。要在以后提高模型的性能,你將需要添加更多標簽。
一旦你標記了數據,要將數據移動到Roboflow中,請創建一個免費帳戶,然后你可以以任何格式拖動數據集:(VOC XML、COCO JSON、TensorFlow對象檢測CSV等)。
上傳后,你可以選擇預處理和增強步驟:
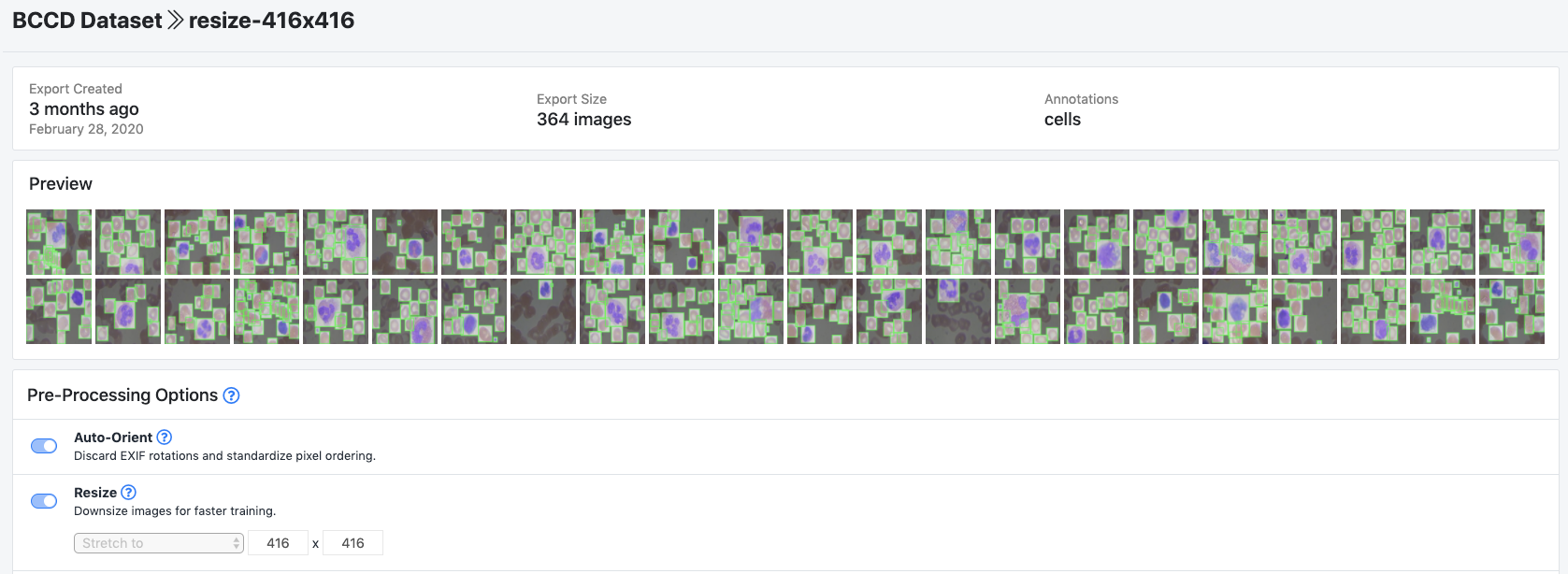 為BCCD示例數據集選擇的設置
為BCCD示例數據集選擇的設置
然后,單擊 Generate 和 Download,你將能夠選擇YOLOv5 Pythorch格式。
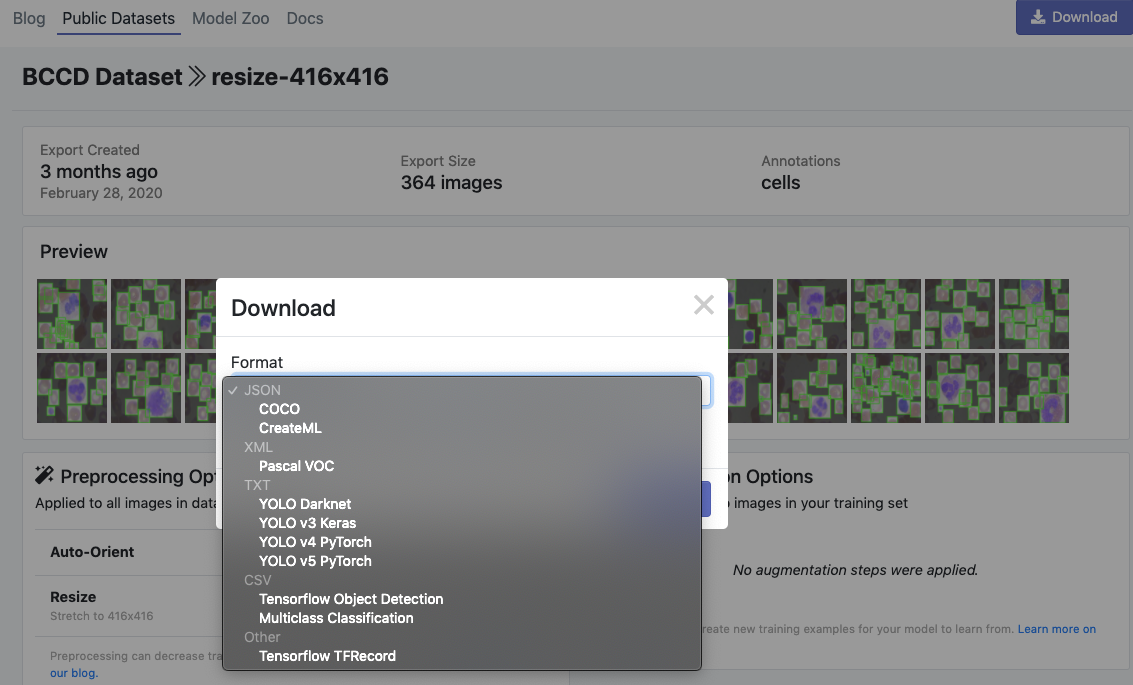 選擇“YOLO v5 Pythorch”
選擇“YOLO v5 Pythorch”
當出現提示時,一定要選擇“Show Code Snippet”。這將輸出一個下載curl腳本,這樣你就可以輕松地將數據以正確的格式移植到Colab中。
curl -L "https://public.roboflow.ai/ds/YOUR-LINK-HERE" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
正在Colab中下載…
下載YOLOv5格式的自定義對象數據集
導出將創建一個名為data.yaml的YOLOv5.yaml文件,指定YOLOv5 images文件夾、YOLOv5 labels文件夾的位置以及自定義類的信息。
接下來,我們為我們的定制對象檢測器編寫一個模型配置文件。在本教程中,我們選擇了最小、最快的YOLOv5基本模型。你可以從其他YOLOv5模型中選擇,包括:
YOLOv5s
YOLOv5m
YOLOv5l
YOLOv5x
你也可以在此步驟中編輯網絡結構,但一般不需要這樣做。以下是YOLOv5模型配置文件,我們將其命名為custom_yolov5s.yaml:
nc: 3 depth_multiple: 0.33 width_multiple: 0.50 anchors: - [10,13, 16,30, 33,23] - [30,61, 62,45, 59,119] - [116,90, 156,198, 373,326] backbone: [[-1, 1, Focus, [64, 3]], [-1, 1, Conv, [128, 3, 2]], [-1, 3, Bottleneck, [128]], [-1, 1, Conv, [256, 3, 2]], [-1, 9, BottleneckCSP, [256]], [-1, 1, Conv, [512, 3, 2]], [-1, 9, BottleneckCSP, [512]], [-1, 1, Conv, [1024, 3, 2]], [-1, 1, SPP, [1024, [5, 9, 13]]], [-1, 6, BottleneckCSP, [1024]], ] head: [[-1, 3, BottleneckCSP, [1024, False]], [-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], [-2, 1, nn.Upsample, [None, 2, "nearest"]], [[-1, 6], 1, Concat, [1]], [-1, 1, Conv, [512, 1, 1]], [-1, 3, BottleneckCSP, [512, False]], [-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], [-2, 1, nn.Upsample, [None, 2, "nearest"]], [[-1, 4], 1, Concat, [1]], [-1, 1, Conv, [256, 1, 1]], [-1, 3, BottleneckCSP, [256, False]], [-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]], [[], 1, Detect, [nc, anchors]], ]
我們的data.yaml和custom_yolov5s.yaml文件準備好了,我們準備好訓練了!
為了開始訓練,我們使用以下選項運行訓練命令:
img:定義輸入圖像大小
batch:確定批次大小
epochs:定義訓練時間段的數量。(注:通常,3000+很常見!)
data:設置yaml文件的路徑
cfg:指定我們的模型配置
weights:指定權重的自定義路徑。(注意:你可以從Ultralytics Google Drive文件夾下載權重)
name:結果名稱
nosave:只保存最后的檢查點
cache:緩存圖像以加快訓練速度
運行訓練命令:
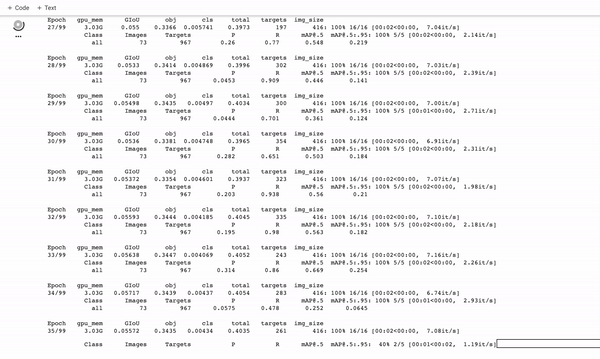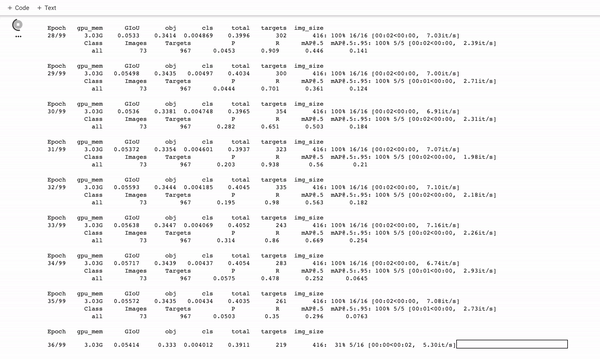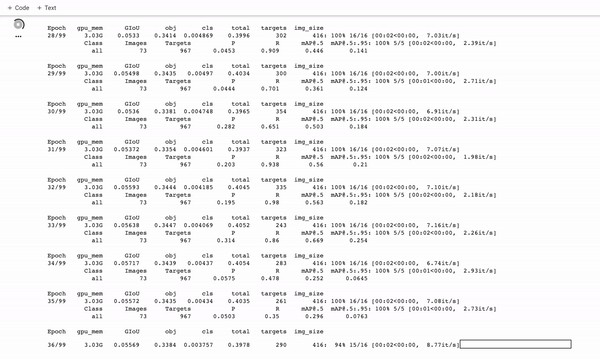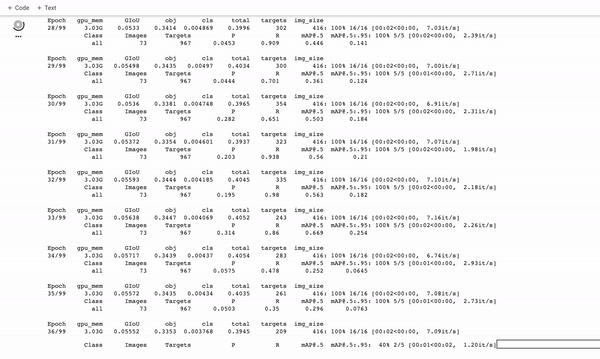
訓練定制的YOLOv5探測器。它訓練得很快!
現在我們已經完成了訓練,我們可以通過查看驗證指標來評估訓練過程的執行情況。訓練腳本將刪除tensorboard日志。我們將其可視化:
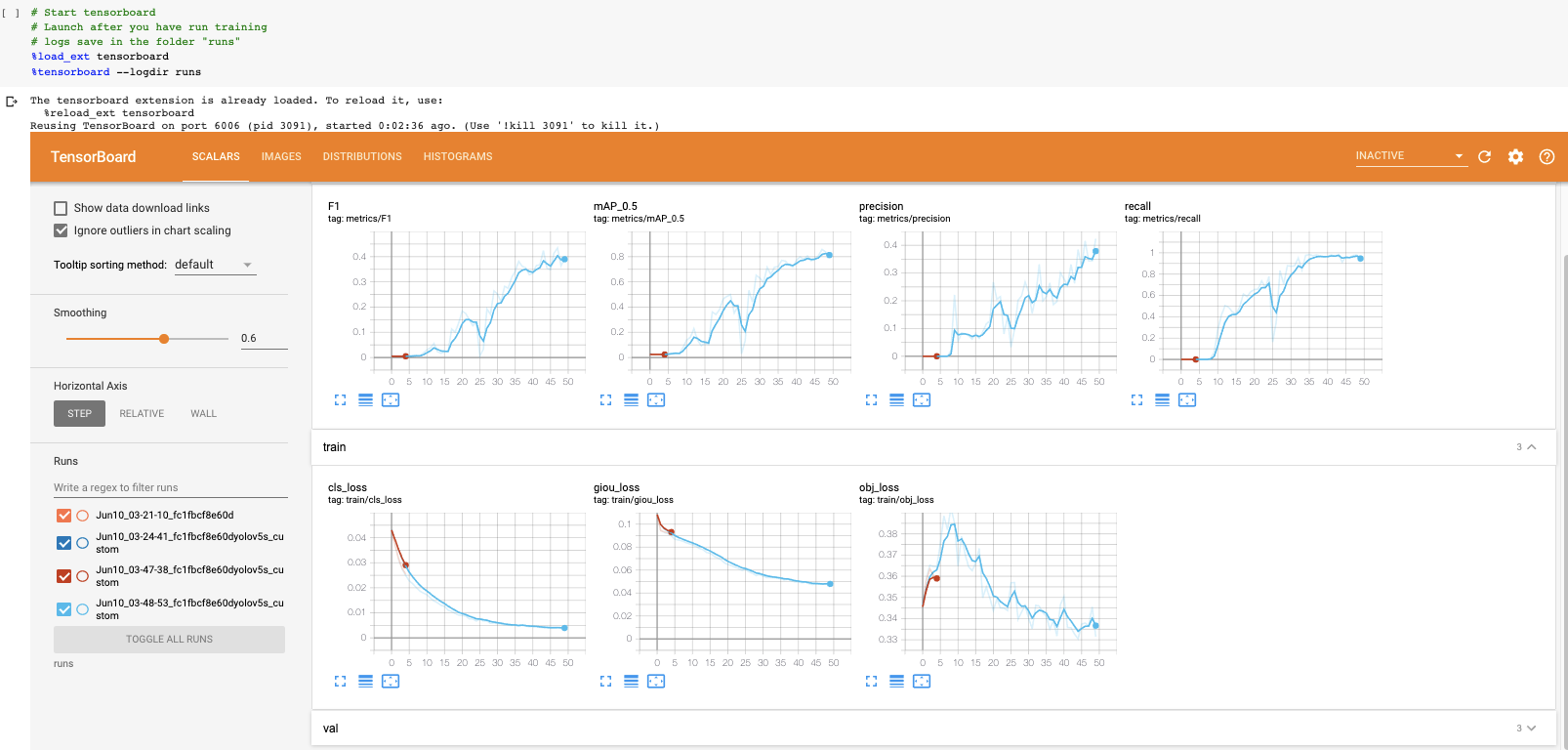
在我們的自定義數據集上可視化tensorboard結果
如果你因為一些原因不能把張量板可視化,結果也可以用utils.plot_result來繪制并保存為result.png。
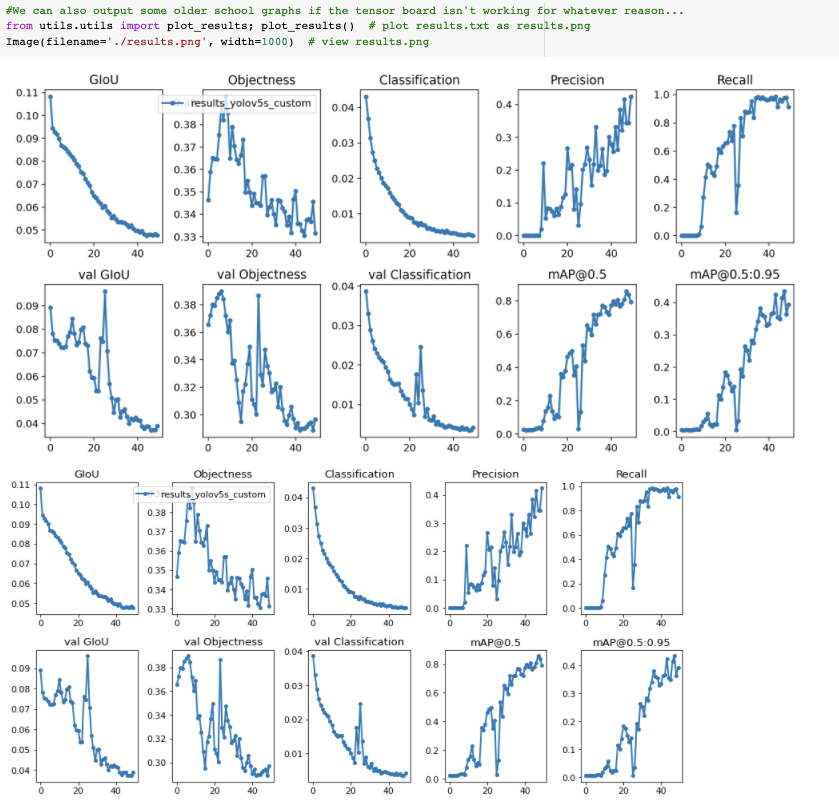
我早早就停止了訓練。你需要在驗證映射達到其最高點處獲取經過訓練的模型權重。
在訓練過程中,YOLOv5訓練管道通過增強創建成批的訓練數據。我們可以可視化訓練數據真實性和增強訓練數據。
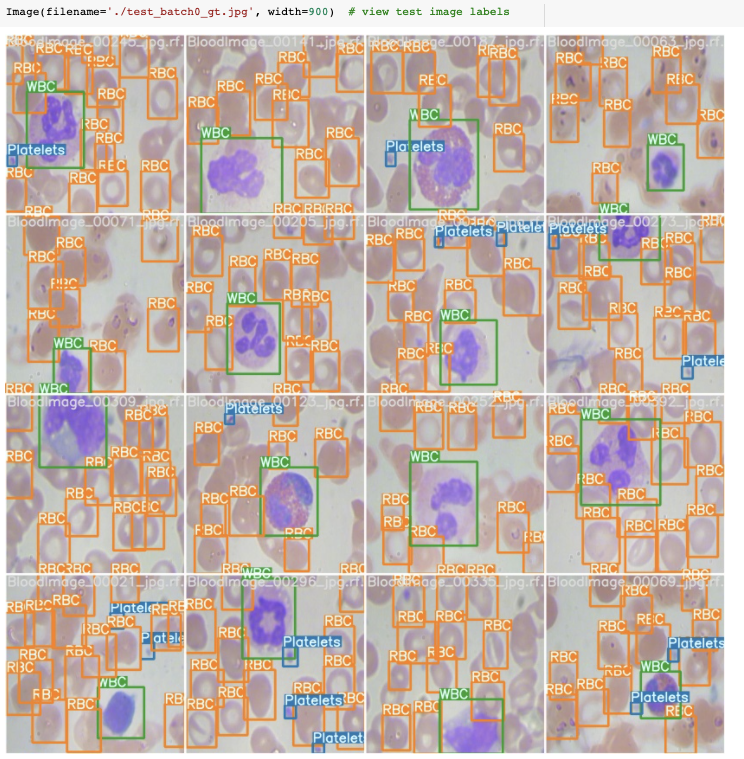
我們的真實訓練數據

我們的訓練數據采用自動YOLOv5增強
現在我們利用我們訓練過的模型,對測試圖像進行推理。訓練完成后,模型權重將保存 weights/。
對于推理,我們調用這些權重和一個指定模型置信度的conf(要求的置信度越高,預測越少)和一個推理源。源可以接受一個包含圖像、單個圖像、視頻文件以及設備的網絡攝像頭端口的目錄。對于源代碼,我將test/*jpg移到test-infer/。
!python detect.py --weights weights/last_yolov5s_custom.pt --img 416 --conf 0.4 --source ../test_infer
推理時間非常快。在我們的 Tesla P100 上,YOLOv5s 達到了每秒142幀!!
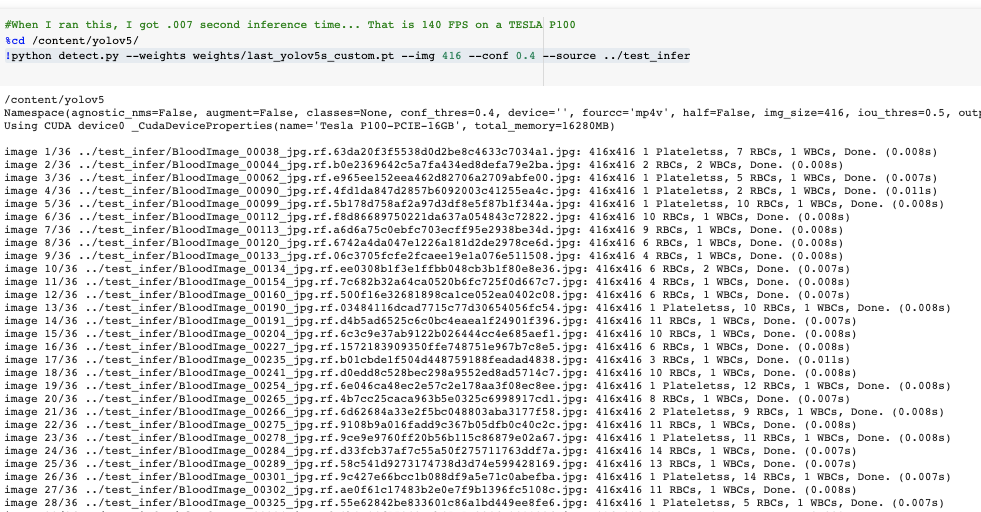
以142 FPS(0.007s/圖像)的速度推斷YOLOv5s
最后,我們在測試圖像上可視化我們的探測器推斷。
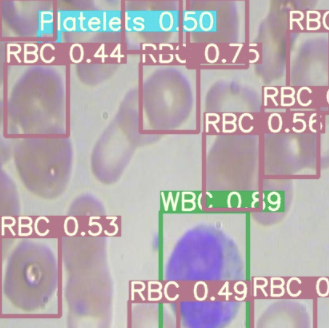
測試圖像的YOLOv5推理
既然我們定制的YOLOv5物體探測器已經過驗證,我們可能需要從Colab中取出權重,用于實時計算機視覺任務。為此,我們導入一個Google驅動器模塊并將其發送出去。
from google.colab import drive
drive.mount('/content/gdrive')
%cp /content/yolov5/weights/last_yolov5s_custom.pt /content/gdrive/My\ Drive看完上述內容,你們對怎樣在自定義數據集上訓練YOLOv5有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





