溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關HDFS如何實現讀寫,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
一、寫操作
前提:File大小為200M,block.size為128M,block分為兩塊block1和block2(塊小于block.size的不會占用一個真個block大小,而是實際的大小)。
寫操作的流程圖
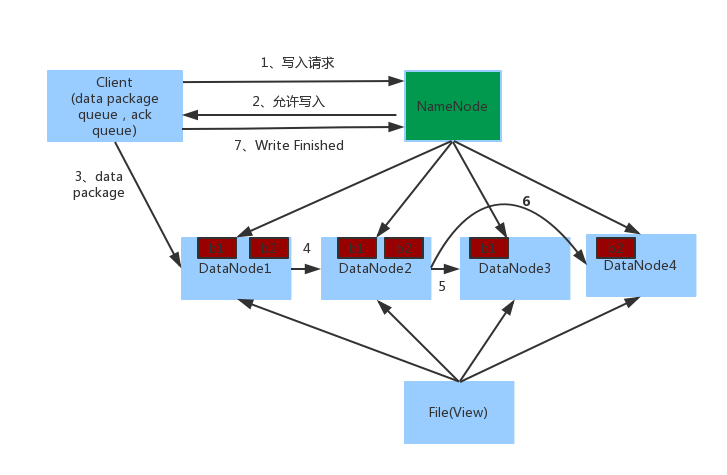
1. Client向NameNode發起寫入請求。
2. NameNode返回可用的DataNode列表。
若client為DataNode節點,那存儲block時,規則為:副本1,當前client的節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。
若client不為DataNode節點,那存儲block時,規則為:副本1,隨機選擇一個節點上;副本2,不同副本1,機架上;副本3,同副本2相同的另一個節點上;其他副本隨機挑選。
3. client向DataNode發送block1,數據首先被寫入FSDataOutputStream對象內部的Buffer中,然后數據被分割成一個個data package,每個Packet大小為64k字節,每個Packet又由一組chunk和這組chunk對應的checksum數據組成,默認chunk大小為512字節,每個checksum是對512字節數據計算的校驗和數據。
當Client寫入的字節流數據達到一個Packet的大小,這個Packet會被構建出來,然后會被放到隊列dataQueue中,接著DataStreamer線程會不斷地從dataQueue隊列中取出Packet,發送到復制Pipeline中的第一個DataNode上,并將該Packet從dataQueue隊列中移到ackQueue隊列中。ResponseProcessor線程接收從Datanode發送過來的ack,如果是一個成功的ack,表示復制Pipeline中的所有Datanode都已經接收到這個Packet,ResponseProcessor線程將packet從隊列ackQueue中刪除。
在發送過程中,如果發生錯誤,所有未完成的Packet都會從ackQueue隊列中移除掉,然后重新創建一個新的Pipeline,排除掉出錯的那些DataNode節點,接著DataStreamer線程繼續從dataQueue隊列中發送Packet。
我們從下面3個方面來描述內部流程:
創建Packet
Client寫數據時,會將字節流數據緩存到內部的緩沖區中,當長度滿足一個Chunk大小(512B)時,便會創建一個Packet對象,然后向該Packet對象中寫Chunk Checksum校驗和數據,以及實際數據塊Chunk Data,校驗和數據是基于實際數據塊計算得到的。每次滿足一個Chunk大小時,都會向Packet中寫上述數據內容,直到達到一個Packet對象大小(64K),就會將該Packet對象放入到dataQueue隊列中,等待DataStreamer線程取出并發送到DataNode節點。
發送Packet
DataStreamer線程從dataQueue隊列中取出Packet對象,放到ackQueue隊列中,然后向DataNode節點發送這個Packet對象所對應的數據。
接收ack
發送一個Packet數據包以后,會有一個用來接收ack的ResponseProcessor線程,如果收到成功的ack,則表示一個Packet發送成功。如果成功,則ResponseProcessor線程會將ackQueue隊列中對應的Packet刪除。
4. 當第一個DataNode1接收到data package并寫入成功后,會發送到DataNode2,同時接受第二個data package,以此類推。
5. 當block1發送完成以后再發送第二個block,第二個block也發送完成時DataNode向Client發送通知,client會向NameNode發送消息,說我寫完了。然后關閉close。
一、讀操作
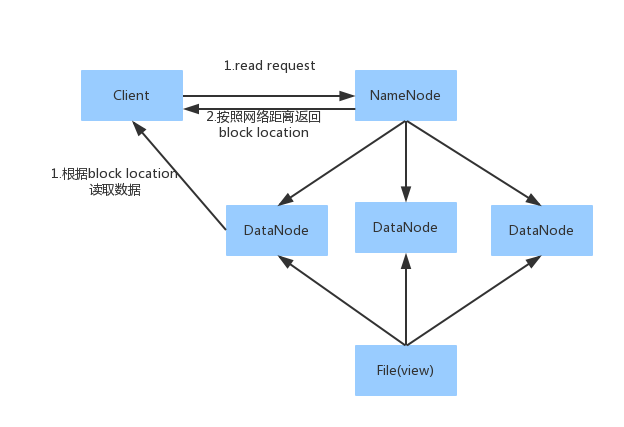
1. Client向NameNode發送讀請求。
2.NameNode根據網絡距離返回block位置列表(列表是是根據網絡距離排好順序的)。
網絡距離:
若client為DataNode節點,那讀取block時優先讀取當前節點的數據。
若client不為DataNode節點,那讀取block時,根據:同一節點上的進程--->同一個機架上的不同節點--->同一個數據中心不同機架上的節點--->不同數據中心的節點。
3. 根據block位置讀取數據。
關于“HDFS如何實現讀寫”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





