溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關CentOS 7中怎么安裝Hadoop集群,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
一、硬件環境
我使用的硬件是云創的一個minicloud設備。由三個節點(每個節點8GB內存+128GB SSD+3塊3TB SATA)和一個千兆交換機組成。
二、安裝前準備
1.在CentOS 7下新建hadoop用戶,官方推薦的是hadoop、mapreduce、yarn分別用不同的用戶安裝,這里我為了省事就全部在hadoop用戶下安裝了。
2.下載安裝包:
1)JDK:jdk-8u112-linux-x64.rpm
下載地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2)Hadoop-2.7.3:hadoop-2.7.3.tar.gz
下載地址:http://archive.apache.org/dist/hadoop/common/stable2/
3.卸載CentOS 7自帶的OpenJDK(root權限下)
1)首先查看系統已有的openjdk
rpm -qa|grep jdk
看到如下結果:
[hadoop@localhost Desktop]$ rpm -qa|grep jdk java-1.7.0-openjdk-1.7.0.111-2.6.7.2.el7_2.x86_64 java-1.8.0-openjdk-headless-1.8.0.101-3.b13.el7_2.x86_64 java-1.8.0-openjdk-1.8.0.101-3.b13.el7_2.x86_64 java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.2.el7_2.x86_64
2)卸載上述找到的openjdk包
yum -y remove java-1.7.0-openjdk-1.7.0.111-2.6.7.2.el7_2.x86_64 yum -y remove java-1.8.0-openjdk-headless-1.8.0.101-3.b13.el7_2.x86_64 yum -y remove java-1.8.0-openjdk-1.8.0.101-3.b13.el7_2.x86_64 yum -y remove java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.2.el7_2.x86_64
4.安裝Oracle JDK(root權限下)
rpm -ivh jdk-8u112-linux-x64.rpm
安裝完畢后,jdk的路徑為/usr/java/jdk1.8.0_112
接著將安裝的jdk的路徑添加至系統環境變量中:
vi /etc/profile
在文件末尾加上如下內容:
export JAVA_HOME=/usr/java/jdk1.8.0_112 export JRE_HOME=/usr/java/jdk1.8.0_112/jre export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
關閉profile文件,執行下列命令使配置生效:
source /etc/profile
此時我們就可以通過java -version命令檢查jdk路徑是否配置成功,如下所示:
[root@localhost jdk1.8.0_112]# java -version java version "1.8.0_112" Java(TM) SE Runtime Environment (build 1.8.0_112-b15) Java HotSpot(TM) 64-Bit Server VM (build 25.112-b15, mixed mode) [root@localhost jdk1.8.0_112]#
5.關閉防火墻(root權限下)
執行下述命令關閉防火墻:
systemctl stop firewalld.service systemctl disable firewalld.service
在終端效果如下:
[root@localhost Desktop]# systemctl stop firewalld.service [root@localhost Desktop]# systemctl disable firewalld.service Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. Removed symlink /etc/systemd/system/basic.target.wants/firewalld.service. [root@localhost Desktop]#
6.修改主機名并配置相關網絡(root權限下)
1)修改主機名
在master主機上
hostnamectl set-hostname Master
在slave1主機上
hostnamectl set-hostname slave1
在slave2主機上
hostnamectl set-hostname slave2
2)配置網絡
以master主機為例,演示如何配置靜態網絡及host文件。
我的機器每個節點有兩塊網卡,我配置其中一塊網卡為靜態IP作為節點內部通信使用。
vi /etc/sysconfig/network-scripts/ifcfg-enp7s0
(注:我的master機器上要配置的網卡名稱為ifcfg-enp7s0)
ifcfg-enp7s0原始內容如下:
TYPE=Ethernet BOOTPROTO=dhcp DEFROUTE=yes PEERDNS=yes PEERROUTES=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_PEERDNS=yes IPV6_PEERROUTES=yes IPV6_FAILURE_FATAL=no NAME=enp7s0 UUID=914595f1-e6f9-4c9b-856a-c4bd79ffe987 DEVICE=enp7s0 ONBOOT=no
修改為:
TYPE=Ethernet ONBOOT=yes DEVICE=enp7s0 UUID=914595f1-e6f9-4c9b-856a-c4bd79ffe987 BOOTPROTO=static IPADDR=59.71.229.189 GATEWAY=59.71.229.254 DEFROUTE=yes IPV6INIT=no IPV4_FAILURE_FATAL=yes
3)修改/etc/hosts文件
vi /etc/hosts
加入以下內容:
59.71.229.189 master 59.71.229.190 slave1 59.71.229.191 slave2
為集群中所有節點執行上述的網絡配置及hosts文件配置。
7.配置集群節點SSH免密碼登錄(hadoop權限下)
這里我為了方便,是配置的集群中任意節點能夠SSH免密碼登錄到集群其他任意節點。具體步驟如下:
1)對于每一臺機器,在hadoop用戶下執行以下指令:
ssh-keygen -t rsa -P ''
直接按Enter到底。
2)對于每臺機器,首先將自己的公鑰加到authorized_keys中,保證ssh localhost無密碼登錄:
cat id_rsa.pub >> authorized_keys
3)然后將自己的公鑰添加至其他每臺機器的authorized_keys中,在此過程中需要輸入其他機器的密碼:
master:
scp /home/hadoop/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop/.ssh/id_rsa_master.pub scp /home/hadoop/.ssh/id_rsa.pub hadoop@slave2:/home/hadoop/.ssh/id_rsa_master.pub
slave1:
scp /home/hadoop/.ssh/id_rsa.pub hadoop@master:/home/hadoop/.ssh/id_rsa_slave1.pub scp /home/hadoop/.ssh/id_rsa.pub hadoop@slave2:/home/hadoop/.ssh/id_rsa_slave1.pub
slave2:
scp /home/hadoop/.ssh/id_rsa.pub hadoop@master:/home/hadoop/.ssh/id_rsa_slave2.pub scp /home/hadoop/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop/.ssh/id_rsa_slave2.pub
4)分別進每一臺主機的/home/hadoop/.ssh/目錄下,將除本機產生的公鑰(id_rsa.pub)之外的其他公鑰使用cat命令添加至authorized_keys中。添加完畢之后使用chmod命令給authorized_keys文件設置權限,然后使用rm命令刪除所有的公鑰:
master:
cat id_rsa_slave1.pub >> authorized_keys cat id_rsa_slave2.pub >> authorized_keys chmod 600 authorized_keys rm id_rsa*.pub
slave1:
cat id_rsa_master.pub >> authorized_keys cat id_rsa_slave2.pub >> authorized_keys chmod 600 authorized_keys rm id_rsa*.pub
slave2:
cat id_rsa_master.pub >> authorized_keys cat id_rsa_slave1.pub >> authorized_keys chmod 600 authorized_keys rm id_rsa*.pub
完成上述步驟,就可以實現從任意一臺機器通過ssh命令免密碼登錄任意一臺其他機器了。
三、安裝和配置Hadoop(下述步驟在hadoop用戶下執行)
1.將hadoop-2.7.3.tar.gz文件解壓至/home/hadoop/目錄下(在本文檔中,文件所在地是hadoop賬戶下桌面上)可通過下述命令先解壓至文件所在地:
tar -zxvf hadoop-2.7.3.tar.gz
然后將解壓的文件hadoop-2.7.3所有內容拷貝至/home/hadoop目錄下,拷貝之后刪除文件所在地的hadoop文件夾:
cp -r /home/hadoop/Desktop/hadoop-2.7.3 /home/hadoop/
2.具體配置過程:
1)在master上,首先/home/hadoop/目錄下創建以下目錄:
mkdir -p /home/hadoop/hadoopdir/name mkdir -p /home/hadoop/hadoopdir/data mkdir -p /home/hadoop/hadoopdir/temp mkdir -p /home/hadoop/hadoopdir/logs mkdir -p /home/hadoop/hadoopdir/pids
2)然后通過scp命令將hadoopdir目錄復制至其他節點:
scp -r /home/hadoop/hadoopdir hadoop@slave1:/home/hadoop/ scp -r /home/hadoop/hadoopdir hadoop@slave2:/home/hadoop/
3)進入/home/hadoop/hadoop-2.7.3/etc/hadoop目錄下,修改以下文件:
hadoop-env.sh:
export JAVA_HOME=/usr/java/jdk1.8.0_112 export HADOOP_LOG_DIR=/home/hadoop/hadoopdir/logs export HADOOP_PID_DIR=/home/hadoop/hadoopdir/pids
mapred-env.sh:
export JAVA_HOME=/usr/java/jdk1.8.0_112 export HADOOP_MAPRED_LOG_DIR=/home/hadoop/hadoopdir/logs export HADOOP_MAPRED_PID_DIR=/home/hadoop/hadoopdir/pids
yarn-env.sh:
export JAVA_HOME=/usr/java/jdk1.8.0_112 YARN_LOG_DIR=/home/hadoop/hadoopdir/logs
Slaves文件:
#localhost slave1 slave2
(注意:如果slaves文件里面不注釋localhost,意思是把本機也作為一個DataNode節點)
core-site.xml:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:///home/hadoop/hadoopdir/temp</value> </property> </configuration>
hdfs-site.xml:
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadoop/hadoopdir/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadoop/hadoopdir/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.blocksize</name> <value>64m</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml vi mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <final>true</final> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>master:50030</value> </property> <property> <name>mapred.job.tracker</name> <value>http://master:9001</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
yarn-site.xml:
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property>
4)master機器下,將/home/hadoop/hadoop-2.7.3目錄里面所有內容拷貝至其他節點
scp -r /home/hadoop/hadoop-2.7.3 hadoop@slave1:/home/hadoop/ scp -r /home/hadoop/hadoop-2.7.3 hadoop@slave2:/home/hadoop/
5)進入/home/hadoop/hadoop-2.7.3/bin目錄,格式化文件系統:
./hdfs namenode -format
格式化文件系統會產生一系列的終端輸出,在輸出最后幾行看到STATUS=0表示格式化成功,如果格式化失敗請詳細查看日志確定錯誤原因。
6)進入/home/hadoop/hadoop-2.7.3/sbin目錄:
./start-dfs.sh ./start-yarn.sh
上述命令就啟動了hdfs和yarn。hadoop集群就跑起來了,如果要關閉,在sbin目錄下執行以下命令:
./stop-yarn.sh ./stop-dfs.sh
7)HDFS啟動示例
執行start-dfs.sh之后,可以在master:50070網頁上看到如下結果,可以看到集群信息和datanode相關信息:
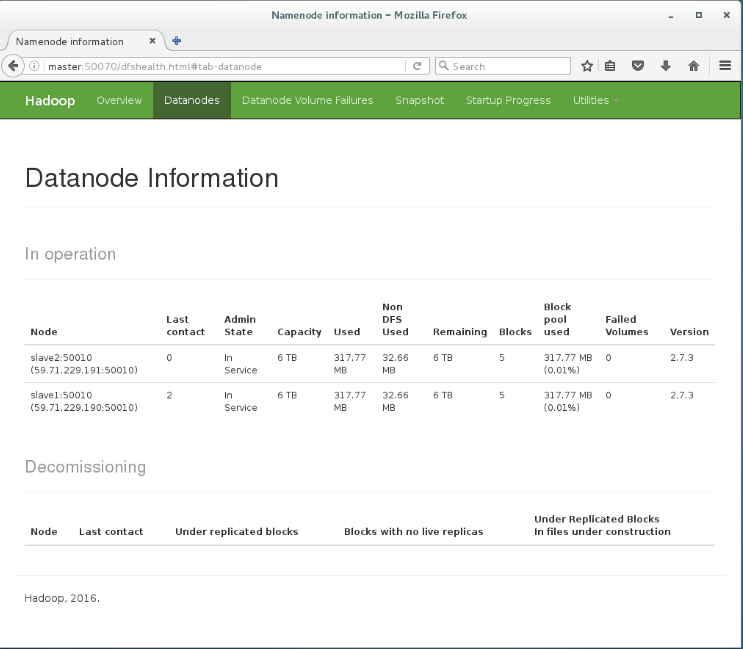
執行start-yarn.sh之后,可以在master:8088網頁上看到如下結果,可以看到集群信息相關信息:
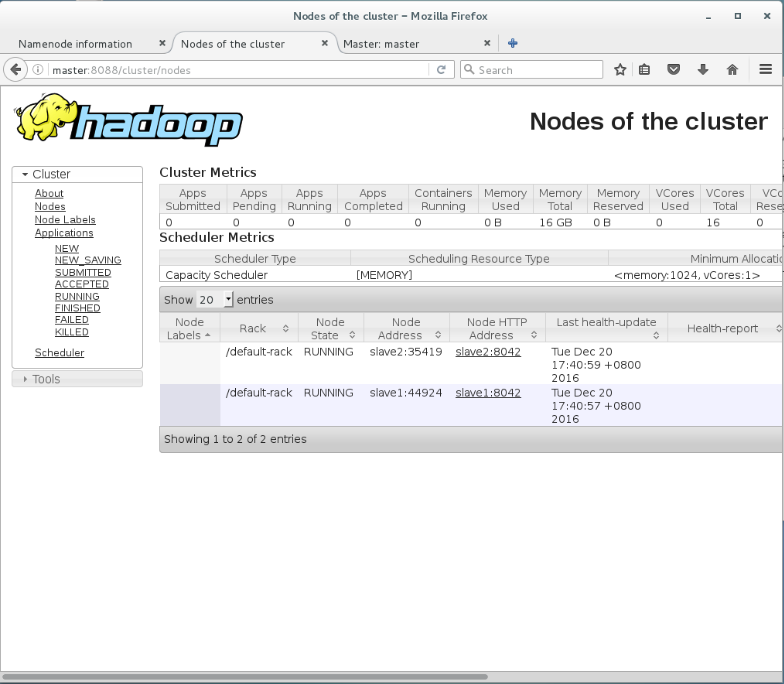
看完上述內容,你們對CentOS 7中怎么安裝Hadoop集群有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





