溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關錯誤狀況下怎么保證ceph IO的一致性,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
最近研究了在出現錯誤的狀況下,ceph IO 的一致性如何保證。代碼基于hammer0.94.5版本。 構建一個集群,包括三個OSD, osd.0 osd.1 osd.2。
從客戶端發送IO寫操作A,osd.0 是primary, osd1/2是replica. 假設osd.2此時由于網絡或者硬盤故障,或者軟件bug掛了。 此時osd0 自己完成了本地寫,收到了osd.1的副本寫ack,還在等待osd.2的副本寫ack. 在最長等待osd_heartbeat_grace,默認是20秒后,利用心跳機制,會向monitor匯報此osd掛掉。此時集群會進入peering,在peering的時候,受影響的pg,io 會被block住。這個時候詳細來看作為primay的osd.0 如何處理寫操作A。 在peering之前, osd0 會調用void ReplicatedPG::on_change(), 進一步調用apply_and_flush_repops()

apply_and_flush_repops()會將操作A requeue到op_wq里去。

等待pg peering完成后,A操作的對象所屬的pg變成active狀態, IO繼續, do_op會繼續處理IO隊列,包括requeue的A操作。
do_op 會查詢pglog,發現A操作其實已經落盤,是個dup的操作,可直接返回client.
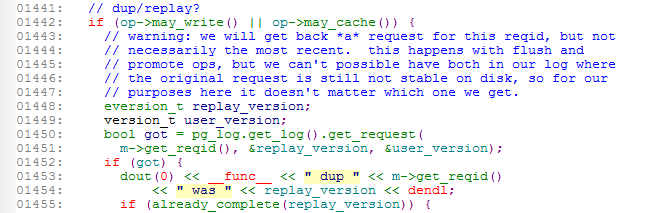
對于兩個osd ,如osd.1/osd.2都掛的情況,primary還是會requeue A操作,但假如pg min_size是2, 這個時候由于只有primay osd在線,小于min_size。
所以等peering完成,IO也會被block住,等待數據恢復至min_size以上,IO 才會繼續。
同樣的,如果掛的是primary osd.0, 分兩種情況,一種是osd.0先掛,然后client 發送A操作,client端會等一會兒,等到peering完成,client拿到更新的osdmap后,重發請求,納悶剩下的IO處理跟正常情況一樣了。
第二種是client 已經將請求發送到primary osd.0, osd.0也把副本寫操作發送到了osd.1 和osd.2上,然后osd.0掛了。 同樣等到心跳檢測到osd.0掛的情況,然后peering. osd.1也會有equeue的動作,等待peering完成后,假設osd.1變成了primary, 那接下來的邏輯跟之前primary osd.0的動作一樣了。
關于“錯誤狀況下怎么保證ceph IO的一致性”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





