溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Storm的優點有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Storm和hadoop的區別

數據來源:HADOOP是HDFS上某個文件夾下的可能是成TB的數據,STORM是實時新增的某一筆數據
處理過程:HADOOP是分MAP階段到REDUCE階段,STORM是由用戶定義處理流程,流程中可以包含多個步驟,每個步驟可以是數據源(SPOUT)或處理邏輯(BOLT)
是否結束:HADOOP最后是要結束的,STORM是沒有結束狀態,到最后一步時,就停在那,直到有新數據進入時再從頭開始
處理速度:HADOOP是以處理HDFS上大量數據為目的,速度慢,STORM是只要處理新增的某一筆數據即可可以做到很快。
適用場景:HADOOP是在要處理一批數據時用的,不講究時效性,要處理就提交一個JOB,STORM是要處理某一新增數據時用的,要講時效性
與MQ對比:HADOOP沒有對比性,STORM可以看作是有N個步驟,每個步驟處理完就向下一個MQ發送消息,監聽這個MQ的消費者繼續處理
好的編程模型讓開發者專注于業務邏輯;不好的編程模型讓開發者把時間花費在通信,處理異常等瑣事上.
編程模型例子:
用hadoop的MapReduce和MPI做一個對比,在hadoop的MapReduce里面呢,它的編程模型里面呢,map和reduce,你只用去寫map和reduce函數,以及一些簡單的驅動,程序就能跑起來,你不用關心map和數據是怎么切分的,map和reduce是怎么傳輸的,reduce的數據是怎么寫到hadoop的HDFS里面的,這些你都不用關心,看起來寫mapreduce就是單機的代碼,沒有什么分布式的特點在里面啊,但是它運行的分布式框架來幫你做上述這些東西。
反過來我們看寫MPI的程序就完全不一樣,寫MPI的時候你就會很明顯的感覺到你在寫一個并行分布式程序,你需要在很多地方顯式的去調數據傳輸的接口,你還要顯式的去調一些數據同步的接口,這樣才能把MPI程序顯式的給RUN起來,這就是編程模型不同導致的不同的開發體驗,其實這不僅僅是開發容易不容易的問題,更主要的是一個開發效率的問題,其實更簡單的程序更能寫出健壯的程序,寫mapreduce程序是很簡單的,但是要寫出一個穩定靠譜的MPI程序就難一些
架構
Nimbus
Supervisor
Worker
編程模型:
DAG
Spout
Bolt
數據傳輸:
Zmq
Zmq也是開源的消息傳遞的框架,雖然叫mq,但它并不是一個message queue,而是一個封裝的比較好的
Netty
netty是NIO的網絡框架,效率比較高。之所以有netty是storm在apache之后呢,zmq的license和storm的license不兼容的,bolt處理完消息后會告訴Spout。
高可用性
異常處理
消息可靠性保證機制
可維護性:
Storm有個UI可以看跑在上面的程序監控
實時請求應答服務(同步),
實時請求應答服務(同步),往往不是一個很簡單的操作,而且大量的操作,用DAG模型來提高請求處理速度
DRPC
實時請求處理
例子:發送圖片,或者圖片地址,進行圖片特征的提取

這里DRPC Server的好處是什么呢?這樣看起來就像是一個Server,經過Spout,然后經過Bolt,不是更麻煩了嗎?DRPC Server其實適用于分布式,可以應用分布式處理這個單個請求,來加速處理的過程。
DRPCClientclient = new DRPCClient("drpc-host", 3772);
String result = client.execute("reach","http://twitter.com");
//服務端由四部分組成:包括一個DRPC Server,一個DPRC Spout,一個Topology和一個ReturnResult。
流式處理(異步)--- 不是說不快,而是不是等待結果
逐條處理
例子:ETL,把關心的數據提取,標準格式入庫,它的特點是我把數據給你了,不用再返回給我,這個是異步的
分析統計
例子:日志PV,UV統計,訪問熱點統計,這類數據之間是有關聯的,比如按某些字段做聚合,加和,平均等等

最后寫到Redis,Hbase,MySQL,或者其他的MQ里面去給其他的系統去消費。
/**
* ShuffleGrouping("spout")就是從spout來訂閱數據,fieldGrouping("split", new Fields("word"))
* 實際上就是一個hash,同一個詞有相同的hash,然后就會被hash到同一個WordCount的bolt里面,然后就
* 可以進行計數。接下來兩行呢是配置文件,然后是配置3個worker,接下來是通過Submitter提交Topology
* 到Storm集群里面去。程序會編譯打包,這段代碼來自storm里面的starter的一段代碼,這個代碼怎么真正
* 運行起來呢,就用storm jar 然后jar包的名,然后就是類的名字,和topology的名字,因為這里有個args[0]。
* 這段代碼很簡單,首先呢,第一部分構造了一個DAG的有向無環圖,然后生成配置,提交到Storm集群去。
* */
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setDebug(true);
if(args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
}
}
###Linux: storm jar storm-starter-0.9.4.jar storm.starter.WordCountTopology wordcount
Cluster Summary(整個集群的)

一個slot就是一個worker,一個worker里面是一個jvm,一個worker里面呢可以有多個executor,每一個executor就是執行線程,每一個executor上面執行一個或多個Task,一般來說默認是一個task。
Topology Summary(每個應用程序的)
一個應用程序就是一個Topology,它有名字,還有ID,然后有個狀態,ACTIVE就是正在運行,KILLED就是已經被殺掉了。
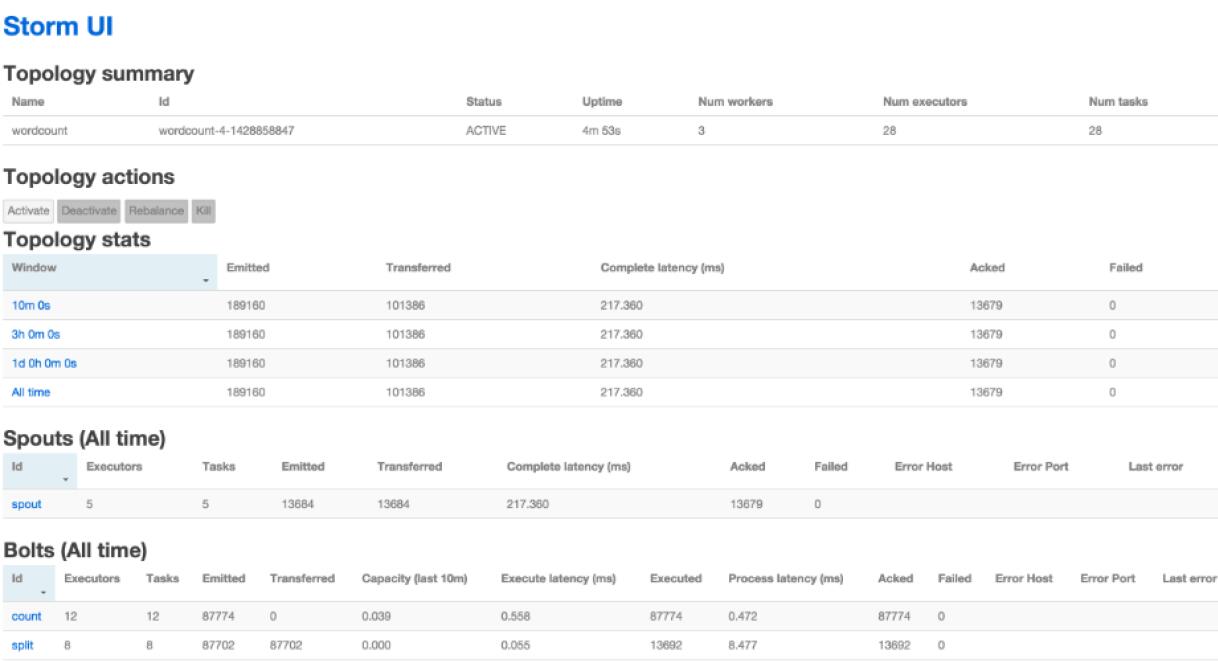
Topology actions就是可以對Topology采取一些操作,Deactivate就是暫停,Rebalance就是重新做一下balance,然后kill就是殺掉這個應用。
這個應用運行的到底怎么樣呢,在Topology stats里面有個整體的統計,有10分鐘,3小時,1天,還有所有的統計,這里面比較關鍵的呢,是Complete latency,它的意思就是一條數據從發出去到處理完花了多長時間,第二個比較關鍵的呢就是ACK,這個反映的是吞吐,前面的Complete latency反映的延遲。
在Spouts的統計信息里面呢,一個是spout的名字,和代碼里面是對應的,第二個呢是這個spout它有多少個executor,然后呢它有多少個task,然后呢是它在一定時間內往外emit出多少數據,真正tranfer傳輸了多少數據,然后它latency延遲是多少,然后ACK處理了多少數據,后面還有錯誤的信息。
Bolt也類似,通過這個UI頁面可以實時觀看這些統計信息,是非常有用的,可以知道哪個環節比較慢,哪些地方有沒有什么瓶頸了,有瓶頸了是不是加一個并發來解決問題。
Spout中這里最關鍵的是一個nextTuple(),它是從外部取數據的源頭,可以從DPRC取數據,可以從MQ,比如Kafka中取數據,然后給后面的bolt進行處理,然后這里wordcount沒有那么復雜,就自己隨機的生成了數據。
_collector.emit(new Values(sentence), new Object());
這個代碼后面new Object()等于是隨機的生成了一個message的ID,這個ID有什么用,后面會講到,實際上它是消息可靠性保障的一部分。有了這個ID呢Storm就可以幫你去跟蹤這條消息到底有沒有被處理完,如果處理完了呢?
如果處理完了,它就是調用一個ack告訴spout,我已經處理完了,這里ack方法里面僅僅是把id打印出來,因為這里id沒有什么意義,僅僅是為了展示,相反,如果在一定時間內沒有處理完,會調用fail告訴說消息處理失敗了。
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package storm.starter.spout;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
import java.util.Map;
import java.util.Random;
public class RandomSentenceSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
Random _rand;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
_rand = new Random();
}
@Override
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{ "the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature" };
String sentence = sentences[_rand.nextInt(sentences.length)];
_collector.emit(new Values(sentence), new Object());
}
@Override
public void ack(Object id) {
System.out.println(id);
}
@Override
public void fail(Object id) {
System.out.println(id);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map<String, Object> getComponentConfiguration(){
return null;
}
}
public static class WordCount1 extends BaseBasicBolt{
Map<String, Integer> counts = new HashMap<String, Integer>();
@Override
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
String word = tuple.getStringByField("word");
Integer count = counts.get(word);
if(count==null){
count=0;
}
count++;
counts.put(word,count);
System.out.println("word++"+word+"========="+count);
basicOutputCollector.emit(new Values(word,count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word","count"));
}
}
對于wordcount的示例,它是有兩個blot,一個bolt是分詞,一個bolt是計數,這里SplitSentence是展示它支持多語言的開發,其實這里代碼調用的是python的splitsentence.py,使用的是ShellBolt這個組件
那wordcount這個bolt是用java實現的,它的實現核心是亮點,一點是有execute這樣一個函數,第二個是declareOutputFields這個函數,這兩個函數的作用其實是很什么呢?最核心的其實是execute,execute的作用呢就是拿到輸入的數據Tuple,然后再emit數據出去。
以上就是在storm里面一個最簡單的wordcount的例子,它的主函數的代碼,它的提交的命令行代碼,Spout是什么樣的,Bolt是什么樣的,提交到Storm集群之后是一個什么樣的運行狀況,在WebUI上面看到哪些核心的信息,這個在后面的應用開發里面都會大量的運用到。
Storm與其他技術對比
Storm:進程、線程常駐運行,數據不進入磁盤,網絡傳遞。
MapReduce:TB、PB級別數據設計的,一次的批處理作業。
Storm:純流式處理,處理數據單元是一個個Tuple。另外Storm專門為流式處理設計,它的數據傳輸模式更為簡單,很多地方也更為高效。并不是不能做批處理,它也可以來做微批處理,來提高吞吐。
Spark Streaming:微批處理,一個批處理怎么做流式處理呢,它基于內存和DAG可以把處理任務做的很快,把RDD做的很小來用小的批處理來接近流式處理。
和其它如MPI系統相比
通過對比,更能了解Storm的一些特點:
首先,相對于Queue+Worker來說,它是一個通用的分布式系統,分布式系統的一些細節可以屏蔽掉,比如說水平擴展,容錯,上層應用只需要關注自己的業務邏輯就可以了,這一點對應應用開發人員來說是非常重要的,不然的話業務邏輯會被底層的一些細節所打亂。
另外一個,Storm作為一個純的流式處理系統,和mapreduce的差異相當大,一種稱為流式處理,一種稱為批處理,Storm是一個常駐運行的,它的消息收發是很高效的。
和spark這種微批處理系統相比呢,Storm可以處理單條單條的消息。
總的來說呢,Storm在設計之初呢,就被定義為分布式的流式處理系統,所以說大部分的流式計算需求都可以通過Storm很好的滿足,Storm目前在穩定性方面也做的相當不錯,對于實時流式計算來說是個非常不錯的選擇
“Storm的優點有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





