溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Kubernetes1.3有哪些新功能”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
1 Init container
Init container 是1.3 中的 alpha feature,目的是支持一類需要在啟動 Pod“普通容器”前,先進行 Pod 初始化的應用。執行該初始化任務的容器被成為“初始化容器”(init container)。例如,在啟動應用之前,初始化數據庫,或等待數據庫啟動等。下圖是一個包含 init container 的 Pod:
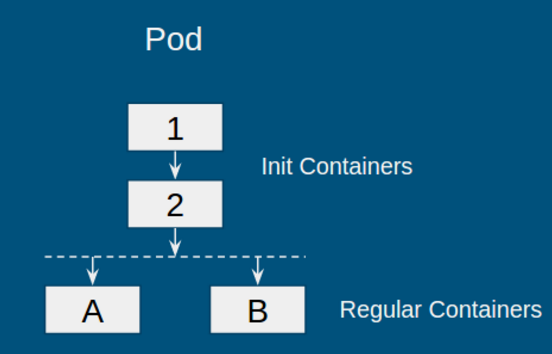
對于此類 Pod,kubernetes 的運行策略如下:
初始化容器按順序依次執行,即圖中容器 1->2
若其中某一個初始化容器運行失敗,則整個 Pod 失敗
當所有初始化容器運行成功,啟動普通容器,即圖中容器 A 和 B
在 alpha 版本中使用 init container 需要用 annotation,下圖是來自 k8s 的一個例子(略有裁剪):


可以看到,我們在啟動 nginx 普通容器之前,先用 init container 來獲取 index.html,之后訪問 nginx 就會直接返回該文件。當 init container 功能穩定后,k8s 會直接在 pod.spec 內加上 init Containers 字段,如下所示:

init container 看起來是一個小功能,但是在實現上還是需要考慮不少問題,比如幾個比較重要的點:
資源問題:當調度存在 init container 的 Pod 時,應該怎樣計算所需要的資源?兩個極端情況:如果對 init container 和 regular container 所需要的資源求和,那么當 init container 成功初始化 Pod 之后,就不會再使用所請求的資源,而系統認為在使用,會造成浪費;反之,不計算 init container 的資源又會導致系統不穩定(init container 所使用的資源未被算入調度資源內)。目前的方法是取折中:由于初始化容器和普通容器不會同時運行,因此 Pod 的資源請求是兩者中的最大值。對于初始化容器,由于他們是依次運行,因此選擇其中的最大值;對于普通容器,由于是同時運行,選擇容器資源的和。
Pod Status: 目前,Pod 有 Pending, Running, Terminating 等狀態。對于有初始化容器的 Pod,如果仍然使用 Pending 狀態,則很難區分 Pod 當前在運行初始化容器還是普通容器。因此,理想情況下,我們需要增加一個類似于 Initializing 的狀態。在 alpha 版本中暫時還未添加。
健康檢查及可用性檢查:有了 init container 之后,我們該如何檢查容器的健康狀態?alpha 版本將兩個檢查都關閉了,但 init container 是會在 node 上實實在在運行的容器,理論上是需要進行檢查的。對于可用性檢查,關閉掉是一個可行的辦法,因為 init container 的可用性其實就是當它運行結束的時候。對于健康檢查,node 需要知道某個 Pod 是否處在初始化階段;如果處在初始化階段,那么 node 就可以對 init container 進行健康檢查。因此,kubernetes 很有可能在添加類似 Initializing 的 Pod 狀態之后,開啟 init container 的健康檢查。
圍繞 init container 的問題還有很多,比如 QoS,Pod 的更新等等,其中不少都是有待解決的問題,這里就不一一展開了 :)
2 PetSet
PetSet 應該算是社區期待已久的功能,其目的是支持有狀態和集群化的應用,目前也是 alpha 階段。PetSet 的應用場景很多,包括類似 zookeeper、etcd 之類的 quorum leader election 應用,類似 Cassandra 的 Decentralized quorum 等。PetSet 中,每個 Pod 都有唯一的身份,分別包括:名字,網絡和存儲;并由新的組件 PetSet Controller 負責創建和維護。下面依次看一看 kubernetes 是如何維護 Pod 的唯一身份。
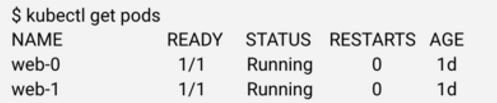
名字比較容易理解,當我們創建一個 RC 之后,kubernetes 會創建指定副本數量的 Pod,當使用 kubectl 獲取 Pod 信息時,我們會得到如下信息:

 其中,5 個字符的后綴為 kubernetes 自動生成。當 Pod 重啟,我們會得到不同的名字。對于 PetSet 來講,Pod 重啟必須保證名字不變。因此,PetSet 控制器會維護一個 identityMap,每一個 PetSet 中的每個 Pod 都會有一個唯一名字,當 Pod 重啟,PetSet 控制器可以感知到是哪個 Pod,然后通知 API server 創建新的同名 Pod。目前的感知方法很簡單,PetSet 控制器維護的 identityMap 將 Pod 從 0 開始進行編號,然后同步的過程就像報數一樣,哪個編號不在就重啟哪個編號。
其中,5 個字符的后綴為 kubernetes 自動生成。當 Pod 重啟,我們會得到不同的名字。對于 PetSet 來講,Pod 重啟必須保證名字不變。因此,PetSet 控制器會維護一個 identityMap,每一個 PetSet 中的每個 Pod 都會有一個唯一名字,當 Pod 重啟,PetSet 控制器可以感知到是哪個 Pod,然后通知 API server 創建新的同名 Pod。目前的感知方法很簡單,PetSet 控制器維護的 identityMap 將 Pod 從 0 開始進行編號,然后同步的過程就像報數一樣,哪個編號不在就重啟哪個編號。
此外,該編號還有另外一個作用,PetSet 控制器通過編號來確保 Pod 啟動順序,只有 0 號 Pod 啟動之后,才能啟動 1 號 Pod。
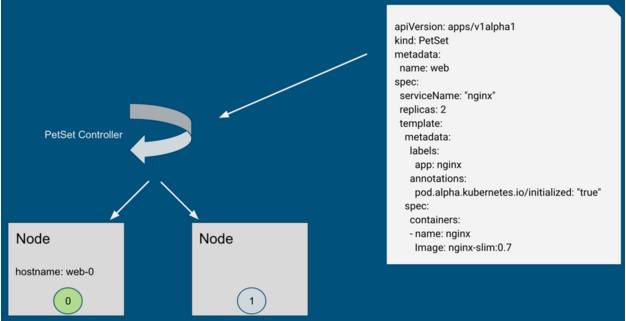
網絡身份的維護主要通過穩定的 hostname 和 domain name 來維護,他們通過 PetSet 的配置文件指定。例如,下圖是一個 PetSet 的 Yaml 文件(有裁剪),其中 metadata.name 指定了 Pod 的 hostname 前綴(后綴即前面提到的從 0 開始的索引),spec.ServiceName 指定了 domain name。


通過上面的 Yaml 文件創建出來兩個 Pod:web-0 和 web-1。其完整的域名為 web-0.nginx.default.svc.cluster.local,其中 web-0 為 hostname,nginx 為 Yaml 中指定的 domain name,剩下的部分與普通 service 無異。當創建請求被下發到節點上時,kubelet 會通過 container runtime 設置 UTS namespace,如下圖所示(省略了部分組件如 apiserver)。
 此時,hostname 已經在容器層面設置完成,剩下還需要為 hostname 增加集群層面的解析,以及添加 domain name 的解析,這部分工作理所當然就交給了 kube dns。了解 Kubernetes 的讀者應該知道,要添加解析,我們需要創建 service;同理,這里也需要為 PetSet 創建 service。不同的是,普通的 service 默認后端的 Pod 是可替換的,并采用諸如 roundrobin,client ip 的方式選擇后端的 Pod,這里,由于每個 Pod 都是一個 Pet,我們需要定位每一個 Pod,因此,我們創建的 service 必須要能滿足這個要求。在 PetSet 中,利用了 kubernetes headless service。Headless service 不會分配 cluster IP 來 load balance 后端的 Pod,但會在集群 DNS 服務器中添加記錄:創建者需要自己去利用這些記錄。下圖是我們需要創建的 headless service,注意其中的 clusterIP 被設置為 None,表明這是一個 headless service。
此時,hostname 已經在容器層面設置完成,剩下還需要為 hostname 增加集群層面的解析,以及添加 domain name 的解析,這部分工作理所當然就交給了 kube dns。了解 Kubernetes 的讀者應該知道,要添加解析,我們需要創建 service;同理,這里也需要為 PetSet 創建 service。不同的是,普通的 service 默認后端的 Pod 是可替換的,并采用諸如 roundrobin,client ip 的方式選擇后端的 Pod,這里,由于每個 Pod 都是一個 Pet,我們需要定位每一個 Pod,因此,我們創建的 service 必須要能滿足這個要求。在 PetSet 中,利用了 kubernetes headless service。Headless service 不會分配 cluster IP 來 load balance 后端的 Pod,但會在集群 DNS 服務器中添加記錄:創建者需要自己去利用這些記錄。下圖是我們需要創建的 headless service,注意其中的 clusterIP 被設置為 None,表明這是一個 headless service。

Kube dns 進行一番處理之后,會生成如下的記錄:

 可以看到,訪問 web-0.nginx.default.svc.cluster.local 會返回 pod IP,訪問 nginx.default.svc.cluster.local 會返回所有 Pet 中的 pods IP。一個常見的方式是通過訪問 domain 的方式來獲取所有的 peers,然后依次和單獨的 Pod 通信。
可以看到,訪問 web-0.nginx.default.svc.cluster.local 會返回 pod IP,訪問 nginx.default.svc.cluster.local 會返回所有 Pet 中的 pods IP。一個常見的方式是通過訪問 domain 的方式來獲取所有的 peers,然后依次和單獨的 Pod 通信。
存儲身份這塊采用的是 PV/PVC 實現,當我們創建 PetSet 時,需要指定分配給 Pet 的數據卷,如下圖:
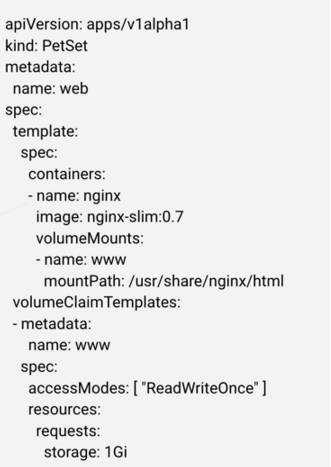

這里,volumeClaimTemplates 指定每個 Pet 需要的存儲資源。注意目前所有 Pet 都得到相同大小和類型的數據卷。當 PetSet 控制器拿到請求時,會為每一個 Pet 創建 PVC,然后將每個 Pet 和對應的 PVC 聯系起來:

之后的 PetSet 只需要確保每個 Pet 都與相對應的 PVC 綁定在一起即可,其他工作,類似于創建數據卷,掛載等工作,都交給其他組件。
通過名字,網絡,存儲,PetSet 能夠 cover 大多數的案例。但是,目前還存在很多需要完善的地方,感興趣的讀者可以參考:https://github.com/kubernetes/kubernetes/issues/28718
3 Scheduled Job
Scheduled Job 本質上是集群 cron,類似 mesos chronos,采用標準的 cron 語法。遺憾的是在 1.3 中還并未達到發布的標準。Scheduled Job 其實在很早就提出來過,但當時 kubernetes 的重點還在 API 層面,并且即使有很大需求,也計劃在 Job(1.2GA)之后實現。當 scheduled job 在之后的版本發布之后,用戶可以用一條簡單的命令在 kubernetes 上運行 Job,例如:kubectl run cleanup -image=cleanup --runAt="0 1 0 0 *" -- /scripts/cleanup.sh一些關于 scheduled job 的更新可以參考:https://github.com/kubernetes/kubernetes/pull/25595
4 Disruption Budget
Disruption Budget 的提出是為了向 Pod 提供一個反饋機制,確保應用不會被集群自身的變動而受影響。例如,當集群需要進行重調度時,應用可以通過 Disruption Budget 來說明 Pod 能不能被遷移。Disruption Budget 只負責集群自身發起的變動,不負責突發事件比如節點突然掉線,或者應用本身的問題比如不斷重啟的變動。Disruption Budget 同樣沒有在 1.3 中發布。
與 kubernetes 大多數資源類似,我們需要通過 Yaml 文件創建一個 PodDisruptionBudget 資源,例如,下圖所示的 Disruption Budget 選中了所有帶有 app:nginx 標簽的 pod,并且要求至少有 3 個 Pod 在同時運行。

Controller manager 內有一個新的組件 Disruption Budget Controller,來負責維護所有 Budget 的狀態,例如上圖中的 status 表明當前共有 4 個健康的 Pod(currentHealthy),應用要求至少有 3 個(desiredHealthy),總共有 5 個Pod(expectedPods)。為了維護這個狀態,Disruption Budget Controller 會遍歷所有的 Budget 和所有的 Pod。有了 Budget 的狀態,需要改變 Pod 狀態的組件都要先查詢之。若其操作導致最小可用數低于應用要求,則操作會被拒絕。Disruption Budget 與 QoS 聯系很緊密。例如,如果一個 QoS level 很低的應用有著非常嚴格的 Disruption Budget,系統應該如何處理?目前,kubernetes 還沒有嚴格的處理這個問題,一個可行的辦法是對 Disruption Budget 做優先級處理,確保高優先級的應用擁有高優先級的 Disruption Budget;此外,Disruption Budget 可以加入 Quota 系統,高優先級的應用可以獲得更多 Disruption Budget Quota。關于 Disruption Budget 的討論可以參考:https://github.com/kubernetes/kubernetes/issues/12611
1 Cascading Deletion
在 kubernetes 1.2 之前,刪除控制單元都不會刪除底層的資源。例如,通過 API 刪除 RC 之后,其管理的 Pod 不會被刪除(使用 kubectl 可以刪除,但 kubectl 里面有 reaper 邏輯,會依次刪除底層的所有 Pod,本質上是客戶端邏輯)。另外一個例子,當刪除下圖中的 Deployment 時,ReplicaSet 不會被自動刪除,當然,Pod 也不會被回收。
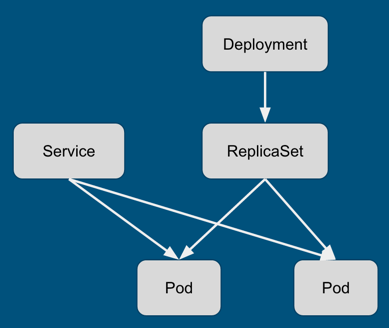

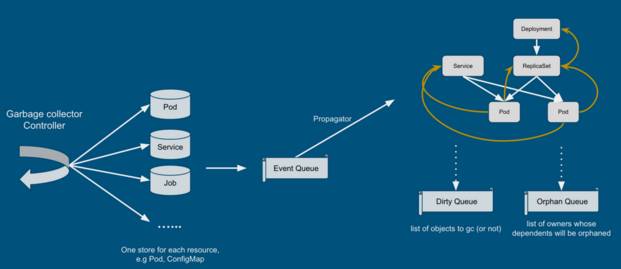
Cascading deletion 指的就是在刪除控制單元后,將被管理單元也同時回收。但是,kubernetes 1.3 中的 cascading deletion 并不是簡單地講 kubectl 中的邏輯復制到 server 端,而是做了更高層次的工作:垃圾回收。簡單來講,garbagecollector controller 維護了幾乎所有集群資源的列表,并接收資源修改的事件。controller 根據事件類型更新資源關系圖,并將受影響的資源放入 Dirty Queue 或者 Orphan Queue 中。具體實現可以參考官方文檔和 garbage collector controller 實現:https://github.com/kubernetes/kubernetes/blob/master/docs/proposals/garbage-collection.md

2 Node eviction
Node/kubelet eviction 指的是在節點將要超負荷之前,提前將 Pod 剔除出去的過程,主要是為了內存和磁盤資源。在 kubernetes 1.3 之前,kubelet 不會“提前”感知節點的負荷,只會對已知的問題進行處理。當內存吃緊時,kubernetes 依靠內核 OOM killer;磁盤方面則定期對 image 和 container 進行垃圾回收。但是,這種方式有局限性,OOM killer 本身需要消耗一定資源,并且時間上有不確定性;回收容器和鏡像不能處理容器寫日志的問題:如果應用不斷寫日志,則會消耗掉所有磁盤,但不會被 kubelet 處理。
Node eviction 通過配置 kubelet 解決了以上問題。當啟動 kubelet 時,我們通過指定 memory.available, nodefs.available, nodefs.inodesFree 等參數來確保節點穩定工作。例如,memory.available < 200Mi 表示當內存少于 200Mi時,kubelet 需要開始移除 Pod(可以配置為立即移除或者延遲移除,即 hard vs soft)。kubernetes 1.3 中,node eviction 的特性是 opt-in,默認關閉,可以通過配置 kubelet 打開相關功能。
盡管 node eviction 是 kubelet 層面采取的措施,我們也必須考慮與整個集群的交互關系。其中最重要的一點是如何將這個問題反饋給 scheduler,不然被剔除的 Pod 很有可能會被重新調度回來。為此,kubernetes 添加了新的 node condition:MemoryPressure, DiskPressure。當節點的狀態包含其中任意一種時,調度器會避免往該節點調度新的 Pod。這里還有另外一個問題,即如果節點的資源使用剛好在閾值附近,那么節點的狀態可能會在 Pressure 和 Not Pressure 之間抖動。防抖動的方法有很多種,例如平滑濾波,即將歷史數據也考慮在內,加權求值。k8s 目前采用較為簡單的方法:即如果節點處于 Pressure 狀態,為了轉變成 Not Pressure 狀態,資源使用情況必須低于閾值一段時間(默認 5 分鐘)。這種方法會導致 false alarm,比如,若一個應用每隔一段時間請求一塊內存,之后很快釋放掉,那么可能會導致節點一直處于 Pressure 狀態。但大多數情況下,該方法能處理抖動的情況。
說到 eviction pod,那么另外一個不得不考慮的問題就是找一個倒霉的 Pod。這里 kubernetes 定義了不少規則,總結下來主要是兩點:1. 根據 QoS 來判斷,QoS 低的應用先考慮;2. 根據使用量判斷,使用量與總請求量比例大的 Pod 優先考慮。具體細節可以參考:https://github.com/kubernetes/kubernetes/blob/master/docs/proposals/kubelet-eviction.md
3 Network Policy
Network policy 的目的是提供 Pod 之間的隔離,用戶可以定義任意 Pod 之間的通信規則,粒度為端口。例如,下圖的規則可以解釋成:擁有標簽“db”的 Pod,只能被擁有標簽“frontend”的 Pod 訪問,且只能訪問 tcp 端口 6379。

Network policy 目前處于 beta 版本,并且只是 API。也就是說,kubernetes 不會真正實現網絡隔離:如果我們將上述 Yaml 文件提交到 kubernetes,并不會有任何反饋,kubernetes 只是保存了這個 Policy 內容。真正實現 policy 功能需要其他組件,比如 calico 實現了一個 controller,會讀取用戶創建的 Policy 來實現隔離,可以參考:https://github.com/projectcalico/k8s-policy/。關于 Network Policy 的細節,可以參考:https://github.com/kubernetes/kubernetes/blob/master/docs/proposals/network-policy.md
4 Federation
Federation cluster 翻譯成中文叫“聯合集群”,即將多個 kubernetes 集群聯合成一個整體,并且不改變原始 kubernetes 集群的工作方式。根據 kubernetes 官方設計文檔,federation 的設計目的主要是滿足服務高可用,混合云等需求。在 1.3 版本之前,kubernetes 實現了 federation-lite,即一個集群中的機器可以來自于相同 cloud 的不同 zone;1.3 版本中,federation-full 的支持已經是 beta 版本,即每個集群來自不同的 cloud(或相同)。
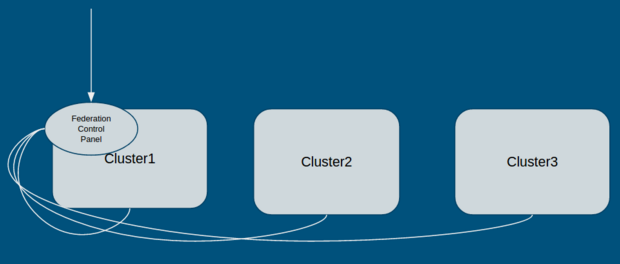
Federation的核心組件主要是 federation-apiserver 和 federation-controller-manager,以 Pod 形式運行在其中一個集群中。如下圖所示,外部請求直接與 Federation Control Panel 通信,由 Federation 分析請求并發送至 kubernetes 集群。
 在應用層面,Federation 目前支持 federated services,即一個應用跨多個集群的訪問
在應用層面,Federation 目前支持 federated services,即一個應用跨多個集群的訪問
“Kubernetes1.3有哪些新功能”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





