溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Hive Index的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
The goal of Hive indexing is to improve the speed of query lookup on certain columns of a table. Without an index, queries with predicates like 'WHERE tab1.col1 = 10' load the entire table or partition and process all the rows. But if an index exists for col1, then only a portion of the file needs to be loaded and processed.
The improvement in query speed that an index can provide comes at the cost of additional processing to create the index and disk space to store the index.
Create/build, show, and drop index:
CREATE INDEX table01_index ON TABLE table01 (column2) AS 'COMPACT'; SHOW INDEX ON table01; DROP INDEX table01_index ON table01;
Create then build, show formatted (with column names), and drop index:
CREATE INDEX table02_index ON TABLE table02 (column3) AS 'COMPACT' WITH DEFERRED REBUILD; ALTER INDEX table02_index ON table2 REBUILD; SHOW FORMATTED INDEX ON table02; DROP INDEX table02_index ON table02;
Create bitmap index, build, show, and drop:
CREATE INDEX table03_index ON TABLE table03 (column4) AS 'BITMAP' WITH DEFERRED REBUILD; ALTER INDEX table03_index ON table03 REBUILD; SHOW FORMATTED INDEX ON table03; DROP INDEX table03_index ON table03;
Create index in a new table:(可以把索引單獨放到一個database中)
CREATE INDEX table04_index ON TABLE table04 (column5) AS 'COMPACT' WITH DEFERRED REBUILD IN TABLE table04_index_table;
Create index stored as RCFile:
CREATE INDEX table05_index ON TABLE table05 (column6) AS 'COMPACT' STORED AS RCFILE;
Create index stored as text file:
CREATE INDEX table06_index ON TABLE table06 (column7) AS 'COMPACT' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
Create index with index properties:
CREATE INDEX table07_index ON TABLE table07 (column8) AS 'COMPACT' IDXPROPERTIES ("prop1"="value1", "prop2"="value2");Create index with table properties:
CREATE INDEX table08_index ON TABLE table08 (column9) AS 'COMPACT' TBLPROPERTIES ("prop3"="value3", "prop4"="value4");Drop index if exists:
DROP INDEX IF EXISTS table09_index ON table09;
Rebuild index on a partition:
ALTER INDEX table10_index ON table10 PARTITION (columnX='valueQ', columnY='valueR') REBUILD;
build index的時候會通過mapreduce來實現。
一個stus表(name,age)
k,1
w,4
l,1
對age建立索引,在warehouse中建立了索引目錄。
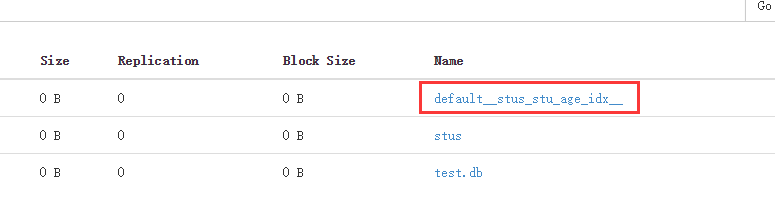
對應里面的目錄
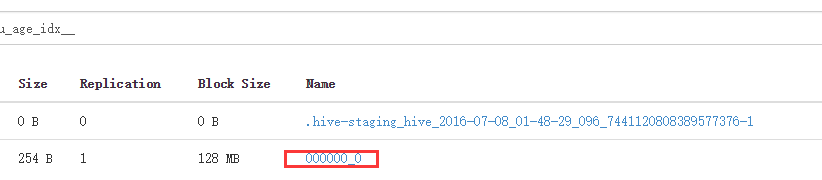
就是索引文件,會根據save不同類型,而產生不同的,默認是text的。
打開索引文件可以看到

記錄了被索引對象的文件位置。這樣就可以讀取部分,實現減少map的功能。
隨便根據age跑了一個group操作,索引前后對比如下
Map: 1 Reduce: 1 Cumulative CPU: 3.27 sec HDFS Read: 6694 HDFS Write: 8 SUCCESS
Map: 1 Reduce: 1 Cumulative CPU: 3.14 sec HDFS Read: 6715 HDFS Write: 8 SUCCESS
發現,雖然文件讀取的更多了,但是時間更快了,數據集太少,效果可能也不是很明顯。
索引文件,其實也是一個表,所以ROW FORMAT DELIMITED FIELDS,TORED AS RCFILE; 等都可以使用。
只不過所以索引文件格式是COMPACT還是BITMAP等,
以上是“Hive Index的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





