溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Shuffle的洗牌過程是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Shuffle的正常意思是洗牌或弄亂
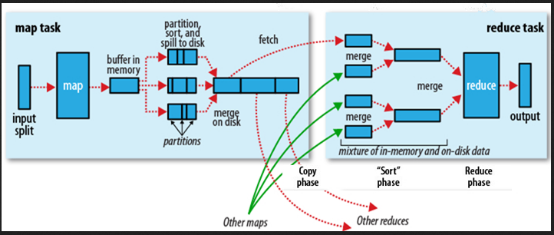
Shuffle描述著數據從map task輸出到reduce task輸入的這段過程。.
大部分map task與reduce task的執行是在不同的節點上。當然很多情況下Reduce執行時需要跨節點去拉取其它節點上的map task結果。
我們對Shuffle過程的期望可以有:
完整地從map task端拉取數據到reduce 端。在跨節點拉取數據時,盡可能減少對帶寬的不必要消耗。減少磁盤IO對task執行的影響。
Shuffle解釋
每個map task都有一個內存緩沖區,存儲著map的輸出結果,當緩沖區快滿的時候需要將緩沖區的數據以一個臨時文件的方式存放到磁盤,當整個map task結束后再對磁盤中這個map task產生的所有臨時文件做合并,生成最終的正式輸出文件,然后等待reduce task來拉數據。
1、在map task執行時,它的輸入數據來源于HDFS的block,當然在MapReduce概念中,map task只讀取split。Split與block的對應關系可能是多對一,默認是一對一。
2、在經過mapper類的運行后,我們得知mapper的輸出是這樣一個k/v鍵值
對。在這只做統計,reduce才做合并。
3.Partitioner接口,它的作用就是根據key或value及reduce的數量來決定當前的這對輸出數據最終應該交由哪個reduce task處理。默認對key hash后再以reduce task數量取模。默認的取模方式只是為了平均reduce的處理能力,如果用戶自己對Partitioner有需求,可以訂制并設置到job.set(..)。
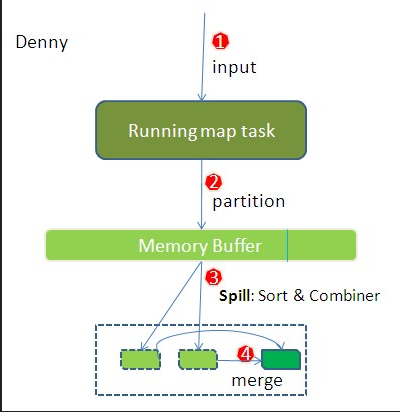
4(Memory Buffer)接下來我們將數據寫入到內存緩沖區中,緩沖區的作用是批量收集map結果,減少磁盤IO的影響。我們的key/value對以及Partition的結果都會被寫入緩沖區。當然寫入之前,key與value值都會被序列化成字節數組。
5內存緩沖區是有大小限制的,默認是100MB。當map task 的輸出結果大于這個內存緩沖區的閥值是(buffer size * spill percent = 100MB * 0.8 = 80MB)
溢寫線程啟動,把這80M在緩沖區的數據寫入到磁盤中,Map task向剩下20MB在內存中,互補影響。這個從內存往磁盤寫數據的過程被稱為Spill
當溢寫線程啟動后,需要對這80MB空間內的key做排序(Sort)。排序是MapReduce模型默認的行為,這里的排序也是對序列化的字節做的排序。
圖上也可以看到寫到磁盤中的溢寫文件是對不同的reduce端的數值做過合并。所以溢寫過程一個很重要的細節在于,如果有很多個key/value 對需要發送到某個reduce端去,那么需要將這些key/value值拼接到一塊,減少與partition相關的索引記錄。
6.如果client設置過Combiner,那么現在就是使用Combiner的時候了。將有相同key的key/value對的value加起來,減少溢 寫到磁盤的數據量。Combiner會優化MapReduce的中間結果,所以它在整個模型中會多次使用。那哪些場景才能使用Combiner呢?從這里 分析,Combiner的輸出是Reducer的輸入,Combiner絕不能改變最終的計算結果。所以從我的想法來看,Combiner只應該用于那種 Reduce的輸入key/value與輸出key/value類型完全一致,且不影響最終結果的場景。比如累加,最大值等。Combiner的使用一定 得慎重,如果用好,它對job執行效率有幫助,反之會影響reduce的最終結果。
7.每次溢寫會在磁盤上產生一個溢寫文件,Map 輸出結果很大時,會有多次這樣的溢寫文件到磁盤上,當 Map task 結束完成時,內存緩沖區的數據同樣也會溢寫到磁盤上,結果磁盤會有一個或多個溢出的文件,同時合并溢出的文件。(如果map輸出的結果很少,map完成時,溢出的文件只有一個)合并這個過程就叫做Merge{墨跡}
merge是將多個溢寫文件合并到一個文件,所以可能也有相同的key存在,在這個過程中如果client設置過Combiner,也會使用Combiner來合并相同的key。
此時,map端的工作都已結束,最終生成的文件也存放在Task Tracker本地目錄內,每個reduce task 不斷的通過RPC 從JOBTracker哪里獲取 map task 是否完成,如果reduce task 得到通知,通知到某臺Task Tracker 上的map task執行完成,shuffle的reducece開始拉去map Task完成的數據
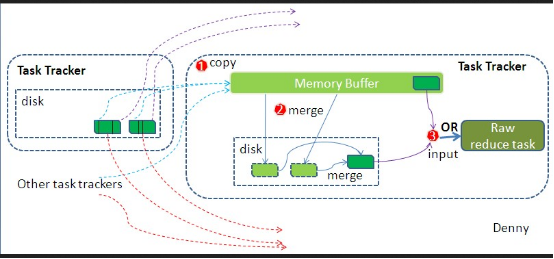
Reducer真正運行之前,所有的時間都是在拉取數據,做merge,且不斷重復地在做。如前面的方式一樣,分段地描述reduce 端的Shuffle細節
1.copy 過程,就是拉取數據。Reduce進程啟動一些copy線程,通過Http方式請求 map task 所在的TaskTracker獲取map task的輸出文件。應為map task 已經結束,這文件就歸TaskTracker管理了,管理在本地磁盤中。
2.copy過來的數據會先儲存在內存緩沖區中(Memory Buffer),這里的緩沖區要比map端的更加靈活,它基于JVM的heap size 的設置,因為shuffle階段rduce不運行,所以把大部分的內存給shuffle來用,
這里和map中內存溢出一樣,當內存中的數據達到一定的閥值,就會啟動內存到磁盤的溢出....合并Merge 。這個過程我們設置Combiner,也會啟用的,然后在磁盤中生成很多一些文件。值到map端沒有數據才結束。然后啟動第三種磁盤到磁盤的merge方式生成最終的那個文件。
3.Reduce的輸入文件,不斷的合并后(merge),最后會生成一個“最終文件”,這個文件可能存在磁盤上也能在內存中(內存需要設置并且優化),默認在磁盤中,當Reducer的輸入文件已定,整個Shuffle才最終結束。然后就是Reducer執行,把結果放到HDFS上。
“Shuffle的洗牌過程是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





