溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“ElassticSearch文檔操作的方法有哪些”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“ElassticSearch文檔操作的方法有哪些”吧!
###第一章
######與Elasticsearch交互
節點客戶端(node client)
節點客戶端以無數據節點(none data node)身份加入集群,換言之,它自己不存儲任何數據,但是它知道數據在集群中的具體位置,并且能夠直接轉發請求到對應的節點上。
傳輸客戶端(Transport client)
這個更輕量的傳輸客戶端能夠發送請求到遠程集群。它自己不加入集群,只是簡單轉發請求給集群中的節點。
基于HTTP協議,以JSON為數據交互格式的RESTful API
其他所有程序語言都可以使用RESTful API,通過9200端口的與Elasticsearch進行通信
######比較
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
###第二章###
####概念:###
索引(index)——一個存儲關聯數據的地方。實際上,索引只是一個用來指向一個或多個分片(shards)的“邏輯命名空間(logical namespace)”
一個分片(shard)是一個最小級別“工作單元(worker unit)”,它只是保存了索引中所有數據的一部分(分片就是一個Lucene實例,并且它本身就是一個完整的搜索引擎。我們的文檔存儲在分片中,并且在分片中被索引,但是我們的應用程序不會直接與它們通信,取而代之的是,直接與索引通信)
分片的最大容量完全取決于你的使用狀況:硬件存儲的大小、文檔的大小和復雜度、如何索引和查詢你的文檔,以及你期望的響應時間(項目做壓測是需要確定,主分片的數量在創建索引時已經確定,這個數量定義了能存儲到索引里數據的最大數量;然而,主分片或者復制分片都可以處理讀請求——搜索或文檔檢索,所以數據的冗余越多,我們能處理的搜索吞吐量就越大)
如果被重啟的機器有舊分片的拷貝,它將會嘗試再利用它們,它只會從主分片上復制在故障期間有數據變更的那一部分
###第三章###
無論程序怎么寫,意圖是一樣的:組織數據為我們的目標所服務。但數據并不只是由隨機比特和字節組成,我們在數據節點間建立關聯來表示現實世界中的實體或者“某些東西”。屬于同一個人的名字和Email地址會有更多的意義
####什么是文檔?
鍵值對的JSON對象,鍵(key)是字段(field)或屬性(property)的名字,值(value)可以是字符串、數字、布爾類型、另一個對象、值數組或者其他特殊類型,比如表示日期的字符串或者表示地理位置的對象
在Elasticsearch中,文檔(document)這個術語有著特殊含義。它特指最頂層結構或者根對象(root object)序列化成的JSON數據(以唯一ID標識并存儲于Elasticsearch中)
一個文檔不只有數據。它還包含了元數據(metadata):_index,_type,_id
檢索文檔的一部分(包含原數據):
GET /website/blog/123?_source=title,text
只想得到_source字段而不要其他的元數據,你可以這樣請求:GET /website/blog/123/_source
檢查文檔是否存在:
curl -i -XHEAD http://localhost:9200/website/blog/123
(返回200 OK狀態如果你的文檔存在,如果不存在返回404 Not Found,當然,這只表示你在查詢的那一刻文檔不存在,但并不表示幾毫秒后依舊不存在。另一個進程在這期間可能創建新文檔)
使用自定義的_id,我們必須告訴Elasticsearch應該在_index、_type、_id三者都不同時才接受請求。
PUT /website/blog/123?op_type=create PUT /website/blog/123/_create
返回正常的元數據且響應狀態碼是201 Created,另一方面,如果包含相同的_index、_type和_id的文檔已經存在,Elasticsearch將返回409 Conflict響應狀態碼(報錯是因為參數create,如果沒有create參數,那么會更新文檔只是返回的結果中created為false,在內部,Elasticsearch會標記舊文檔為刪除并添加了一個完整的新文檔。舊版本文檔不會立即消失,但你也不能去訪問它。Elasticsearch會在你繼續索引更多數據時清理被刪除的文檔)
刪除文檔
DELETE /website/blog/123,
如果文檔被找到,Elasticsearch將返回200 OK狀態碼和以下響應體。注意_version數字已經增加了.如果文檔未找到,我們將得到一個404 Not Found狀態碼.盡管文檔不存在——"found"的值是false——_version依舊增加了。這是內部記錄的一部分,它確保在多節點間不同操作可以有正確的順序.
版本控制
悲觀并發控制(Pessimistic concurrency control) 這在關系型數據庫中被廣泛的使用,假設沖突的更改經常發生,為了解決沖突我們把訪問區塊化。典型的例子是在讀一行數據前鎖定這行,然后確保只有加鎖的那個線程可以修改這行數據。 樂觀并發控制(Optimistic concurrency control)
被Elasticsearch使用,假設沖突不經常發生,也不區塊化訪問,然而,如果在讀寫過程中數據發生了變化,更新操作將失敗。這時候由程序決定在失敗后如何解決沖突。實際情況中,可以重新嘗試更新,刷新數據(重新讀取)或者直接反饋給用戶。
我們利用_version的這一優點確保數據不會因為修改沖突而丟失
eg:
Let's create a new blog post: 讓我們創建一個新的博文
PUT /website/blog/1/_create
{
"title": "My first blog entry",
"text": "Just trying this out..."
}響應體告訴我們這是一個新建的文檔,它的_version是1。現在假設我們要編輯這個文檔:把數據加載到web表單中,修改,然后保存成新版本。
首先我們檢索文檔:
GET /website/blog/1
現在,當我們通過重新索引文檔保存修改時,我們這樣指定了version參數:
PUT /website/blog/1?version=1 <1>
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}我們只希望文檔的_version是1時更新才生效
文檔局部更新
POST /website/blog/1/_update
{
"doc" : {
"tags" : [ "testing" ],
"views": 0
}
}檢索多個文檔
mget方式
更省時的批量操作
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }
{ "doc" : {"title" : "My updated blog post"} }多大才算太大?
整個批量請求需要被加載到接受我們請求節點的內存里,所以請求越大,給其它請求可用的內存就越小。有一個最佳的bulk請求大小。超過這個大小,性能不再提升而且可能降低。
最佳大小,當然并不是一個固定的數字。它完全取決于你的硬件、你文檔的大小和復雜度以及索引和搜索的負載。幸運的是,這個最佳點(sweetspot)還是容易找到的:
試著批量索引標準的文檔,隨著大小的增長,當性能開始降低,說明你每個批次的大小太大了。開始的數量可以在1000~5000個文檔之間,如果你的文檔非常大,可以使用較小的批次。
通常著眼于你請求批次的物理大小是非常有用的。一千個1kB的文檔和一千個1MB的文檔大不相同。一個好的批次最好保持在5-15MB大小間。
###第四章###
路由
shard = hash(routing) % number_of_primary_shards
routing值是一個任意字符串,它默認是_id但也可以自定義。這個routing字符串通過哈希函數生成一個數字,然后除以主切片的數量得到一個余數(remainder),余數的范圍永遠是0到number_of_primary_shards - 1,這個數字就是特定文檔所在的分片(這也解釋了為什么主分片的數量只能在創建索引時定義且不能修改:如果主分片的數量在未來改變了,所有先前的路由值就失效了,文檔也就永遠找不到了)
所有的文檔API(get、index、delete、bulk、update、mget)都接收一個routing參數,它用來自定義文檔到分片的映射。自定義路由值可以確保所有相關文檔——例如屬于同一個人的文檔——被保存在同一分片上
新建、索引和刪除文檔
請求節點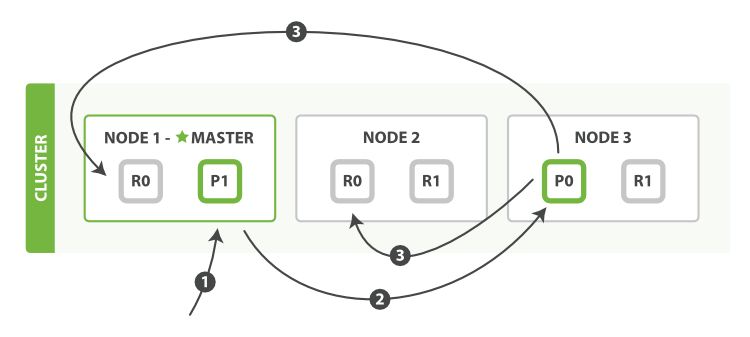
下面我們羅列在主分片和復制分片上成功新建、索引或刪除一個文檔必要的順序步驟:
客戶端給Node發送新建、索引或刪除請求。
節點使用文檔的_id確定文檔屬于分片0。它轉發請求到Node 3,分片0位于這個節點上。 Node 3在主分片上執行請求,如果成功,它轉發請求到相應的位于Node 1和Node的復制節點上。當所有的復制節點報告成功,Node報告成功到請求的節點,請求的節點再報告給客戶端。
客戶端接收到成功響應的時候,文檔的修改已經被應用于主分片和所有的復制分片。你的修改生效了
復制默認的值是sync
consistency允許的值為one(只有一個主分片),all(所有主分片和復制分片)或者默認的quorum或過半分片 int( (primary + number_of_replicas) / 2 ) + 1。
當分片副本不足時會怎樣?Elasticsearch會等待更多的分片出現。默認等待一分鐘,timeout參數 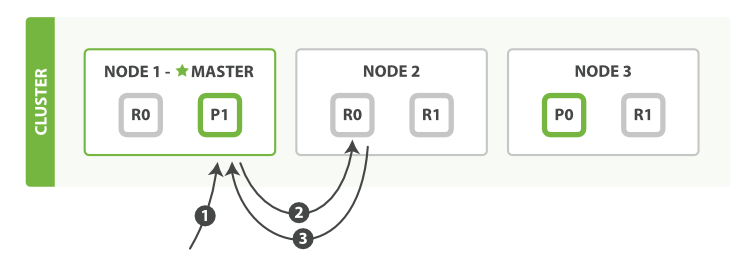
下面我們羅列在主分片或復制分片上檢索一個文檔必要的順序步驟:
客戶端給Node 1發送get請求。
節點使用文檔的_id確定文檔屬于分片0。分片0對應的復制分片在三個節點上都有。此時,它轉發請求到Node 2(根據路由法則計算出文檔所在的分片地址)。
Node 2返回endangered給Node 1然后返回給客戶端。 對于讀請求,為了平衡負載,請求節點會為每個請求選擇不同的分片——它會循環所有分片副本,可能的情況是,一個被索引的文檔已經存在于主分片上卻還沒來得及同步到復制分片上。這時復制分片會報告文檔未找到,主分片會成功返回文檔。一旦索引請求成功返回給用戶,文檔則在主分片和復制分片都是可用的
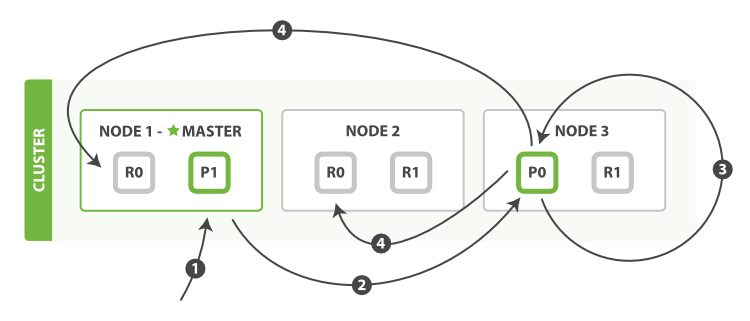
下面我們羅列執行局部更新必要的順序步驟:
客戶端給Node 1發送更新請求。
它轉發請求到主分片所在節點Node 3。
Node 3從主分片檢索出文檔,修改_source字段的JSON,然后在主分片上重建索引。如果有其他進程修改了文檔,它以retry_on_conflict設置的次數重復步驟3,都未成功則放棄。
如果Node 3成功更新文檔,它同時轉發文檔的新版本到Node 1和Node 2上的復制節點以重建索引。當所有復制節點報告成功,Node 3返回成功給請求節點,然后返回給客戶端。 update API還接受《新建、索引和刪除》章節提到的routing、replication、consistency和timout參數。 多文檔模式 mget和bulk API與單獨的文檔類似。差別是請求節點知道每個文檔所在的分片。它把多文檔請求拆成每個分片的對文檔請求,然后轉發每個參與的節點。
一旦接收到每個節點的應答,然后整理這些響應組合為一個單獨的響應,最后返回給客戶端。
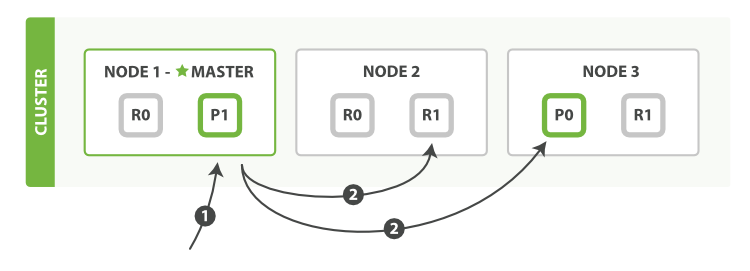
下面我們將羅列通過一個mget請求檢索多個文檔的順序步驟:
客戶端向Node 1發送mget請求。
Node 1為每個分片構建一個多條數據檢索請求,然后轉發到這些請求所需的主分片或復制分片上。當所有回復被接收,Node 1構建響應并返回給客戶端。
routing 參數可以被docs中的每個文檔設置。
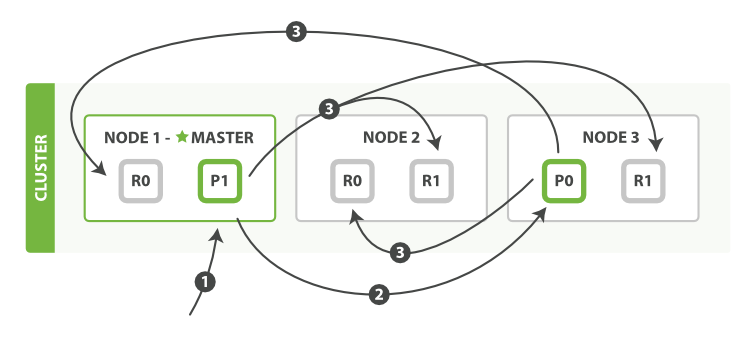
下面我們將羅列使用一個bulk執行多個create、index、delete和update請求的順序步驟:
客戶端向Node 1發送bulk請求。
Node 1為每個分片構建批量請求,然后轉發到這些請求所需的主分片上。
主分片一個接一個的照順序執行操作。當一個操作執行完,主分片轉發新文檔(或者刪除部分)給對應的復制節點,然后執行下一個操作。復制節點為報告所有操作完成,節點報告給請求節點,請求節點整理響應并返回給客戶端。
bulk API還可以在最上層使用replication和consistency參數,routing參數則在每個請求的元數據中使用。
###第五章###
A search can be: 搜索(search)可以:
在類似于gender或者age這樣的字段上使用結構化查詢,join_date這樣的字段上使用排序,就像SQL的結構化查詢一樣。
全文檢索,可以使用所有字段來匹配關鍵字,然后an照關聯性(relevance)排序返回結果。
或者結合以上兩條
| 概念 | 解釋 |
|---|---|
| 映射(Mapping) | 數據在每個字段中的解釋說明 |
| 分析(Analysis) | 全文是如何處理的可以被搜索的 |
| 領域特定語言查詢(Query DSL) | Elasticsearch使用的靈活的、強大的查詢語言 |
###第六章###
映射(mapping)機制用于進行字段類型確認,將每個字段匹配為一種確定的數據類型(string, number, booleans, date等)。
分析(analysis)機制用于進行全文文本(Full Text)的分詞,以建立供搜索用的反向索引。
到此,相信大家對“ElassticSearch文檔操作的方法有哪些”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





