溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么解密SparkStreaming運行機制,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
一:spark各個子框架的關系:
上節課我們采用了降維的方式查看了整個spark streaming的大概運行的過程,再次強調,spark streaming 其實是構建在spark core之上的一個應用程序,如果要構建一個強大的spark應用程序 ,spark streaming 是一個值得借鑒的參考,spark streaming涉及多個job交叉配合,里面涉及到了spark的所有的核心組件,如果對spark streaming 精通了的話,可以說就精通了整個spark,所以精通掌握spark streaming是至關重要的
spark 的各個子框架都是基于spark core的。spark streaming在內部的處理機制是接受實時流的數據,并根據一定的時間間隔分成一批一批的數據,然后通過spark engine處理這些批數據,最后得到處理后的一批一批的數據。
對應的批數據,在spark內核對應RDD,在spark streaming中對應DStream ,一個DStream相當于RDD的模板,對應一組RDD(RDD的一個序列)
通俗點理解的話,在數據分成一批一批后,通過一個隊列,然后spark引擎從該隊列中依次一個一個的取出批數據,把批數據封裝成一個DStream,因為DStream是RDD的模板,是RDD的一個邏輯級別的抽象,所以實質上是把數據封裝成為物理級別的RDD.
二:Spark Streaming基礎概念理解:
為了更好的理解spark streaming,我們先簡單的對相關概念理解一下
1 離散流:(Discretized Stream ,DStream):這是spark streaming對內部的持續的實時數據流的抽象描述,也即我們處理的一個實時數據流,在spark streaming中對應一個DStream
2 批數據:將實時流時間以時間為單位進行分批,將數據處理轉化為時間片數據的批處理
3 時間片或者批處理時間間隔:邏輯級別的對數據進行定量的標準,以時間片作為拆分流數據的依據。
4 窗口長度:一個窗口覆蓋的流數據的時間長度。比如說要每隔5分鐘統計過去30分鐘的數據,窗口長度為6,因為30分鐘是batch interval 的6倍
5 滑動時間間隔:比如說要每隔5分鐘統計過去30分鐘的數據,窗口時間間隔為5分鐘
6 input DStream :一個inputDStream是一個特殊的DStream 將spark streaming連接到一個外部數據源來讀取數據。
7 Receiver :長時間(可能7*24小時)運行在Excutor之上,每個Receiver負責一個inuptDStream (比如讀取一個kafka消息的輸入流)。每個Receiver,加上inputDStream 會占用一個core/slot
重點來了!!!我們用時空維度和空間維度分別對DStream 和RDD來更加深入并且另類的理解spark streaming,以及二者之間的關系。
DStream 對應時空維度,空間加上時間(從目前來看,spark streaming的精妙之一是用時間來解耦合,是目前所見最好的解耦合的方式),RDD對應空間維度,整個sparkStreaming是時空維度。
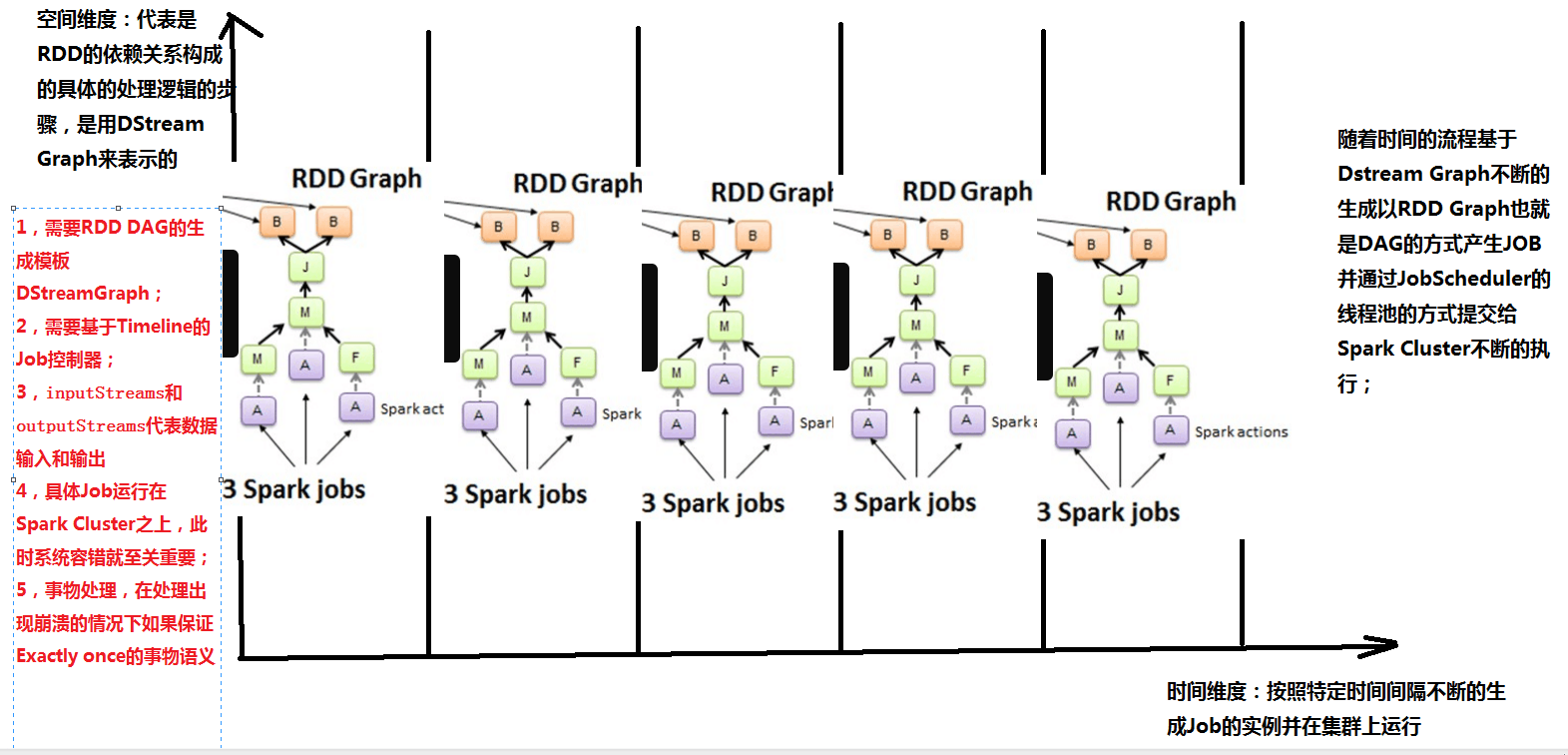
縱軸為空間維度:代表的是RDD的依賴關系構成的具體的處理邏輯的步驟,是用DStream來表示的。
橫軸為時間維度:按照特定的時間間隔不斷地生成job對象,并在集群上運行。
隨著時間的推移,基于DStream Graph 不斷生成RDD Graph ,也即DAG的方式生成job,并通過Job Scheduler的線程池的方式提交給spark cluster不斷的執行。(sparkStreaming只關注時間維度不關注空間維度)
由上可知,RDD 與 DStream的關系如下:
1.RDD是物理級別的,而 DStream 是邏輯級別的
2.DStream是RDD的封裝類,是RDD進一步的抽象
3.DStream 是RDD的模板。DStream要依賴RDD進行具體的數據計算
(注意:縱軸維度需要RDD,DAG的生成模板,需要TimeLine的job控制器
橫軸維度(時間維度)包含batch interval,窗口長度,窗口滑動時間等。)
4.inputStream和outputStream分別代表數據的輸入和輸出
5.具體的job運行在spark cluster之上,此時系統的容錯就非常重要,而spark streaimg的容錯非常巧妙,它巧妙的借用了spark core rdd的容錯而容錯。(RDD可以指定StorageLevel來實現存放多個副本用來做容錯)
6.事務處理:數據一定會被處理,并且只會對數據處理一次,這個特性對于那些諸如計費系統的實現非常重要
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





