溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Hadoop基礎知識點有哪些的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
雛形開始于2002年的Apache的Nutch,Nutch是一個開源Java 實現的搜索引擎。它提供了我們運行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬蟲。
隨后在2003年Google發表了一篇技術學術論文谷歌文件系統(GFS)。GFS也就是google File System,google公司為了存儲海量搜索數據而設計的專用文件系統。
2004年Nutch創始人Doug Cutting基于Google的GFS論文實現了分布式文件存儲系統名為NDFS。
2004年Google又發表了一篇技術學術論文MapReduce。MapReduce是一種編程模型,用于大規模數據集(大于1TB)的并行分析運算。
2005年Doug Cutting又基于MapReduce,在Nutch搜索引擎實現了該功能。
2006年,Yahoo雇用了Doug Cutting,Doug Cutting將NDFS和MapReduce升級命名為Hadoop,Yahoo開建了一個獨立的團隊給Goug Cutting專門研究發展Hadoop。
不得不說Google和Yahoo對Hadoop的貢獻功不可沒。
Hadoop的核心就是HDFS和MapReduce,而兩者只是理論基礎,不是具體可使用的高級應用,Hadoop旗下有很多經典子項目,比如HBase、Hive等,這些都是基于HDFS和MapReduce發展出來的。要想了解Hadoop,就必須知道HDFS和MapReduce是什么。
HDFS(Hadoop Distributed File System,Hadoop分布式文件系統),它是一個高度容錯性的系統,適合部署在廉價的機器上。HDFS能提供高吞吐量的數據訪問,適合那些有著超大數據集(large data set)的應用程序。
HDFS的設計特點是:
1、大數據文件,非常適合上T級別的大文件或者一堆大數據文件的存儲,如果文件只有幾個G甚至更小就沒啥意思了。
2、文件分塊存儲,HDFS會將一個完整的大文件平均分塊存儲到不同計算器上,它的意義在于讀取文件時可以同時從多個主機取不同區塊的文件,多主機讀取比單主機讀取效率要高得多得都。
3、流式數據訪問,一次寫入多次讀寫,這種模式跟傳統文件不同,它不支持動態改變文件內容,而是要求讓文件一次寫入就不做變化,要變化也只能在文件末添加內容。
4、廉價硬件,HDFS可以應用在普通PC機上,這種機制能夠讓給一些公司用幾十臺廉價的計算機就可以撐起一個大數據集群。
5、硬件故障,HDFS認為所有計算機都可能會出問題,為了防止某個主機失效讀取不到該主機的塊文件,它將同一個文件塊副本分配到其它某幾個主機上,如果其中一臺主機失效,可以迅速找另一塊副本取文件。
HDFS的關鍵元素:
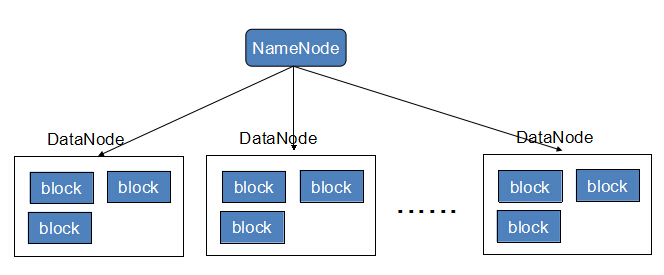
Block:將一個文件進行分塊,通常是64M。
NameNode:保存整個文件系統的目錄信息、文件信息及分塊信息,這是由唯一一臺主機專門保存,當然這臺主機如果出錯,NameNode就失效了。在Hadoop2.*開始支持activity-standy模式----如果主NameNode失效,啟動備用主機運行NameNode。
DataNode:分布在廉價的計算機上,用于存儲Block塊文件。
通俗說MapReduce是一套從海量·源數據提取分析元素最后返回結果集的編程模型,將文件分布式存儲到硬盤是第一步,而從海量數據中提取分析我們需要的內容就是MapReduce做的事了。
下面以一個計算海量數據最大值為例:一個銀行有上億儲戶,銀行希望找到存儲金額最高的金額是多少,按照傳統的計算方式,我們會這樣:
Long moneys[] ...
Long max = 0L;
for(int i=0;i<moneys.length;i++){
if(moneys[i]>max){
max = moneys[i];
}
}如果計算的數組長度少的話,這樣實現是不會有問題的,還是面對海量數據的時候就會有問題。
MapReduce會這樣做:首先數字是分布存儲在不同塊中的,以某幾個塊為一個Map,計算出Map中最大的值,然后將每個Map中的最大值做Reduce操作,Reduce再取最大值給用戶。
MapReduce的基本原理就是:將大的數據分析分成小塊逐個分析,最后再將提取出來的數據匯總分析,最終獲得我們想要的內容。當然怎么分塊分析,怎么做Reduce操作非常復雜,Hadoop已經提供了數據分析的實現,我們只需要編寫簡單的需求命令即可達成我們想要的數據。
感謝各位的閱讀!關于“Hadoop基礎知識點有哪些”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





