溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關hbase中行鎖與多版本并發控制的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
MVCC (Multiversion Concurrency Control),即多版本并發控制技術,它使得大部分支持行鎖的事務引擎,不再單純的使用行鎖來進行數據庫的并發控制,取而代之的是,把數據庫的行鎖與行的多個版本結合起來,只需要很小的開銷,就可以實現非鎖定讀,從而大大提高數據庫系統的并發性能。
HBase正是通過行鎖+MVCC保證了高效的并發讀寫。
HBase系統本身只能保證單行的ACID特性。ACID的含義是:
原子性(Atomicity)
一致性(Consistency)
隔離性(Isolation)
持久性(Durability)
傳統的關系型數據庫一般都提供了跨越所有數據的ACID特性;為了性能考慮,HBase只提供了基于單行的ACID。
下面是一個hbase并發寫的例子。
原始數據如下
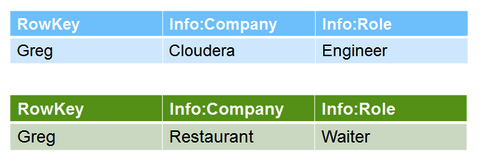
從Apache HBase Write Path一文可以知道hbase寫數據是分為兩步:
1. 寫Write-Ahead-Log(WAL)文件
2. 寫MemStore:將每個cell[(row,column)對]的數據寫到內存中的memstore
假定對寫沒有采取并發控制,并考慮以下的順序:

這樣就得到了不一致的結果。顯然我們需要對并發寫操作進行同步。
最簡單的方式是提供一個基于行的獨占鎖來保證對同一行寫的獨立性。所以寫的順序是:
(0) 獲取行鎖
(1) 寫WAL文件
(2) 更新MemStore:將每個cell寫入到memstore
(3) 釋放行鎖
盡管對并發寫加了鎖,但是對于讀呢?見下面的例子:

可見需要對讀和寫也進行并發控制,不然會得到不一致的數據。最簡單的方案就是讀和寫公用一把鎖。這樣雖然保證了ACID特性,但是讀寫操作同時搶占鎖會互相影響各自的性能。
HBase采用了MVCC算法來避免讀操作去獲取行鎖。
對于寫操作:
(w1) 獲取行鎖后,每個寫操作都立即分配一個寫序號
(w2) 寫操作在保存每個數據cell時都要帶上寫序號
(w3) 寫操作需要申明以這個寫序號來完成本次寫操作
對于讀操作:
(r1) 每個讀操作開始都分配一個讀序號,也稱為讀取點
(r2) 讀取點的值是所有的寫操作完成序號中的最大整數(所有的寫操作完成序號<=讀取點)
(r3) 對某個(row,column)的讀取操作r來說,結果是滿足寫序號為“寫序號<=讀取點這個范圍內”的最大整數的所有cell值的組合
在采用MVCC后的數據執行圖:

這樣就實現了以無鎖的方式讀取到一致的數據了。
重新總結下MVCC算法下寫操作的執行流程:
(0) 獲取行鎖
(0a) 獲取寫序號
(1) 寫WAL文件
(2) 更新MemStore:將每個cell寫入到memstore
(2a) 以寫序號完成操作
(3) 釋放行鎖
關于“hbase中行鎖與多版本并發控制的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





