溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“rabbitMq中架構是怎么樣的”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“rabbitMq中架構是怎么樣的”這篇文章吧。
一:特點
優點:1、輕量,部署方便。 2、消息路由規則靈活。3、消息延遲在微秒級別。
缺點:1、性能相對較弱,單機每秒處理能力在 1W量級。 2、如果消息大量堆積,性能會極具下降。 3、有消息丟失的可能,雖然很低。
所以,如果系統量級不是很大,幾萬-幾十萬以下吞吐量,對性能也沒有非常高的要求,選用rabbitmq還是很不錯的, 使用方便靈活,路由豐富,延遲很低,可靠性也不錯,即使有極小的數據丟失可能,也可以通過一些方法來追蹤(后面會講)。
二:邏輯架構
消息發送流程:
在交換器Exchange與隊列Queue綁定時候,會指定一個綁定鍵bindingKey。生產者發送消息時,會在消息中指定一個路由鍵routingKey,消息到達Exchange后,對比bingdingKey和routingKey將消息路由到合適的Queue中,消費者可通過主動拉取或者監聽的模式,消費隊列中的消息。 (當然,并不是所有的消息都要經過交換器,下面會講) 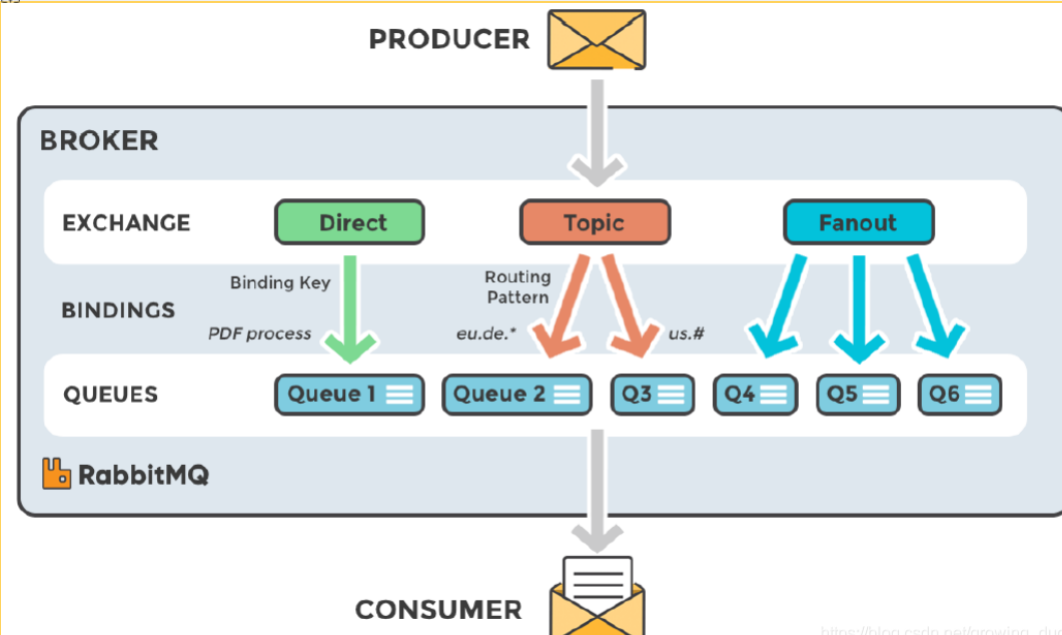
三:工作流程
生產者發送消息:
生產者連接RabbitMQ,建立TCP連接( Connection),開啟信道(Channel)
生產者聲明一個Exchange(交換器),并設置相關屬性,比如交換器類型、是否持久化等
生產者聲明一個隊列井設置相關屬性,比如是否排他、是否持久化、是否自動刪除等
生產者通過 routingKey (路由Key)將交換器和隊列綁定( binding )起來
生產者發送消息至RabbitMQ Broker,其中包含 routingKey (路由鍵)、交換器等信息
相應的交換器根據接收到的 routingKey 查找相匹配的隊列。
如果找到,則將從生產者發送過來的消息存入相應的隊列中。
如果沒有找到,則根據生產者配置的屬性選擇丟棄還是回退給生產者
關閉信道。
關閉連接。
消費者接收消息:
消費者連接到RabbitMQ Broker ,建立一個連接(Connection ) ,開啟一個信道(Channel) 。
消費者向RabbitMQ Broker 請求消費相應隊列中的消息,可能會設置相應的回調函數, 以及
做一些準備工作
等待RabbitMQ Broker 回應并投遞相應隊列中的消息, 消費者接收消息。
消費者確認( ack) 接收到的消息。
RabbitMQ 從隊列中刪除相應己經被確認的消息。
關閉信道。
關閉連接。
Connection 和Channel關系 :
生產者和消費者需要與broker(一個mq實例)建立tcp連接,也就是connection。 接著會在connection基礎上創建一個AMQP信道channel,其實就是一個虛擬的連接,所有指令通過channel完成。
為什么要使用channel,因為多個channel可以復用同一connection來減少性能開銷,便于管理(否則,如果有多個線程收發消息,就要頻繁創建和銷毀TCP連接)。 但是如果channel流量過大,就需要建立多個connection來分擔。 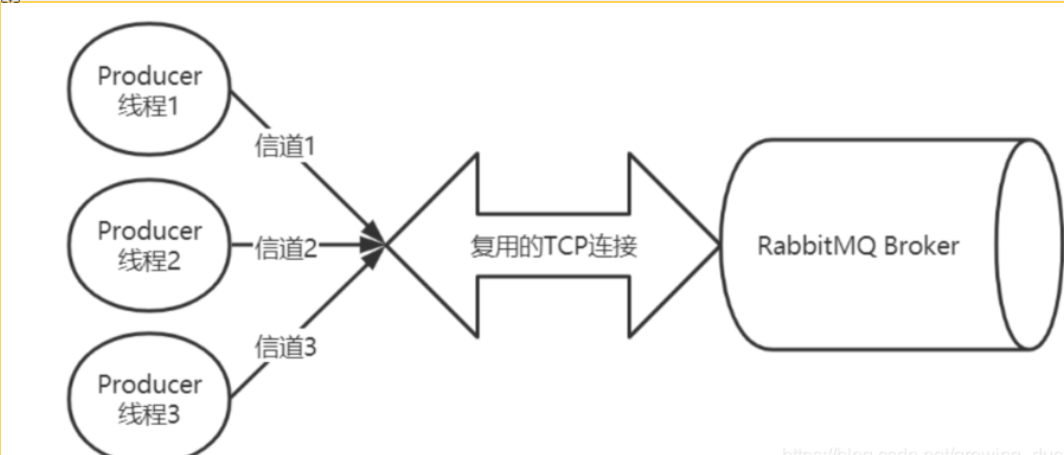
四:交換器類型
前提說明: bingdingKey和routingKey就是一個字符串,以 "." 來分隔,如user.news
常用的交換器類型有: fanout 、 direct 、 topic 、 headers 四種
fanout: 此類交換器會把消息路由到所有與它綁定的隊列中,才不管你是什么key。
direct : bingdingKey和routingKey一致的隊列會收到消息。
topic: direct的升級版,可以對bingdingKey使用通配符。通配符有兩種: # 和 * ,其中 * 用于匹配一個單詞,"#"用于匹配0到多個單詞。 如: bingdingKey為: user.# 。那么發送的消息中,routingKey第一個單詞為user即可匹配。 bingdingKey為: user.*.name 。 那么routingKey第一個和第三個單詞必須為 user 和 name,且只能是三個單詞。
headers: headers這個交換器就神奇了,因為性能很差,一般不太用,但我們還是要了解下。 headers頭交換器, 不需要bingdingKey和routingKey,而是依賴消息頭中設置的屬性值,是一個map。 在交換器和隊列綁定時,也需要指定一個頭屬性,同樣是一個map, 值得注意的是,綁定時候的map中需要put一個鍵值對:map.put("x-match","all") 或map.put("x-match","any"), 差別是: all: 消息中map的所有key和value,綁定的map中全部要能匹配上。 any:只要有一個鍵值對能匹配上就行。
其實headers和direct很相似,不過可以同時支持多個屬性,類型也不只是字符串。
五:數據存儲機制 RabbitMQ消息有兩種類型: 持久化消息:在到達隊列時寫入磁盤,同時會內存中保存一份備份,當內存吃緊時,消息從內存中清除。存內存是為了提高性能。 非持久化消息:一般只存于內存中,當內存壓力大時數據刷盤處理,以節省內存空間。
RabbitMQ存儲層包含兩個部分:隊列索引和消息存儲 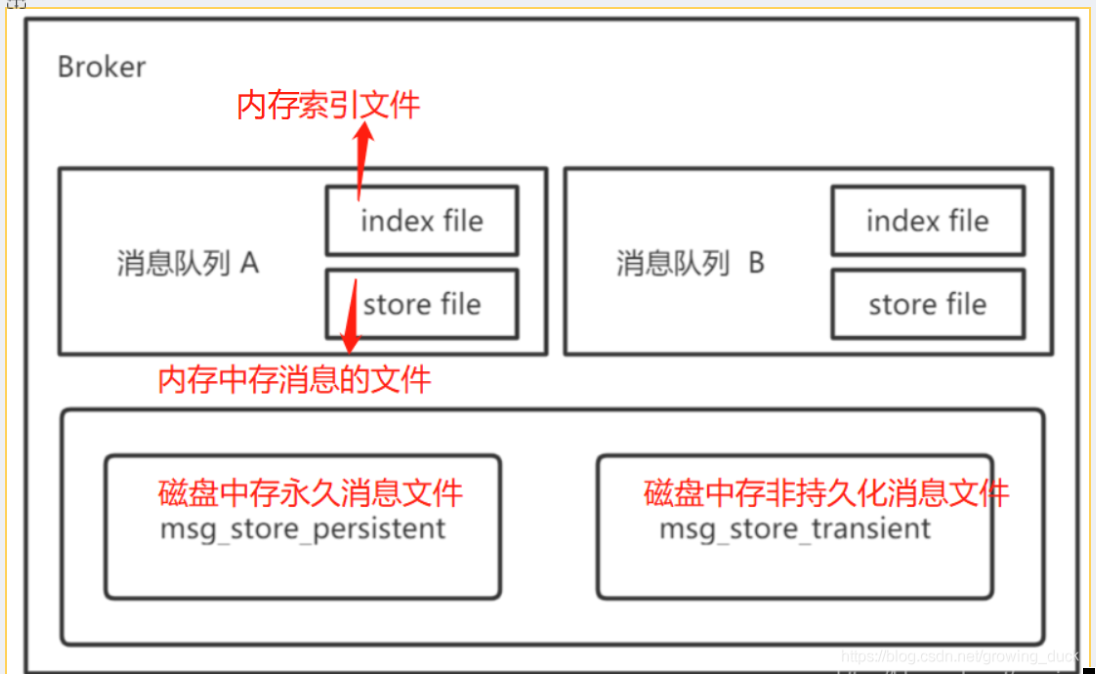
如上圖:
發送非持久化消息,會在index file維護索引,消息會存到內存的store file中,如果消息堆積內存不夠,會把消息刷到磁盤的msg_store_transient文件(當然,索引的維護也會刷盤)。
發送持久化消息,先保存到磁盤msg_store_persistent,并在內存stroe file中存儲提升性能。
隊列索引 :rabbit_queue_index (每個隊列私有) 維護落盤消息信息,如存儲地點(下面消息存儲中,消息的具體位置),是否已被消費者接收,確認消費等。 文件形式: 使用后綴為.idx的順序段文件,文件名從0開始,每個文件有N條記錄(N = segment_entry_count參數的值,默認16384)。 每個index從磁盤讀取消息時,至少要在內存中維護一個段文件。 為什么是至少呢? 因為,index所在的段文件都會加載到內存,另外,如果消息大小較小,也會直接存在索引文件中,所以可能加載的段文件中已經有需要的消息了。 那么,多小的消息,會直接放到index文件中呢? 由參數 queue_index_embed_msgs_below 決定,默認4096B。 該值設置時候一定要謹慎再謹慎,哪怕設置再大一點點,內存都可能爆炸式增長。
消息存儲:rabbit_msg_store (一個虛擬機下所有隊列共有)
存儲:鍵值對形式存儲。 rabbit_msg_store分為持久化 msg_store_transient 和非持久 msg_store_persistent 兩種,非持久化重啟服務后丟失。 文件以.rdq后綴,文件名從0開始,超過file_size_limit 的大小后創建新文件,以追加方式寫入消息。 存儲消息時會在ETS(Erlang Term Storage)表記錄 消息在文件中的位置映射和文件信息。
讀取:根據msg_id找到存儲文件,如果存在且未被鎖定,直接打開文件從指定位置讀取,發送請求由rabbit_msg_store,讓它自己來處理。
刪除:消息被消費后,不是直接刪除,而是標識為垃圾數據,后續再刪除。步驟如下: 1、刪除ETS表中的記錄,更新對應文件中的相關信息,如index文件中標識為以消費,store文件中此條信息標識為垃圾數據。 2、當一個文件中都是垃圾數據,即可刪除該文件。 但是,什么時候觸發回收刪除呢? 3、當檢測到邏輯上相鄰的兩個文件,他們的有效數據可以合并成一個文件時,并且,垃圾數據的大小超過總文件數據大小(至少3個文件)的n倍后(n是參數 GARBAGE_FACTORION的值,默認0.5),觸發合并和垃圾回收。 4、合并時,先鎖定兩個文件,分別整理前后兩個文件的有效數據,合并到前面那個文件中,刪除后面的文件,最后更新ETS記錄。 如圖: 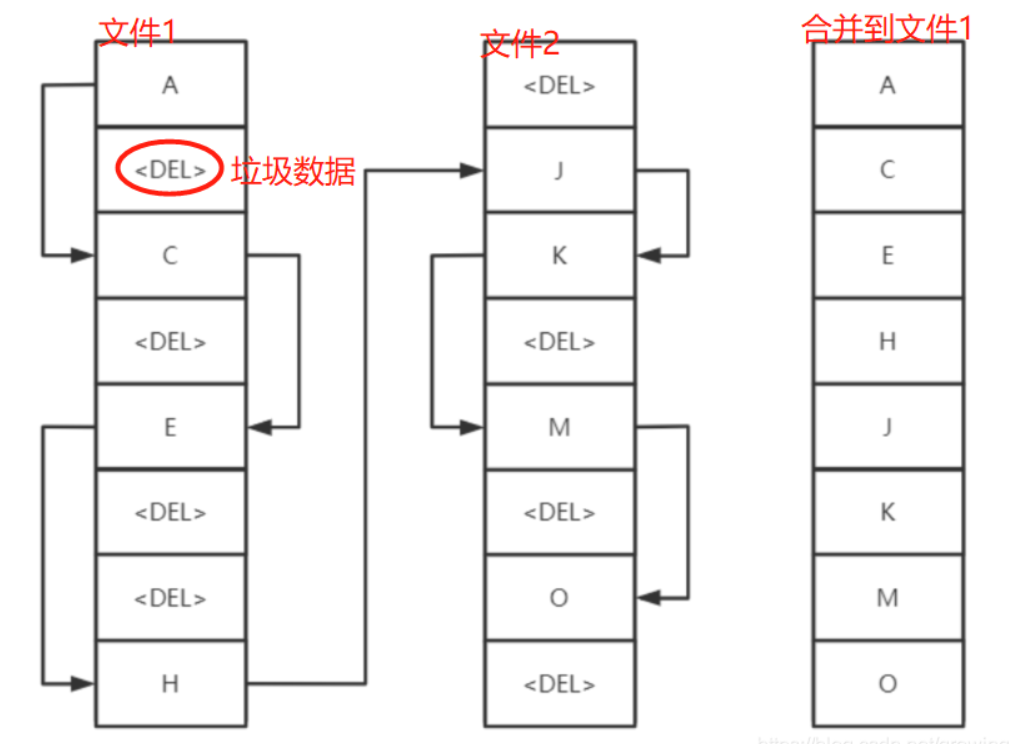
隊列結構:
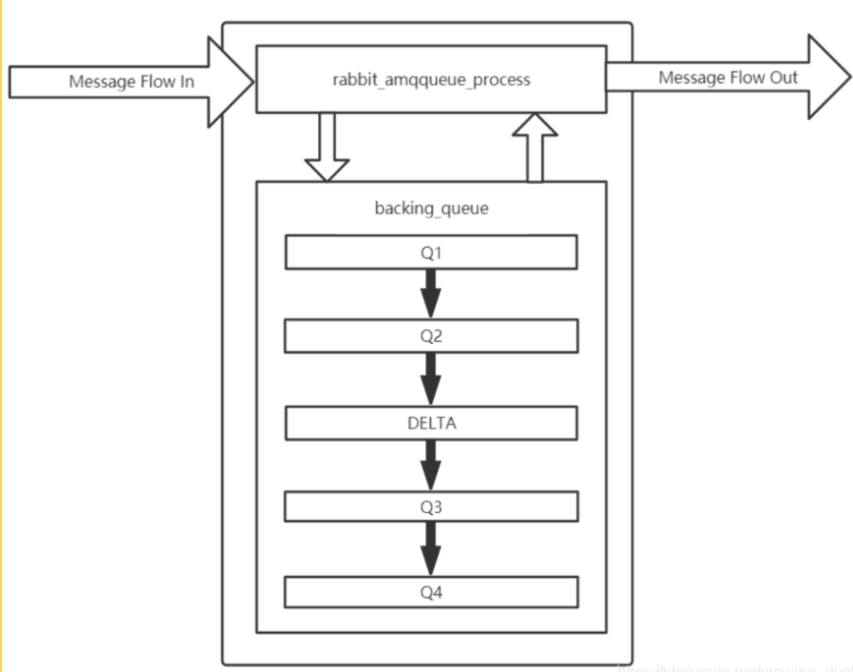
隊列由rabbit_amqqueue_process和backing_queue這兩部分組成。 rabbit_amqqueue_process 負責消息的接收,向消費者交付消息,處理消息的確認等。(處理邏輯需要調用接口) backing_queue是消息存儲的具體形式和引擎,并向rabbit_amqqueue_process提供相關的接口。 如果發送消息的目的隊列為空,且該隊列有消費者訂閱,則直接發送給消費者,否則才需要發送到隊列暫時緩存。
隊列有4種狀態:依次為 a b g d 1. alpha:索引和消息內容都存內存,最耗內存也最快,很少消耗CPU 2. beta:索引存內存,消息內存存磁盤 3. gama:索引內存和磁盤都有,消息存磁盤 4. delta:索引和內容都存磁盤,基本不消耗內存,消耗更多CPU和I/O操作 解釋: 消息存入隊列后,不是固定不變的,它會隨著系統的負載在隊列中不斷流動,消息的狀態會不斷發生變化。 持久化的消息,索引和內容都必須先保存在磁盤上,才會達到上面某種狀態。 另外,第3種狀態,持久化消息才會有。
對于普通隊列,沒有設置優先級和鏡像,backing_queue的默認實現是rabbit_variable_queue,其內部通過5個子隊列Q1、Q2、delta、Q3、Q4來體現消息的各個狀態。 其中Q1、Q4只包含alpha狀態的消息,Q2和Q3包含beta和gamma狀態的消息,Delta只包含delta狀態的消息。 常規情況消息發送到消費,按照Q1->Q2->Delta->Q3->Q4流動,經歷內存到磁盤,磁盤又到內存的過程。 如下圖:
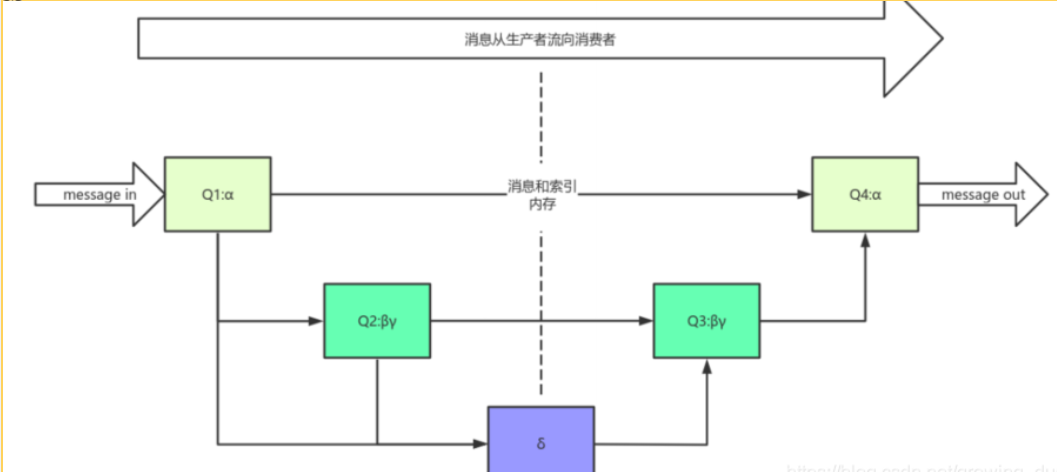
但是,并不是每一條消息都是以上的過程,會根據當前負載而變化,如下圖: 對于消息發送: 如果負載低內存充足,消息到來時,直接從Q1到Q4,不會經過磁盤(持久化消息肯定會走磁盤,但也是處于Q1->Q2->Q3->Q4) 如果負載增大,內存不夠充足,新來的消息會經歷Q1->Q2->Q3->Q4。 如果負載很大內存完全不足,新消息的索引和消息體完全存儲到磁盤,即隊列delta。
對于消息消費: 1、從Q4讀取,如果有直接返回。 2、Q4為空,讀取Q3,Q3為空返回隊列為空。 3、Q3不為空,取出Q3的消息后,判斷Q3和delta長度。 a、都為空,則認為Q2,delta,Q3,Q4全為空,將Q1的消息移動到Q4中。 b、Q3為空delta不為空,將delta消息轉移到Q3中。 轉移是按照索引文件分段讀取,先讀取第一段,判斷此段消息個數是否=delta的長度,是則代表delta可以全部轉移,此時把Q2和delta 中消息一并轉移到Q3; 否則,只會轉移delta中此次讀取到的消息。
按以上步驟得到結論: 獲取消息時候,如果Q3為空,則整個隊列為空。 原因: 消息最終是從Q4出去的,Q4為空才會到Q3去取,Q3也為空,說明上一次取消息后,已經沒有消息轉移到Q3或者Q4了。 以上流程也能解釋,為什么消息堆積會導致性能大幅度下降: 因為消息會寫入到很深的隊列中,如delta。 每次寫入和讀取都會經歷磁盤io。
以上是“rabbitMq中架構是怎么樣的”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





