溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“hadoop1存在的問題有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“hadoop1存在的問題有哪些”吧!
對 hadoop1 和 hadoop 2 做了一個解釋 圖片不錯 拿來看看
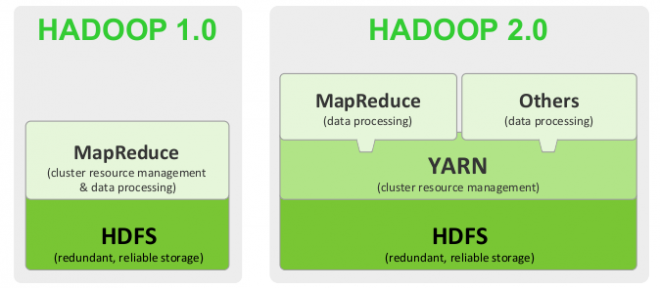
Hadoop 1.0
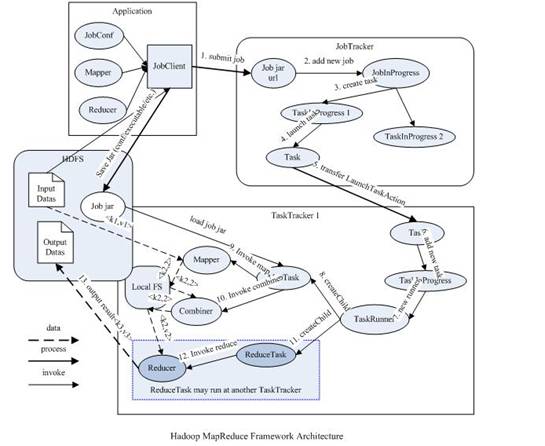
從上圖中可以清楚的看出原 MapReduce 程序的流程及設計思路:
首先用戶程序 (JobClient) 提交了一個 job,job 的信息會發送到 Job Tracker 中,Job Tracker 是 Map-reduce 框架的中心,他需要與集群中的機器定時通信 (heartbeat), 需要管理哪些程序應該跑在哪些機器上,需要管理所有 job 失敗、重啟等操作。
TaskTracker 是 Map-reduce 集群中每臺機器都有的一個部分,他做的事情主要是監視自己所在機器的資源情況。
TaskTracker 同時監視當前機器的 tasks 運行狀況。TaskTracker 需要把這些信息通過 heartbeat 發送給 JobTracker,JobTracker 會搜集這些信息以給新提交的 job 分配運行在哪些機器上。上圖虛線箭頭就是表示消息的發送 - 接收的過程。
可以看得出原來的 map-reduce 架構是簡單明了的,在最初推出的幾年,也得到了眾多的成功案例,獲得業界廣泛的支持和肯定,但隨著分布式系統集群的規模和其工作負荷的增長,原框架的問題逐漸浮出水面,主要的問題集中如下:
JobTracker 是 Map-reduce 的集中處理點,存在單點故障。
JobTracker 完成了太多的任務,造成了過多的資源消耗,當 map-reduce job 非常多的時候,會造成很大的內存開銷,潛在來說,也增加了 JobTracker fail 的風險,這也是業界普遍總結出老 Hadoop 的 Map-Reduce 只能支持 4000 節點主機的上限。
在 TaskTracker 端,以 map/reduce task 的數目作為資源的表示過于簡單,沒有考慮到 cpu/ 內存的占用情況,如果兩個大內存消耗的 task 被調度到了一塊,很容易出現 OOM。
在 TaskTracker 端,把資源強制劃分為 map task slot 和 reduce task slot, 如果當系統中只有 map task 或者只有 reduce task 的時候,會造成資源的浪費,也就是前面提過的集群資源利用的問題。
源代碼層面分析的時候,會發現代碼非常的難讀,常常因為一個 class 做了太多的事情,代碼量達 3000 多行,,造成 class 的任務不清晰,增加 bug 修復和版本維護的難度。
從操作的角度來看,現在的 Hadoop MapReduce 框架在有任何重要的或者不重要的變化 ( 例如 bug 修復,性能提升和特性化 ) 時,都會強制進行系統級別的升級更新。更糟的是,它不管用戶的喜好,強制讓分布式集群系統的每一個用戶端同時更新。這些更新會讓用戶為了驗證他們之前的應用程序是不是適用新的 Hadoop 版本而浪費大量時間。
hadoop2.0:
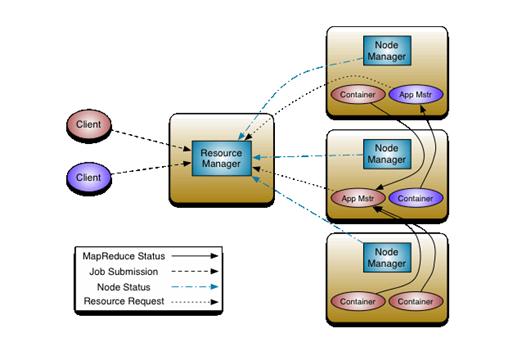
從業界使用分布式系統的變化趨勢和 hadoop 框架的長遠發展來看,MapReduce 的 JobTracker/TaskTracker 機制需要大規模的調整來修復它在可擴展性,內存消耗,線程模型,可靠性和性能上的缺陷。在過去的幾年中,hadoop 開發團隊做了一些 bug 的修復,但是最近這些修復的成本越來越高,這表明對原框架做出改變的難度越來越大。
為從根本上解決舊 MapReduce 框架的性能瓶頸,促進 Hadoop 框架的更長遠發展,從 0.23.0 版本開始,Hadoop 的 MapReduce 框架完全重構,發生了根本的變化。新的 Hadoop MapReduce 框架命名為 MapReduceV2 或者叫 Yarn,
重構根本的思想是將 JobTracker 兩個主要的功能分離成單獨的組件,這兩個功能是資源管理和任務調度 / 監控。新的資源管理器全局管理所有應用程序計算資源的分配,每一個應用的 ApplicationMaster 負責相應的調度和協調。一個應用程序無非是一個單獨的傳統的 MapReduce 任務或者是一個 DAG( 有向無環圖 ) 任務。ResourceManager 和每一臺機器的節點管理服務器能夠管理用戶在那臺機器上的進程并能對計算進行組織。
事實上,每一個應用的 ApplicationMaster 是一個詳細的框架庫,它結合從 ResourceManager 獲得的資源和 NodeManager 協同工作來運行和監控任務。
上圖中 ResourceManager 支持分層級的應用隊列,這些隊列享有集群一定比例的資源。從某種意義上講它就是一個純粹的調度器,它在執行過程中不對應用進行監控和狀態跟蹤。同樣,它也不能重啟因應用失敗或者硬件錯誤而運行失敗的任務。
ResourceManager 是基于應用程序對資源的需求進行調度的 ; 每一個應用程序需要不同類型的資源因此就需要不同的容器。資源包括:內存,CPU,磁盤,網絡等等。可以看出,這同現 Mapreduce 固定類型的資源使用模型有顯著區別,它給集群的使用帶來負面的影響。資源管理器提供一個調度策略的插件,它負責將集群資源分配給多個隊列和應用程序。調度插件可以基于現有的能力調度和公平調度模型。
上圖中 NodeManager 是每一臺機器框架的代理,是執行應用程序的容器,監控應用程序的資源使用情況 (CPU,內存,硬盤,網絡 ) 并且向調度器匯報。
每一個應用的 ApplicationMaster 的職責有:向調度器索要適當的資源容器,運行任務,跟蹤應用程序的狀態和監控它們的進程,處理任務的失敗原因。
感謝各位的閱讀,以上就是“hadoop1存在的問題有哪些”的內容了,經過本文的學習后,相信大家對hadoop1存在的問題有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





