溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“hadoop2.7+Spark1.4環境如何搭建”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“hadoop2.7+Spark1.4環境如何搭建”這篇文章吧。
其實官網有比較詳實的說明,英語好的可以直接看官網,地址
這個省略,官網顯示1.6可以,但是我用openjdk1.6出了異常,JDK1.6沒試,直接用了JDK1.7
配置好環境變量
vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.7.0_79 export CLASSPATH=.:$JAVE_HOME/lib.tools.jar export PATH=$PATH:$JAVA_HOME/bin
添加完后執行命令使配置生效
source /etc/profile
$ sudo apt-get install ssh $ sudo apt-get install rsync
查是32還是64位的辦法
cd hadoop-2.7.0/lib/native file libhadoop.so.1.0.0
hadoop-2.7.0/lib/native/libhadoop.so.1.0.0: ELF 64-bit LSB shared object, AMD x86-64, version 1 (SYSV), not stripped
hadoop配置文件指定java路徑
etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.7.0_79
系統環境變量
export HADOOP_HOME=/usr/local/hadoop-2.7.0 export PATH=$PATH:$HADOOP_HOME/bin export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
后兩條不加會出現
You have loaded library /usr/hadoop/hadoop-2.7.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
添加完后執行命令使配置生效
source /etc/profile
執行命令查看是否成功
hadoop version
etc/hadoop/core-site.xml:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
etc/hadoop/hdfs-site.xml:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys $ export HADOOP\_PREFIX=/usr/local/hadoop-2.7.0
$ bin/hdfs namenode -format $ sbin/start-dfs.sh
打開瀏覽器 http://localhost:50070/看是否成功
hdfs配置:username最好和當前用戶名相同,不然會可能出現權限問題
$ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/<username>
etc/hadoop/mapred-site.xml:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
etc/hadoop/yarn-site.xml:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
啟動yarn
$ sbin/start-yarn.sh
http://localhost:8088/查看是否成功
至此hadoop單節點偽分布式安裝配置完成
spark的安裝相對就要簡單多了
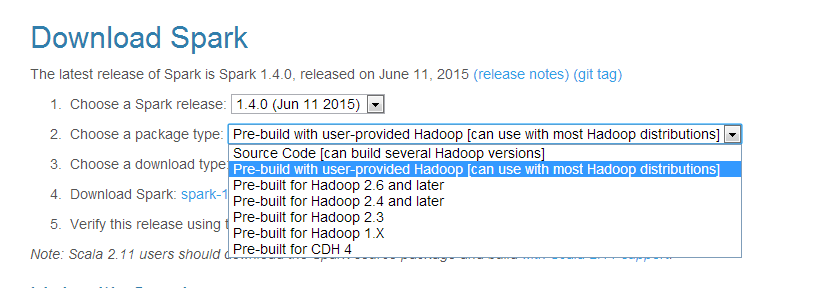
因為我之前已經有hadoop了所以選擇第二個下載
cd conf cp spark-env.sh.template spark-env.sh cp spark-defaults.conf.template spark-defaults.conf vi conf/spark-env.sh
最后添加
export HADOOP_HOME=/usr/local/hadoop-2.7.0 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_DIST_CLASSPATH=$(hadoop classpath)
最后一個需要hadoop添加了環境變量才行。
官網配置中沒有前兩個配置,我運行例子時總報錯,找不到hdfs jar 包。
./bin/run-example SparkPi 10
成功則到此配置完成
以上是“hadoop2.7+Spark1.4環境如何搭建”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





