溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“HBase ROOT和META表結構是怎樣的”,在日常操作中,相信很多人在HBase ROOT和META表結構是怎樣的問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”HBase ROOT和META表結構是怎樣的”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
在此基礎上我們引入兩個特殊的概念:-ROOT-和.META.。這是什么?它們是HBase的兩張內置表,從存儲結構和操作方法的角度來說,它們和其他HBase的表沒有任何區別,你可以認為這就是兩張普通的表,對于普通表的操作對它們都適用。它們與眾不同的地方是HBase用它們來存貯一個重要的系統信息——Region的分布情況以及每個Region的詳細信息。
好了,既然我們前面說到-ROOT-和.META.可以被看作是兩張普通的表,那么它們和其他表一樣就應該有自己的表結構。沒錯,它們有自己的表結構,并且這兩張表的表結構是相同的,在分析源碼之后我將這個表結構大致的畫了出來:
-ROOT-和.META.表結構
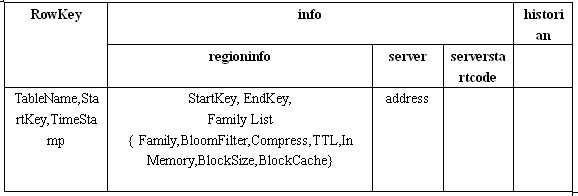
我們來仔細分析一下這個結構,每條Row記錄了一個Region的信息。
首先是RowKey,RowKey由三部分組成:TableName, StartKey 和 TimeStamp。RowKey存儲的內容我們又稱之為Region的Name。哦,還記得嗎?我們在前面的文章中提到的,用來存放Region的文件夾的名字是RegionName的Hash值,因為RegionName可能包含某些非法字符。現在你應該知道為什么RegionName會包含非法字符了吧,因為StartKey是被允許包含任何值的。將組成RowKey的三個部分用逗號連接就構成了整個RowKey,這里TimeStamp使用十進制的數字字符串來表示的。這里有一個RowKey的例子:
Java代碼

Table1,RK10000,12345678
然后是表中最主要的Family:info,info里面包含三個Column:regioninfo, server, serverstartcode。其中regioninfo就是Region的詳細信息,包括StartKey, EndKey 以及每個Family的信息等等。server存儲的就是管理這個Region的RegionServer的地址。
所以當Region被拆分、合并或者重新分配的時候,都需要來修改這張表的內容。
到目前為止我們已經學習了必須的背景知識,下面我們要正式開始介紹Client端尋找RegionServer的整個過程。我打算用一個假想的例子來學習這個過程,因此我先構建了假想的-ROOT-表和.META.表。
我們先來看.META.表,假設HBase中只有兩張用戶表:Table1和Table2,Table1非常大,被劃分成了很多Region,因此在.META.表中有很多條Row用來記錄這些Region。而Table2很小,只是被劃分成了兩個Region,因此在.META.中只有兩條Row用來記錄。這個表的內容看上去是這個樣子的:
.META.行記錄結構

這么一來Client端就需要先去訪問-ROOT-表。所以需要知道管理-ROOT-表的RegionServer的地址。這個地址被存在ZooKeeper中。默認的路徑是:
Java代碼
/hbase/root-region-server
等等,如果-ROOT-表太大了,要被分成多個Region怎么辦?嘿嘿,HBase認為-ROOT-表不會大到那個程度,因此-ROOT-只會有一個Region,這個Region的信息也是被存在HBase內部的。
現在讓我們從頭來過,我們要查詢Table2中RowKey是RK10000的數據。整個路由過程的主要代碼在org.apache.hadoop.hbase.client.HConnectionManager.TableServers中:
Java代碼
private HRegionLocation locateRegion(final byte[] tableName,
final byte[] row, boolean useCache) throws IOException {
if (tableName == null || tableName.length == 0) {
throw new IllegalArgumentException("table name cannot be null or zero length");
}
if (Bytes.equals(tableName, ROOT_TABLE_NAME)) {
synchronized (rootRegionLock) {
// This block guards against two threads trying to find the root
// region at the same time. One will go do the find while the
// second waits. The second thread will not do find.
if (!useCache || rootRegionLocation == null) {
this.rootRegionLocation = locateRootRegion();
}
return this.rootRegionLocation;
}
} else if (Bytes.equals(tableName, META_TABLE_NAME)) {
return locateRegionInMeta(ROOT_TABLE_NAME, tableName, row, useCache, metaRegionLock);
} else {
// Region not in the cache – have to go to the meta RS
return locateRegionInMeta(META_TABLE_NAME, tableName, row, useCache, userRegionLock);
}
}
這是一個遞歸調用的過程:
Java代碼
獲取Table2,RowKey為RK10000的RegionServer => 獲取.META.,RowKey為Table2,RK10000, 99999999999999的RegionServer => 獲取-ROOT-,RowKey為.META.,Table2,RK10000,99999999999999,99999999999999的RegionServer => 獲取-ROOT-的RegionServer => 從ZooKeeper得到-ROOT-的RegionServer => 從-ROOT-表中查到RowKey最接近(小于) .META.,Table2,RK10000,99999999999999,99999999999999的一條Row,并得到.META.的RegionServer => 從.META.表中查到RowKey最接近(小于)Table2,RK10000, 99999999999999的一條Row,并得到Table2的RegionServer => 從Table2中查到RK10000的Row
到此為止Client完成了路由RegionServer的整個過程,在整個過程中使用了添加“99999999999999”后綴并查找最接近(小于)RowKey的方法。對于這個方法大家可以仔細揣摩一下,并不是很難理解。
最后要提醒大家注意兩件事情:
1. 在整個路由過程中并沒有涉及到MasterServer,也就是說HBase日常的數據操作并不需要MasterServer,不會造成MasterServer的負擔。
2. Client端并不會每次數據操作都做這整個路由過程,很多數據都會被Cache起來。至于如何Cache,則不在本文的討論范圍之內。
到此,關于“HBase ROOT和META表結構是怎樣的”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





