溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關HDFS體系結構中有哪幾類節點的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
HDFS體系結構中有兩類節點,一類是NameNode,又叫"元數據節點";另一類是DataNode,又叫"數據節點"。這兩類節點分別承擔Master和Worker具體任務的執行節點。
1)元數據節點用來管理文件系統的命名空間
其將所有的文件和文件夾的元數據保存在一個文件系統樹中。
這些信息也會在硬盤上保存成以下文件:命名空間鏡像(namespace image)及修改日志(edit log)
其還保存了一個文件包括哪些數據塊,分布在哪些數據節點上。然而這些信息并不存儲在硬盤上,而是在系統啟動的時候從數據節點收集而成的。
2)數據節點是文件系統中真正存儲數據的地方。
客戶端(client)或者元數據信息(namenode)可以向數據節點請求寫入或者讀出數據塊。
其周期性的向元數據節點回報其存儲的數據塊信息。
3)從元數據節點(secondary namenode)
從元數據節點并不是元數據節點出現問題時候的備用節點,它和元數據節點負責不同的事情。
其主要功能就是周期性將元數據節點的命名空間鏡像文件和修改日志合并,以防日志文件過大。這點在下面會相信敘述。
合并過后的命名空間鏡像文件也在從元數據節點保存了一份,以防元數據節點失敗的時候,可以恢復。
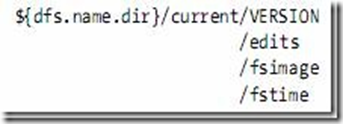
VERSION文件是java properties文件,保存了HDFS的版本號。
namespaceID=1232737062
cTime=0
storageType=NAME_NODE
layoutVersion=-18
HDFS是一個主/從(Mater/Slave)體系結構,從最終用戶的角度來看,它就像傳統的文件系統一樣,可以通過目錄路徑對文件執行CRUD(Create、Read、Update和Delete)操作。但由于分布式存儲的性質,HDFS集群擁有一個NameNode和一些DataNode。NameNode管理文件系統的元數據,DataNode存儲實際的數據。客戶端通過同NameNode和DataNodes的交互訪問文件系統。客戶端聯系NameNode以獲取文件的元數據,而真正的文件I/O操作是直接和DataNode進行交互的。

圖5-1-1 列出HDFS文件
2)列出HDFS目錄下某個文檔中的文件
此處為你展示如何通過"-ls 文件名"命令瀏覽HDFS下名為"input"的文檔中文件:
hadoop fs –ls input
執行結果如圖5-1-2所示。

圖5-1-3 成功上傳file到HDFS
4)將HDFS中文件復制到本地系統中
此處為你展示如何通過"-get 文件1 文件2"命令將HDFS中的"output"文件復制到本地系統并命名為"getout"。
hadoop fs –get output getout
執行結果如圖5-1-4所示。
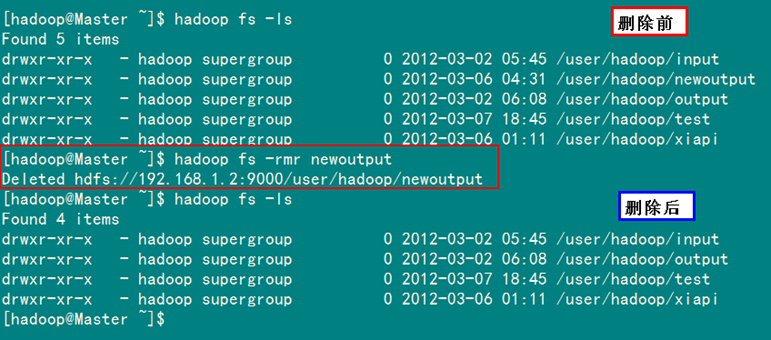
圖5-1-5 成功刪除HDFS下的newoutput文檔
6)查看HDFS下某個文件
此處為你展示如何通過"-cat 文件"命令查看HDFS下input文件中內容:
hadoop fs -cat input/*
執行結果如圖5-1-6所示。
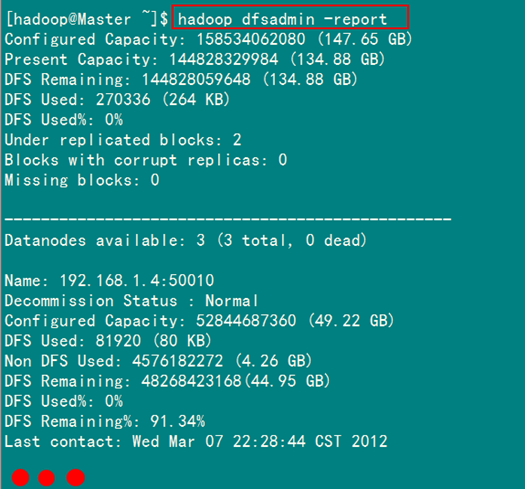
圖5-2-1 HDFS基本統計信息
2)退出安全模式
NameNode在啟動時會自動進入安全模式。安全模式是NameNode的一種狀態,在這個階段,文件系統不允許有任何修改。安全模式的目的是在系統啟動時檢查各個DataNode上數據塊的有效性,同時根據策略對數據塊進行必要的復制或刪除,當數據塊最小百分比數滿足的最小副本數條件時,會自動退出安全模式。
系統顯示"Name node is in safe mode",說明系統正處于安全模式,這時只需要等待17秒即可,也可以通過下面的命令退出安全模式:
hadoop dfsadmin –safemode enter
成功退出安全模式結果如圖5-2-2所示。

圖5-2-3 進入HDFS安全模式
4)添加節點
可擴展性是HDFS的一個重要特性,向HDFS集群中添加節點是很容易實現的。添加一個新的DataNode節點,首先在新加節點上安裝好Hadoop,要和NameNode使用相同的配置(可以直接從NameNode復制),修改"/usr/hadoop/conf/master"文件,加入NameNode主機名。然后在NameNode節點上修改"/usr/hadoop/conf/slaves"文件,加入新節點主機名,再建立到新加點無密碼的SSH連接,運行啟動命令:
start-all.sh
5)負載均衡
HDFS的數據在各個DataNode中的分布肯能很不均勻,尤其是在DataNode節點出現故障或新增DataNode節點時。新增數據塊時NameNode對DataNode節點的選擇策略也有可能導致數據塊分布的不均勻。用戶可以使用命令重新平衡DataNode上的數據塊的分布:
start-balancer.sh
執行命令前,DataNode節點上數據分布情況如圖5-2-4所示。
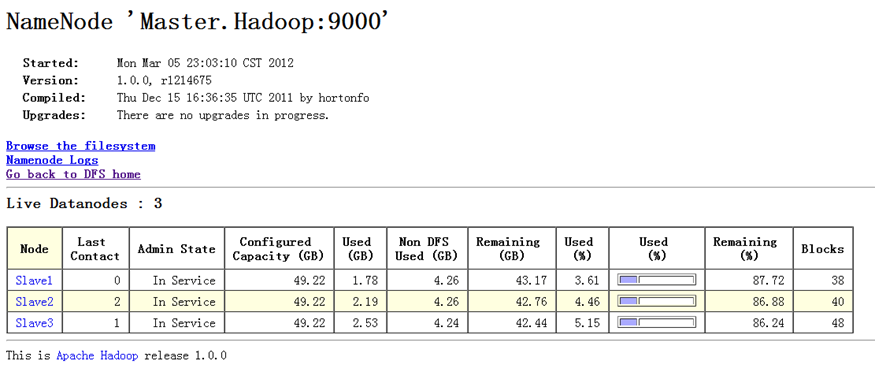
執行負載均衡命令如圖5-2-6所示。

圖6-1-1 運行結果(1)
2)項目瀏覽器
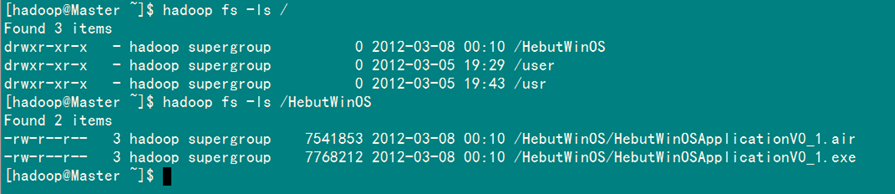
圖6-1-3 運行結果(3)
通過"FileSystem.create(Path f)"可在HDFS上創建文件,其中f為文件的完整路徑。具體實現如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
byte[] buff="hello hadoop world!\n".getBytes();
Path dfs=new Path("/test");
FSDataOutputStream outputStream=hdfs.create(dfs);
outputStream.write(buff,0,buff.length);
}
}
運行結果如圖6-2-1和圖6-2-2所示。
1)項目瀏覽器
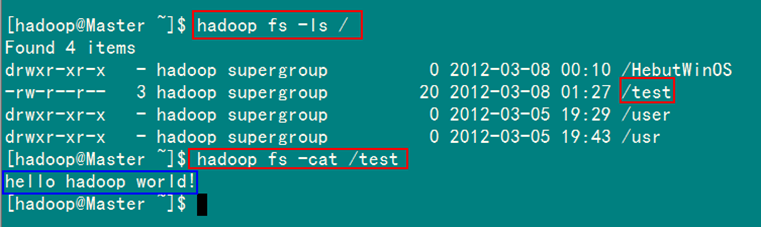
圖6-2-2 運行結果(2)
通過"FileSystem.mkdirs(Path f)"可在HDFS上創建文件夾,其中f為文件夾的完整路徑。具體實現如下:
package com.hebut.dir;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateDir {
public static void main(String[] args) throws Exception{
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path dfs=new Path("/TestDir");
hdfs.mkdirs(dfs);
}
}
運行結果如圖6-3-1和圖6-3-2所示。
1)項目瀏覽器
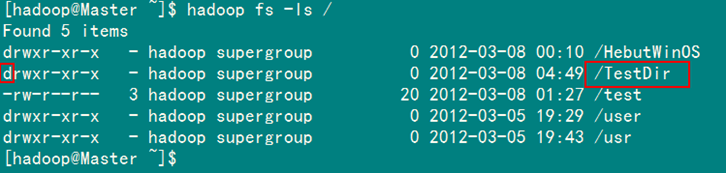
圖6-3-2 運行結果(2)
通過"FileSystem.rename(Path src,Path dst)"可為指定的HDFS文件重命名,其中src和dst均為文件的完整路徑。具體實現如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Rename{
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path frpaht=new Path("/test"); //舊的文件名
Path topath=new Path("/test1"); //新的文件名
boolean isRename=hdfs.rename(frpaht, topath);
String result=isRename?"成功":"失敗";
System.out.println("文件重命名結果為:"+result);
}
}
運行結果如圖6-4-1和圖6-4-2所示。
1)項目瀏覽器
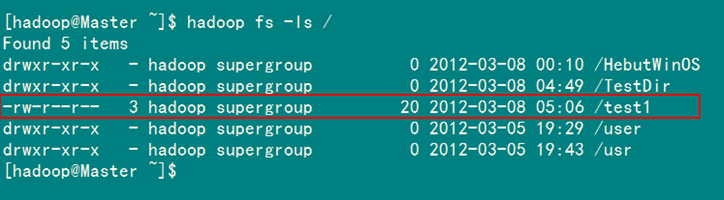
圖6-4-2 運行結果(2)
通過"FileSystem.delete(Path f,Boolean recursive)"可刪除指定的HDFS文件,其中f為需要刪除文件的完整路徑,recuresive用來確定是否進行遞歸刪除。具體實現如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class DeleteFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path delef=new Path("/test1");
boolean isDeleted=hdfs.delete(delef,false);
//遞歸刪除
//boolean isDeleted=hdfs.delete(delef,true);
System.out.println("Delete?"+isDeleted);
}
}
運行結果如圖6-5-1和圖6-5-2所示。
1)控制臺結果
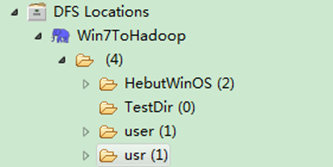
圖6-5-2 運行結果(2)
同刪除文件代碼一樣,只是換成刪除目錄路徑即可,如果目錄下有文件,要進行遞歸刪除。
通過"FileSystem.exists(Path f)"可查看指定HDFS文件是否存在,其中f為文件的完整路徑。具體實現如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CheckFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path findf=new Path("/test1");
boolean isExists=hdfs.exists(findf);
System.out.println("Exist?"+isExists);
}
}
運行結果如圖6-7-1和圖6-7-2所示。
1)控制臺結果
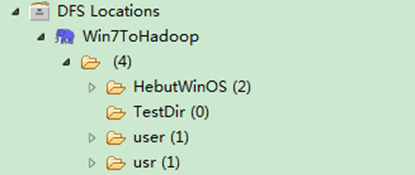
圖6-7-2 運行結果(2)
通過"FileSystem.getModificationTime()"可查看指定HDFS文件的修改時間。具體實現如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class GetLTime {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path fpath =new Path("/user/hadoop/test/file1.txt");
FileStatus fileStatus=hdfs.getFileStatus(fpath);
long modiTime=fileStatus.getModificationTime();
System.out.println("file1.txt的修改時間是"+modiTime);
}
}
運行結果如圖6-8-1所示。

圖6-9-1 運行結果(1)
2)項目瀏覽器

圖6-10-1 運行結果(1)
2)項目瀏覽器
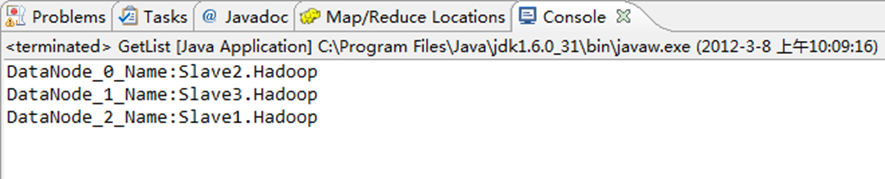
圖6-11-1 控制臺結果
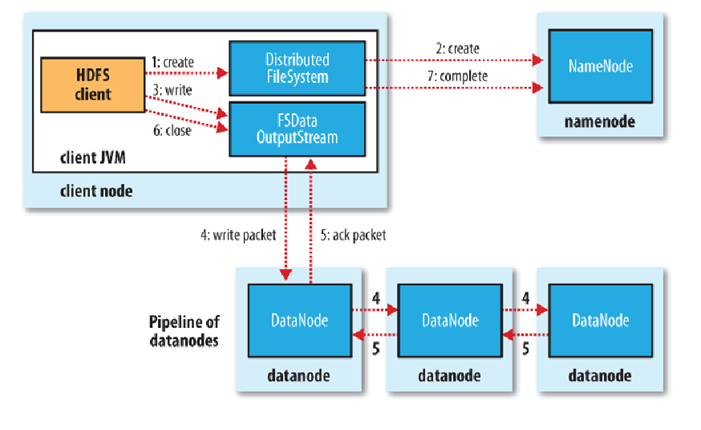
寫入文件的過程比讀取較為復雜:
1)解釋一
2)解釋二
使用HDFS提供的客戶端開發庫,向遠程的Namenode發起RPC請求;
Namenode會檢查要創建的文件是否已經存在,創建者是否有權限進行操作,成功則會為文件創建一個記錄,否則會讓客戶端拋出異常;
當客戶端開始寫入文件的時候,開發庫會將文件切分成多個packets,并在內部以"data queue"的形式管理這些packets,并向Namenode申請新的blocks,獲取用來存儲replicas的合適的datanodes列表,列表的大小根據在Namenode中對replication的設置而定。
開始以pipeline(管道)的形式將packet寫入所有的replicas中。開發庫把packet以流的方式寫入第一個datanode,該datanode把該packet存儲之后,再將其傳遞給在此pipeline中的下一個datanode,直到最后一個datanode,這種寫數據的方式呈流水線的形式。
最后一個datanode成功存儲之后會返回一個ack packet,在pipeline里傳遞至客戶端,在客戶端的開發庫內部維護著"ack queue",成功收到datanode返回的ack packet后會從"ack queue"移除相應的packet。
如果傳輸過程中,有某個datanode出現了故障,那么當前的pipeline會被關閉,出現故障的datanode會從當前的pipeline中移除,剩余的block會繼續剩下的datanode中繼續以pipeline的形式傳輸,同時Namenode會分配一個新的datanode,保持replicas設定的數量。
關閉pipeline,將ack queue中的數據塊放入data queue的開始。
當前的數據塊在已經寫入的數據節點中被元數據節點賦予新的標示,則錯誤節點重啟后能夠察覺其數據塊是過時的,會被刪除。
失敗的數據節點從pipeline中移除,另外的數據塊則寫入pipeline中的另外兩個數據節點。
元數據節點則被通知此數據塊是復制塊數不足,將來會再創建第三份備份。
客戶端調用create()來創建文件
DistributedFileSystem用RPC調用元數據節點,在文件系統的命名空間中創建一個新的文件。
元數據節點首先確定文件原來不存在,并且客戶端有創建文件的權限,然后創建新文件。
DistributedFileSystem返回DFSOutputStream,客戶端用于寫數據。
客戶端開始寫入數據,DFSOutputStream將數據分成塊,寫入data queue。
Data queue由Data Streamer讀取,并通知元數據節點分配數據節點,用來存儲數據塊(每塊默認復制3塊)。分配的數據節點放在一個pipeline里。
Data Streamer將數據塊寫入pipeline中的第一個數據節點。第一個數據節點將數據塊發送給第二個數據節點。第二個數據節點將數據發送給第三個數據節點。
DFSOutputStream為發出去的數據塊保存了ack queue,等待pipeline中的數據節點告知數據已經寫入成功。
如果數據節點在寫入的過程中失敗:
當客戶端結束寫入數據,則調用stream的close函數。此操作將所有的數據塊寫入pipeline中的數據節點,并等待ack queue返回成功。最后通知元數據節點寫入完畢。
使用HDFS提供的客戶端開發庫,向遠程的Namenode發起RPC請求;
Namenode會視情況返回文件的部分或者全部block列表,對于每個block,Namenode都會返回有該block拷貝的datanode地址;
客戶端開發庫會選取離客戶端最接近的datanode來讀取block;
讀取完當前block的數據后,關閉與當前的datanode連接,并為讀取下一個block尋找最佳的datanode;
當讀完列表的block后,且文件讀取還沒有結束,客戶端開發庫會繼續向Namenode獲取下一批的block列表。
讀取完一個block都會進行checksum驗證,如果讀取datanode時出現錯誤,客戶端會通知Namenode,然后再從下一個擁有該block拷貝的datanode繼續讀。
客戶端(client)用FileSystem的open()函數打開文件。
DistributedFileSystem用RPC調用元數據節點,得到文件的數據塊信息。
對于每一個數據塊,元數據節點返回保存數據塊的數據節點的地址。
DistributedFileSystem返回FSDataInputStream給客戶端,用來讀取數據。
客戶端調用stream的read()函數開始讀取數據。
DFSInputStream連接保存此文件第一個數據塊的最近的數據節點。
Data從數據節點讀到客戶端(client)。
當此數據塊讀取完畢時,DFSInputStream關閉和此數據節點的連接,然后連接此文件下一個數據塊的最近的數據節點。
當客戶端讀取完畢數據的時候,調用FSDataInputStream的close函數。
在讀取數據的過程中,如果客戶端在與數據節點通信出現錯誤,則嘗試連接包含此數據塊的下一個數據節點。
失敗的數據節點將被記錄,以后不再連接。
利用SequenceFile、MapFile、Har等方式歸檔小文件,這個方法的原理就是把小文件歸檔起來管理,HBase就是基于此的。對于這種方法,如果想找回原來的小文件內容,那就必須得知道與歸檔文件的映射關系。
橫向擴展,一個Hadoop集群能管理的小文件有限,那就把幾個Hadoop集群拖在一個虛擬服務器后面,形成一個大的Hadoop集群。google也是這么干過的。
多Master設計,這個作用顯而易見了。正在研發中的GFS II也要改為分布式多Master設計,還支持Master的Failover,而且Block大小改為1M,有意要調優處理小文件啊。
附帶個Alibaba DFS的設計,也是多Master設計,它把Metadata的映射存儲和管理分開了,由多個Metadata存儲節點和一個查詢Master節點組成。
Client向NameNode發起文件讀取的請求。
NameNode返回文件存儲的DataNode的信息。
Client讀取文件信息。
Client向NameNode發起文件寫入的請求。
NameNode根據文件大小和文件塊配置情況,返回給Client它所管理部分DataNode的信息。
Client將文件劃分為多個Block,根據DataNode的地址信息,按順序寫入到每一個DataNode塊中。
NameNode可以看作是分布式文件系統中的管理者,主要負責管理文件系統的命名空間、集群配置信息和存儲塊的復制等。NameNode會將文件系統的Meta-data存儲在內存中,這些信息主要包括了文件信息、每一個文件對應的文件塊的信息和每一個文件塊在DataNode的信息等。
DataNode是文件存儲的基本單元,它將Block存儲在本地文件系統中,保存了Block的Meta-data,同時周期性地將所有存在的Block信息發送給NameNode。
Client就是需要獲取分布式文件系統文件的應用程序。
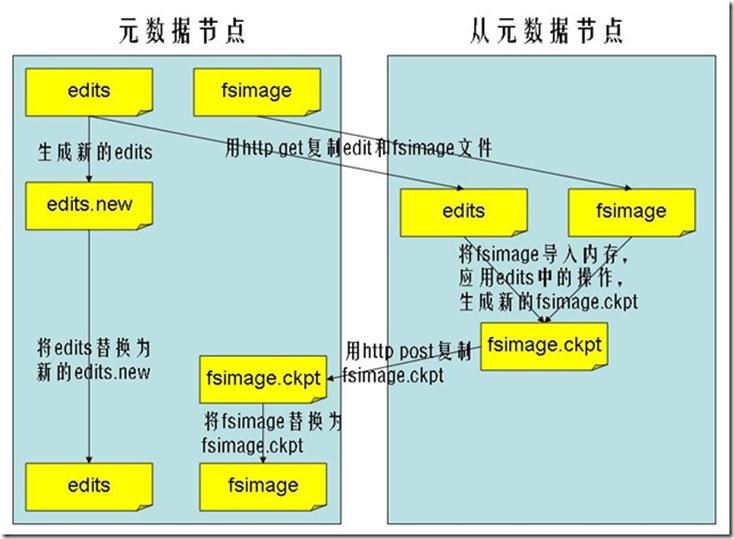
從元數據節點通知元數據節點生成新的日志文件,以后的日志都寫到新的日志文件中。
從元數據節點用http get從元數據節點獲得fsimage文件及舊的日志文件。
從元數據節點將fsimage文件加載到內存中,并執行日志文件中的操作,然后生成新的fsimage文件。
從元數據節點獎新的fsimage文件用http post傳回元數據節點
元數據節點可以將舊的fsimage文件及舊的日志文件,換為新的fsimage文件和新的日志文件(第一步生成的),然后更新fstime文件,寫入此次checkpoint的時間。
這樣元數據節點中的fsimage文件保存了最新的checkpoint的元數據信息,日志文件也重新開始,不會變的很大了。
當文件系統客戶端(client)進行寫操作時,首先把它記錄在修改日志中(edit log)
元數據節點在內存中保存了文件系統的元數據信息。在記錄了修改日志后,元數據節點則修改內存中的數據結構。
每次的寫操作成功之前,修改日志都會同步(sync)到文件系統。
fsimage文件,也即命名空間映像文件,是內存中的元數據在硬盤上的checkpoint,它是一種序列化的格式,并不能夠在硬盤上直接修改。
同數據的機制相似,當元數據節點失敗時,則最新checkpoint的元數據信息從fsimage加載到內存中,然后逐一重新執行修改日志中的操作。
從元數據節點就是用來幫助元數據節點將內存中的元數據信息checkpoint到硬盤上的
checkpoint的過程如下:
blk_<id>保存的是HDFS的數據塊,其中保存了具體的二進制數據。
blk_<id>.meta保存的是數據塊的屬性信息:版本信息,類型信息,和checksum
當一個目錄中的數據塊到達一定數量的時候,則創建子文件夾來保存數據塊及數據塊屬性信息。
數據節點的VERSION文件格式如下:
layoutVersion是一個負整數,保存了HDFS的持續化在硬盤上的數據結構的格式版本號。
namespaceID是文件系統的唯一標識符,是在文件系統初次格式化時生成的。
cTime此處為0
storageType表示此文件夾中保存的是元數據節點的數據結構。
感謝各位的閱讀!關于“HDFS體系結構中有哪幾類節點”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





