溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Hadoop架構以及偽分布式安裝的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
Hadoop:一個分布式系統基礎架構,適合大數據的分布式存儲與計算平臺。兩個核心項目:HDFS、MapReduce
HDFS:分布式文件系統,主要解決分布式的存儲問題。
MapReduce:并行計算框架,主要解決分布式的計算問題。
Hadoop的特點:高可靠、高擴展、高性能、高容錯、低成本
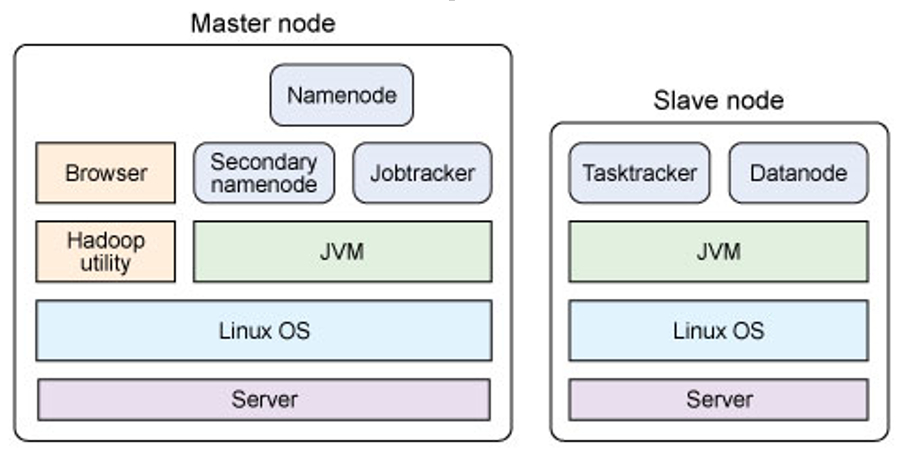
Hadoop架構:
在MapReduce中一個準備提交的應用程序成為作業(job),從一個作業劃分出的、運行于各計算節點的工作單位成為任務(task);
Hadoop提供的分布式文件系統(HDFS)主要負責各個節點上的數據存儲,實現高吞吐率的數據讀寫。
Hadoop使用Master/Slave架構。
以HDFS角度看(一個文件會被分割成若干個默認64M的block):
主節點(只有一個): namenode。接受用戶數據、維護文件系統的目錄結構、管理文件與block和block與 datanode之間的關系。
從節點(若干個): datanode。存儲block,為保證數據安全會有備份。
以MapReduce角度看:
主節點(只有一個): JobTracker。接受客戶提交的服務任務、將任務分配給TaskTracker執行、監控 TaskTracker執行情況。
從節點(有很多個); TaskTracker。執行JobTracker分配的計算任務。
安裝虛擬機(網絡設置為host-only)
設置靜態IP(使宿主機與虛擬機位于同一網段)
修改主機名、綁定主機名與IP
修改主機名:配置文件位于/etc/sysconfig/network
綁定主機與IP:配置文件位于/etc/hosts
重啟
關閉防火墻及自動啟動
查看防火墻狀態:service iptables status
關閉防火墻:service iptables stop
查看防火墻運行級別:chkconfig | grep iptables
關閉防火墻自動啟動:chkconfig iptables off
配置SSH免密碼登陸
以rsa加密算法產生密鑰:ssh-keygen -t rsa(產生的密碼位于~/.shh)
拷貝id_rsa.pub:cp id_rsa.pub authorized_keys
驗證(免密碼登陸本機):ssh locahost
安裝JDK
復制JDK到安裝目錄(我選擇安裝到/usr/local/jdk。注意與JDK環境變量,Hadoop配置中的設置保持一致)
對JDK安裝文件添加執行權限:chmod u+x jdk.....bin
解壓縮:./jdk.....bin
重命名安裝目錄:mv jdk...... jdk
添加環境變量:配置文件位于/etc/profile
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
更改立即生效:source /etc/profile
驗證:java -version
安裝Hadoop
復制hadoop安裝包到安裝目錄
解壓hadoop安裝包:tar -zxvf hadoop.....tar.gz
重命名安裝目錄:mv hadoop..... hadoop
添加環境變量:配置文件位于/etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$........(JDK環境變量)
修改Hadoop配置文件
配置文件位于:$HADOOP_HOME/config目錄下
hadoop-env.sh(第九行去掉注釋,改為):export JAVA_HOME=/usr/local/jdk/
core-site.xml(配置內容見文末)
hdfs-site.xml(配置內容見文末)
mapred-site.xml(配置內容見文末)
格式化namenode、啟動Hadoop
格式化:hadoop namenode -format
啟動hadoop:start-all.sh
驗證查看JAVA進程:jps(應顯示6個進程)
訪問:http://hadoop:50070
訪問:http://hadoop:50030
關閉windows下防火墻,避免網絡訪問的錯誤
登陸linux時以root身份登陸,避免權限問題
每一步設置完成后應及時驗證,避免問題
JDK,HADOOP環境變量的配置中與自己安裝路徑保持一致
配置文件內的主機名與自己的主機名保持一致
禁止多次格式化namenode。若已經重復格式化,清空$HADOOP_HOME/tmp文件夾
core-site.xml(注意與自己的主機名保持一致)
<configuration> <property> <name>fs.default.name</name> <value>hdfs://hadoop:9000</value> <description>change your own hostname</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
mapred-site.xml(注意與自己的主機名保持一致)
<configuration> <property> <name>mapred.job.tracker</name> <value>hadoop:9001</value> <description>change your own hostname</description> </property> </configuration>
關于“Hadoop架構以及偽分布式安裝的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





