溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Lucene與HBase的組合使用及HBasene的報告分析,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
Lucene簡介
Lucene中,以document的形式作為搜索的主體。document由fieldName和fieldValue所組成,每個fieldValue又可以由一個或多個term元素來組成。基于不同的分詞及索引規則,可用于搜索fieldValue的term少于組成fieldValue的term。Lucene的搜索基于反向索引,包含著可用于搜索document的field信息。通過Lucene,可以正向查找document,以便了解其包含哪些field信息;也可以通過反向索引,通過搜索字段的term,來查詢包含該term的document。
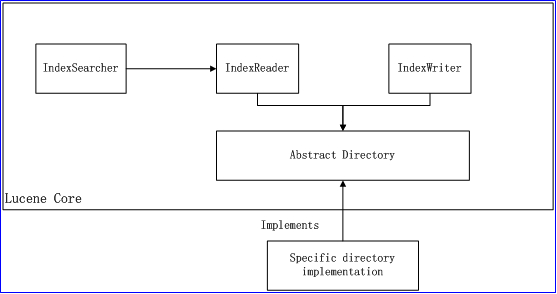
[ 圖1 ] Lucene總體架構
由圖1所示,IndexSearcher實現了搜索的邏輯,IndexWriter實現了文檔的插入與反向索引的建立,IndexReader由IndexSearcher調用以便讀取索引的內容。IndexReader和IndexWriter都依賴于抽象類Directory,Directory提供操作索引數據及的API。
標準的Lucene是基于文件系統和基于內存的。
標準基于文件系統的后端的缺點在于,隨著索引增加性能會下降,人們使用了各種不同的技術來解決這個問題,包括負載均衡和索引分片(index sharding,在多個Lucene實例之間切分索引)。盡管分片功能很強大,但它讓總體的實現架構變得更復雜,并且需要大量對期望文檔的預測知識,才能對Lucene索引進行合適地分片。另一方面,在大數據量的情況下,segment的合并花銷巨大;頻繁的update數據將使得Lucene對Disk io產生巨大的影響。一個新的數據的update,可能導致一部分根本沒有變化的索引被重寫很多次,并且可能導致很多的小的index segment,造成了search的性能下降。
Lucene的優勢在于索引查找的迅速,而非document的存儲。為解決上述問題,基于NoSQL數據庫存儲索引的后端結構應運而生。
以下,將基于HBase的實現來進行分析。
實現方法
在Lucene中,其會操作兩個單獨的數據集:
文檔數據集中存儲了所有文檔,包括存儲的字段等。
索引數據集中存儲了所有字段/詞匯/詞頻/位置等信息,以及包含當前字段的document
如果要實現將Lucene的后端移植到HBase上,直接構建一個Directory的實現并不會是最簡單的。在已有的開源項目中,Lucandra和HBasene均采用了直接重寫IndexReader和IndexWriter的方式,直接繞開了Directory的API。此實現并不會重寫Lucene的索引查詢機制。如若重載IndexSearcher,則可以在使用現有的Lucene索引查詢機制上,根據后端的功能增強性能。
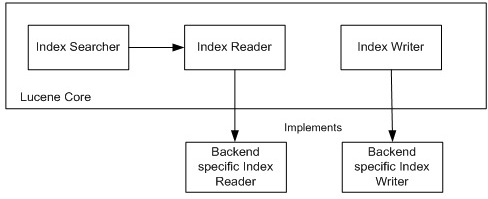
[ 圖2 ] Lucene的后端重新設計
圖2的設計,可以將Lucene后端與HBase整合起來,將索引數據存儲到HBase中,從而利用HBase的大數據存儲以及分布式性能。
架構設計
在架構設計上,將HBase用作索引的持久化后端,同時可以如網上所說,基于內存實現一套緩存機制,用來提高數據讀取速度。實現一套高效的緩存同步機制,也將有利于數據讀寫速率的提高。
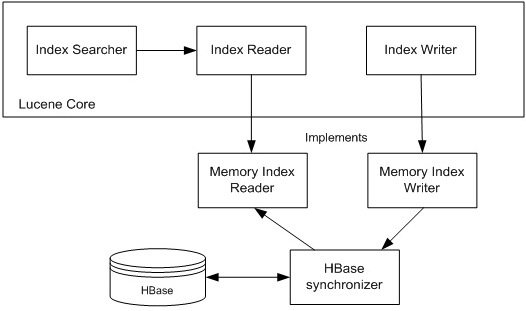
[ 圖3 ] 帶有內存緩存以及同步緩存的HBase后端實現
對于HBase的訪問,每一次交互都需要通過以太網,以太網的運行狀態將大大影響系統的使用情況,而索引的建立又希望能達到實時且高響應。為了平衡這兩種相互沖突的需求,在內存中,緩存能夠最小化HBase用于搜索和文件返回的數據讀取量,從而極大提升性能;按照需要運行為多個Lucene示例以支持日益增長的搜索客戶端的能力。后者需要最小化緩存的生命周期,從而和HBase實例(上面提到實例的副本)中的內容同步。通過為活動參數實現可配置的緩存時間,限制每個Lucene實例中展現的緩存,我們可以達成一種折中方案。
根據上述所描述的結構,對于讀操作,首先會檢查所需數據是否在內存中且沒有過期,如果有效將直接使用,否者將從HBase中獲取數據并更新到內存中。而對于寫操作,可以簡化到直接將數據寫入到HBase中,進而不需要考慮是否需要建立或更新緩存這種復雜的問題,這也將提高系統的實時響應性。
HBase Table的實現
當前了解到的兩種可參考的實現方式:HBasene類型、Lucandra類型。
1-- HBasene
其索引表由以下幾個column family組成:
fm.sequence:記錄sequenceId,表示當前添加的第幾個document。在執行createLuceneIndexTable時創建該行,且rowKey為segmentId,Column.qulifier為qual.sequence,Column.value=-1。每add一個document,當前segmentId的Column.value將自增1。
fm.doc2int:每個document的存儲都將被分配一個唯一的id,如果document的Field.Store=YES,則能夠通過該id獲取到對應的document的全部信息。
fm.fields:記錄了Field中value的內容,rowKey為documentId,Column.qulifier為FieldName,Column.value為FieldValue的內容。
fm.termVector:向量偏移數據,用于模糊查找,記錄了偏移量等信息,rowKey為FileldName/Term的組合,Column.qulifier為documentId,Column.value為指向的document中的所有位置偏移量。Column.value的結構為:[A][size][position]……[position]
fm.termFrequencies:關鍵詞在每個document中出現的頻率,rowKey結構為zfm/FileName/Term,Column.qulifier為documentId,Column.value為出現的次數。
2-- Lucandra
在Lucendra中,只有兩個ColummFamily來存儲數據,分別是TermInfo和Documents
<Keyspace Name="Lucandra"> <ColumnFamily Name="TermInfo" CompareWith="BytesType" ColumnType="Super" CompareSubcolumnsWith="BytesType" KeysCached="10%" /> <ColumnFamily Name="Documents" CompareWith="BytesType" KeysCached="10%" /> </Keyspace>
TermInfo
TermInfo存儲了Lucandra逆向索引的信息,用來存儲index的Field信息,其結構如下:
RowKey:field/term
SuperColumn.name:documentId
[ SubColumn.name:"frequencies" Column.value:count ]
[ SubColumn.name:"position" Column.value:position vector ]
[ SubColumn.name:"offsets" Column.value:offsets vector ]
[ SubColumn.name:"norms" Column.value:norms vector ]
由于HBase中不存在SuperColumn和SubColumn的概念,我們可以將其簡化為:
RowKey:field/term
Column.qulifier:documentId
Column.value:fieldInfo [ 此fieldInfo可以通過AVRO類定義 ]
Documents
Documents存儲了Document數據,其結構如下:
RowKey:documentId
Column.name:fieldName
Column.value:fieldValue
對比:
由HBasene的表結構可以知道,對于每一個document的更新以及每一次term的查詢,都需要操縱多行數據才能實現,邏輯上相對復雜;而Lucandra只需要處理兩行(documents及TermInfo各一行)。但是HBasene的優勢在于單行的存儲結構小,每次與HBase交互只需要傳輸少量的數據及可,并且不像Lucandra結構一樣需要而外的AVRO組件來序列化與反序列化數據。
HBasene的缺陷:
1、HBasene在三年前已經停止了其項目的更新,開源的支持斷開了。
2、在對HBasene的最新源碼分析過程中,首先是發現其設計上保留著segment的概念,但是其設計阻礙著document的查詢。其documentId由segmentId/sequenceId組成,每次segment的commit,sequenceId恢復為-1。而search時返回的TopDocs中只包含了sequenceId[int]。
3、每次添加document時,只有fm.Fields以及fm.doc2int的數據被實時flush到了HBase中,而其他數據需要segment大小到了一定程度[默認1000條document]才commit,容易造成數據缺失。在segment沒被commit的情況下,是無法查詢到新添加的document的。
4、HBase Table的設計中,沒有考慮到當document中fieldName相同的情況。當fieldName相同的情況下,后面添加的會覆蓋前面添加數據的,最后只保留最后添加的一份。
5、fm.termVector中,Column.value保存的并不是positionVector信息,而是segment中所有document里出現的次數。
6、fm.termFrequencies只是單純地存儲了,并沒有被應用上。
7、IndexWriter的重寫并沒有實現所有函數,只實現了最基本的addDocument
8、對IndexSearch的重寫和擴展也不夠。
關于Lucene與HBase的組合使用及HBasene的報告分析問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





