溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“jvm file.encoding屬性引起的HBase亂碼問題怎么解決”,在日常操作中,相信很多人在jvm file.encoding屬性引起的HBase亂碼問題怎么解決問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”jvm file.encoding屬性引起的HBase亂碼問題怎么解決”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
最近在往 HBase 寫中文的時候,發現 hbase 查出來的數據會有部分中文亂碼了,而部分中文又是正常的,按理來說,一般的亂碼問題要么全亂,要么不亂。考慮到出現中文的地方都是來源于 hdfs 上的一個配置文件,而這個配置文件可以確定是 utf-8 編碼的,那排除了原始文件導致的亂碼,想想 MR 代碼里也沒有轉碼的邏輯,也排除了代碼的問題,那就只有一種可能:Hadoop 集群的系統環境是異構的,這里面可能涉及到 linux 、java 的環境變量、配置的問題。
(1)打印了整個集群的 echo $LANG、echo $LC_ALL 等linux系統變量,發現都是一致的,排除了 os 環境的問題。
(2)剩下的重點放在了 java 環境上,在代碼里加上如下兩句,打印每條記錄的 ip 和 jvm 編碼,然后看看亂碼的記錄是那臺機器產生的,并且當時 jvm child 的編碼情況:
java.net.InetAddress test = java.net.InetAddress.getByName("localhost");
put.add(Bytes.toBytes("cf"), Bytes.toBytes("ip"), Bytes.toBytes(test.getLocalHost().getHostAddress()));
put.add(Bytes.toBytes("cf"), Bytes.toBytes("ec"), Bytes.toBytes(System.getProperty("file.encoding")));同時也直接 System.out.println 出相應的中文字段,看是寫進 hbase 之前還是之后亂掉的。
跑了一份測試數據后,發現 hbase 里的 ip、jvm 編碼是沒有規律的,然后查看 syso 打印的 log 發現,在寫 hbase 之前已經就已經亂碼了,然后想想 hbase 里的數據亂碼之所以沒有規律是因為 map 后要 shuffle、reduce 才能到 hbase。PS:sysout本身無編碼概念,類似 linux 下的 cat、head、more 等。
然后再次把 ip、jvm編碼 統計代碼放到 map 階段輸出,果真發現了規律,集群中有兩臺機器的 jvm 編碼不一致,不是 utf-8 的:
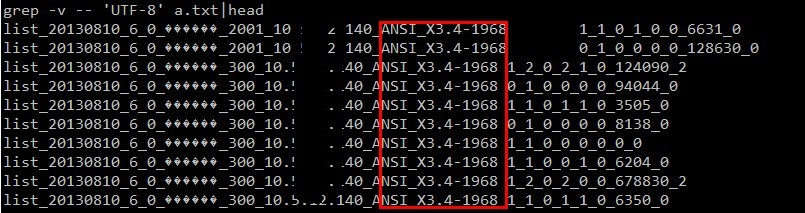
到這里我們可以知道原因了:由于集群中兩臺機器的 jvm 參數(file.encoding)不一致導致了部分中文結果的亂碼。
知道原因了,那就看如何解決了,目的就是要改變 file.encoding 的值 。
由于這個參數是 jvm 的啟動參數,運行時不可被更改(你可以理解為這個參數是個全局參數,而且被緩存了,如果一旦運行時更改了, 可能會造成整個 jvm 里面的程序奔潰),你只能修改系統的charset, 或者jvm的啟動參數里加上 -Dfile.encoding="UTF-8">,你運行時 setProperty("file.encoding","ISO-8859-1"); 這樣是沒用的,so,永久的解決辦法是:啥時候把這兩臺機器offline 改編碼后再online,然后再手動執行下 data balance。
或者可以在提交作業的時候設置作業參數: –Dmapred.child.env="LANG=en_US.UTF-8,LC_ALL=en_US.UTF-8"
不想這么大動干戈,想要臨時解決方案,也行,那就需要在咱們自己的業務代碼里繞開 jvm 提供的默認 file.encoding 編碼,自己指定編碼:
BufferedReader in = new BufferedReader(new FileReader(path.toString())); 換成: BufferedReader in = new BufferedReader((new InputStreamReader(new FileInputStream(path.toString()),"utf-8")));
上面一句是我之前亂碼的代碼,如果你沒有指定讀取編碼,那么 jvm 會使用自己的 file.encoding,這樣就會造成在某些機器上讀取文件就亂掉了。下面一句是自己指定編碼,這樣繞開了 jvm 的默認編碼,與 jvm 從此形同陌路~
PS:FileReader 貌似沒有提供指定編碼的構造方法,所以換成了下面的類。
為什么之前一直都沒亂碼,而這次讀文件卻亂碼了呢?
那是因為 hbase 的 Bytes、map 的 fileinputformat key/value、mapreduce 的 context.write 默認都是自己硬編碼了 utf-8,做到了 和 jvm 編碼無關,所以不會遇到上述問題。
上面說了這么多,可能有同學還是不大明白:jvm 的這參數有毛用啊?為毛之前都沒聽過這玩意呢?
恩,沒聽過正常,之前我也沒聽過哈~
在JDK 1.6.0_20的src.zip文件中,查找包含file.encoding字眼的文件.
共找到4個, 分別是:
(a)先上重頭戲 java.nio.Charset類:
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
java.security.PrivilegedAction pa = new GetPropertyAction("file.encoding");
String csn = (String) AccessController.doPrivileged(pa);
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}在java中,如果沒有指定charset的時候,比如new String(byte[] bytes), 都會調用Charset.defaultCharset()的方法,我們可以清楚的看到defaultCharset是只能被初始化一次,這里還是有點小問題的,在多線程并發調用的時候還是會初始話多次,當然后面都是從cache(lookup的函數)里讀出來的,問題也不大。
當我們在改變System.getProperties里的file.encoding 的時候,defaultCharset已經被初始化過了,所以不會在調用初始化的代碼。
當jvm 啟動的時候,load class, 最后調用main函數之前,defaultCharset已經初始化好,而很多函數里都掉用了這個方法象String.getBytes, 還有 InputStreamReader, InputStreamWriter 都是調用了 Charset.defaultCharset()的方法。
(b)java.net.URLEncoder的靜態構造方法, 影響到的方法 java.net.URLEncoder.encode(String)
恩,這里也需要注意,之前已經有同學掉坑里去了,請使用:encode(String s, String enc) 方法,此法無側漏,一覺睡到大天亮~
(c)com.sun.org.apache.xml.internal.serializer.Encoding的getMimeEncoding方法(209行起)
(d)最后一個javax.print.DocFlavor類的靜態構造方法
可以看到,系統變量file.encoding影響到
1. Charset.defaultCharset() Java環境中最關鍵的編碼設置
2. URLEncoder.encode(String) Web環境中最常遇到的編碼使用
3. com.sun.org.apache.xml.internal.serializer.Encoding 影響對無編碼設置的xml文件的讀取
4. javax.print.DocFlavor 影響打印的編碼
到此,關于“jvm file.encoding屬性引起的HBase亂碼問題怎么解決”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





