溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“RabbitMQ如何實現集群管理”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“RabbitMQ如何實現集群管理”這篇文章吧。
RabbitMQ這款消息隊列中間件產品本身是基于Erlang編寫,Erlang語言天生具備分布式特性(通過同步Erlang集群各節點的magic cookie來實現)。因此,RabbitMQ天然支持Clustering。這使得RabbitMQ本身不需要像ActiveMQ、Kafka那樣通過ZooKeeper分別來實現HA方案和保存集群的元數據。集群是保證可靠性的一種方式,同時可以通過水平擴展以達到增加消息吞吐量能力的目的。下面先來看下RabbitMQ集群的整體方案:
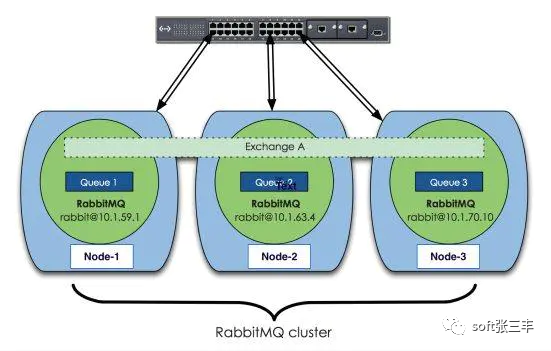
上面圖中采用三個節點組成了一個RabbitMQ的集群,Exchange A(交換器,對于RabbitMQ基礎概念不太明白的童鞋可以看下基礎概念)的元數據信息在所有節點上是一致的,而Queue(存放消息的隊列)的完整數據則只會存在于它所創建的那個節點上。,其他節點只知道這個queue的metadata信息和一個指向queue的owner node的指針。
RabbitMQ集群會始終同步四種類型的內部元數據(類似索引):a.隊列元數據:隊列名稱和它的屬性;b.交換器元數據:交換器名稱、類型和屬性;c.綁定元數據:一張簡單的表格展示了如何將消息路由到隊列;d.vhost元數據:為vhost內的隊列、交換器和綁定提供命名空間和安全屬性;因此,當用戶訪問其中任何一個RabbitMQ節點時,通過rabbitmqctl查詢到的queue/user/exchange/vhost等信息都是相同的。
我想肯定有不少同學會問,想要實現HA方案,那將RabbitMQ集群中的所有Queue的完整數據在所有節點上都保存一份不就可以了么?(可以類似MySQL的主主模式嘛)這樣子,任何一個節點出現故障或者宕機不可用時,那么使用者的客戶端只要能連接至其他節點能夠照常完成消息的發布和訂閱嘛。我想RabbitMQ的作者這么設計主要還是基于集群本身的性能和存儲空間上來考慮。第一,存儲空間,如果每個集群節點都擁有所有Queue的完全數據拷貝,那么每個節點的存儲空間會非常大,集群的消息積壓能力會非常弱(無法通過集群節點的擴容提高消息積壓能力);第二,性能,消息的發布者需要將消息復制到每一個集群節點,對于持久化消息,網絡和磁盤同步復制的開銷都會明顯增加。
RabbitMQ集群的工作原理圖如下:
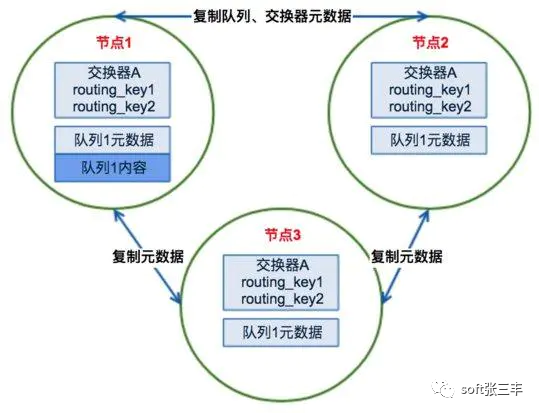
如果有一個消息生產者或者消息消費者通過amqp-client的客戶端連接至節點1進行消息的發布或者訂閱,那么此時的集群中的消息收發只與節點1相關,這個沒有任何問題;如果客戶端相連的是節點2或者節點3(隊列1數據不在該節點上),那么情況又會是怎么樣呢?
如果消息生產者所連接的是節點2或者節點3,此時隊列1的完整數據不在該兩個節點上,那么在發送消息過程中這兩個節點主要起了一個路由轉發作用,根據這兩個節點上的元數據(也就是上文提到的:指向queue的owner node的指針)轉發至節點1上,最終發送的消息還是會存儲至節點1的隊列1上。同樣,如果消息消費者所連接的節點2或者節點3,那這兩個節點也會作為路由節點起到轉發作用,將會從節點1的隊列1中拉取消息進行消費。
當你在單 node 上聲明 queue 時,只要該 node 上相關元數據進行了變更,你就會得到 Queue.Declare-ok 回應;而在 cluster 上聲明 queue ,則要求 cluster 上的全部 node 都要進行元數據成功更新,才會得到 Queue.Declare-ok 回應。另外,若 node 類型為 RAM node 則變更的數據僅保存在內存中,若類型為 disk node 則還要變更保存在磁盤上的數據。
是的。客戶端感覺不到有何不同。
不能,在這種情況下,將得到 404 NOT_FOUND 錯誤。只能等 queue 所屬的 node 恢復后才能使用該 queue 。但若該 queue 本身不具有 durable 屬性,則可在其他 node 上重新聲明。
若是 consumer 所連接的那個 node 失效(無論該 node 是否為 consumer 所訂閱 queue 的 owner node),則 consumer 會在發現 TCP 連接斷開時,按標準行為執行重連邏輯,并根據“Assume Nothing”原則重建相應的 fabric 即可。若是失效的 node 為 consumer 訂閱 queue 的owner node,則 consumer 只能通過 Consumer Cancellation Notification 機制來檢測與該 queue 訂閱關系的終止,否則會出現傻等卻沒有任何消息來到的問題。
不能。第一,你無法控制所創建的 queue 實際分布在 cluster 里的哪個 node 上(一般使用 HAProxy + cluster 模型時都是這樣),這可能會導致各種跨地域訪問時的常見問題;第二,Erlang 的 OTP 通信框架對延遲的容忍度有限,這可能會觸發各種超時,導致業務疲于處理;第三,在廣域網上的連接失效問題將導致經典的“腦裂”問題,而 RabbitMQ 目前無法處理(該問題主要是說 Mnesia)。
以上是“RabbitMQ如何實現集群管理”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





