溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“MergeTree中clickhouse稀疏索引怎么用”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“MergeTree中clickhouse稀疏索引怎么用”這篇文章吧。
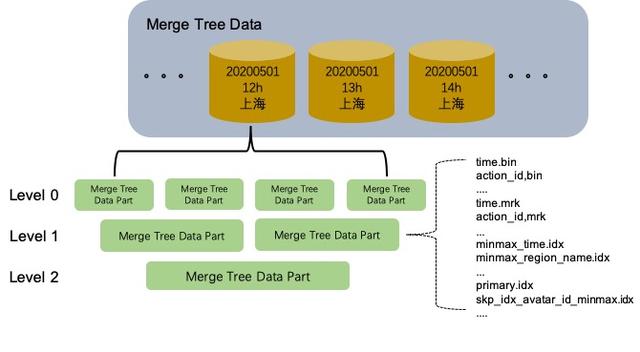
MergeTree表的存儲結構中,每個數據分區相互獨立,邏輯上沒有關聯。單個數據分區內部存在著多個MergeTree Data Part。這些Data Part一旦生成就是Immutable的狀態,Data Part的生成和銷毀主要與寫入和異步Merge有關。MergeTree表的寫入鏈路是一個極端的batch load過程,Data Part不支持單條的append insert。每次batch insert都會生成一個新的MergeTree Data Part。如果用戶單次insert一條記錄,那就會為那一條記錄生成一個獨立的Data Part,這必然是無法接受的。一般我們使用MergeTree表引擎的時候,需要在客戶端做聚合進行batch寫入。
part:一次寫入生成的一個數據塊。
primary.idx文件:存儲了稀疏索引,一個part對應一個稀疏索引。
| mark number | value |
|---|---|
| 0 | a |
| 1 | a |
| 2 | b |
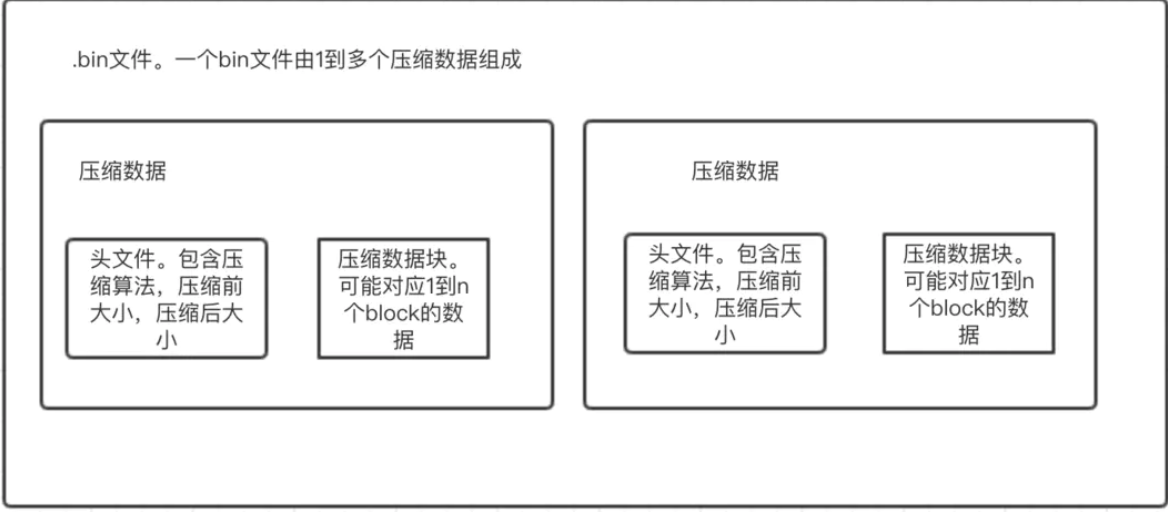
bin文件:真正存儲數據的文件,由1到多個壓縮數據組成。壓縮數據是最小存儲單位,由『頭文件』和『壓縮數據塊』組成。頭文件由壓縮算法、壓縮前的字節大小、壓縮后的字節大小三部分組成;壓縮數據塊嚴格限定在壓縮前64K~1M byte大小。(這個大小是ClickHouse認為的壓縮與解壓性能消耗最小的大小)。即,一個壓縮數據塊由N個block組成,一個bin文件又由N個壓縮數據塊組成。
mrk文件:存儲了block在bin文件中哪個壓縮數據以及這個壓縮數據的數據塊中的起始偏移量。
| 索引中的mark index | 壓縮數據index | 在壓縮數據塊中起始的字節數(偏移量) |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 12001 |
| 2 | 1 | 0 |
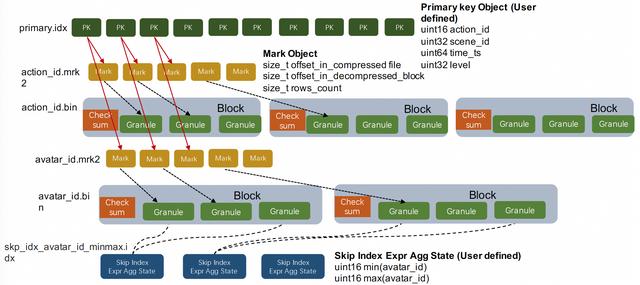
action_id.bin、avatar_id.bin等都是單個列按塊壓縮后的列存文件
數據以壓縮數據為單位,存儲在bin文件中。
壓縮數據對應的壓縮數據塊,嚴格限定按照64K~1M byte的大小來進行存儲。
(1)如果一個block對應的大小小于64K,則需要找下一個block來拼湊,直到拼湊出來的大小大于等于64K。
(2)如果一個block的大小在64K到1M的范圍內,則直接生成1個壓縮數據塊。
(3)如果一個block的大小大于了1M,則切割生成多個壓縮數據塊。
一個part下不同的列分別存儲,不同的列存儲的行數是一樣的。
Mark標識文件:action_id.mrk2、avatar_id.mrk2等都是列存文件中的Mark標記,Mark標記和MergeTree列存中的兩個重要概念相關:Granule和Block。
Granule是數據按行劃分時用到的邏輯概念。關于多少行是一個Granule這個問題,在老版本中這是用參數index_granularity設定的一個常量,也就是每隔確定行就是一個Granule。在當前版本中有另一個參數index_granularity_bytes會影響Granule的行數,它的意義是讓每個Granule中所有列的sum size盡量不要超過設定值。老版本中的定長Granule設定主要的問題是MergeTree中的數據是按Granule粒度進行索引的,這種粗糙的索引粒度在分析超級大寬表的場景中,從存儲讀取的data size會膨脹得非常厲害,需要用戶非常謹慎得設定參數。
Block是列存文件中的壓縮單元。每個列存文件的Block都會包含若干個Granule,具體多少個Granule是由參數min_compress_block_size控制,每次列的Block中寫完一個Granule的數據時,它會檢查當前Block Size有沒有達到設定值,如果達到則會把當前Block進行壓縮然后寫磁盤。
從以上兩點可以看出MergeTree的Block既不是定data size也不是定行數的,Granule也不是一個定長的邏輯概念。所以我們需要額外信息快速找到某一個Granule。這就是Mark標識文件的作用,它記錄了每個Granule的行數,以及它所在的Block在列存壓縮文件中的偏移,同時還有Granule在解壓后的Block中的偏移位置。
主鍵索引:primary.idx是表的主鍵索引。ClickHouse對主鍵索引的定義和傳統數據庫的定義稍有不同,它的主鍵索引沒用主鍵去重的含義,但仍然有快速查找主鍵行的能力。ClickHouse的主鍵索引存儲的是每一個Granule中起始行的主鍵值,而MergeTree存儲中的數據是按照主鍵嚴格排序的。所以當查詢給定主鍵條件時,我們可以根據主鍵索引確定數據可能存在的 ,再結合上面介紹的Mark標識,我們可以進一步確定數據在列存文件中的位置區間。ClickHoue的主鍵索引是一種在索引構建成本和索引效率上相對平衡的粗糙索引。MergeTree的主鍵序列默認是和Order By序列保存一致的,但是用戶可以把主鍵序列定義成Order By序列的部分前綴。
分區鍵索引:minmax_time.idx、minmax_region_name.idx是表的分區鍵索引。MergeTree存儲會把統計每個Data Part中分區鍵的最大值和最小值,當用戶查詢中包含分區鍵條件時,就可以直接排除掉不相關的Data Part,這是一種OLAP場景下常用的分區裁剪技術。
Skipping索引:skp_idx_avatar_id_minmax.idx是用戶在avatar_id列上定義的MinMax索引。Merge Tree中 的Skipping Index是一類局部聚合的粗糙索引。用戶在定義skipping index的時候需要設定granularity參數,這里的granularity參數指定的是在多少個Granule的數據上做聚合生成索引信息。用戶還需要設定索引對應的聚合函數,常用的有minmax、set、bloom_filter、ngrambf_v1等,聚合函數會統計連續若干個Granule中的列值生成索引信息。Skipping索引的思想和主鍵索引是類似的,因為數據是按主鍵排序的,主鍵索引統計的其實就是每個Granule粒度的主鍵序列MinMax值,而Skipping索引提供的聚合函數種類更加豐富,是主鍵索引的一種補充能力。另外這兩種索引都是需要用戶在理解索引原理的基礎上貼合自己的業務場景來進行設計的。
MergeTree存儲在收到一個select查詢時會先抽取出查詢中的分區鍵和主鍵條件的KeyCondition,KeyCondition類上實現了以下三個方法,用于判斷過濾條件可能滿足的Mark Range。上面講過MergeTree Data Part中的列存數據是以Granule為粒度被Mark標識數組索引起來的,而Mark Range就表示Mark標識數組里滿足查詢條件的下標區間。
索引檢索的過程中首先會用分區鍵KeyCondition裁剪掉不相關的數據分區,然后用主鍵索引挑選出粗糙的Mark Range,最后再用Skipping Index過濾主鍵索引產生的Mark Range。用主鍵索引挑選出粗糙的Mark Range的算法是一個不斷分裂Mark Range的過程,返回結果是一個Mark Range的集合。起始的Mark Range是覆蓋整個MergeTree Data Part區間的,每次分裂都會把上次分裂后的Mark Range取出來按一定粒度步長分裂成更細粒度的Mark Range,然后排除掉分裂結果中一定不滿足條件的Mark Range,最后Mark Range到一定粒度時停止分裂。這是一個簡單高效的粗糙過濾算法。
使用Skipping Index過濾主鍵索引返回的Mark Range之前,需要構造出每個Skipping Index的IndexCondition,不同的Skipping Index聚合函數有不同的IndexCondition實現,但判斷Mark Range是否滿足條件的接口和KeyCondition是類似的。
經過上一小節的索引過濾之后,我們已經得到了需要掃描的Mark Range集合,接下來就應該是數據掃描部分了。這一小節插入簡單講一下MergeTree里的數據Sampling是如何實現的。它并不是在數據掃描過程中實現的,而是在索引檢索的過程中就已經完成,這種做法是為了極致的sample效率。用戶在建表的時候可以指定主鍵中的某個列或者表達式作為Sampling鍵,ClickHouse在這里用了簡單粗暴的做法:Sampling鍵的值必須是數值類型的,并且系統假定它的值是隨機均勻分布的一個狀態。如果Sampling鍵的值類型是Uint32,當我們設定sample比率是0.1的時候,索引檢索過程中會把sample轉換成一個filter條件:Sampling鍵的值 < Uint32::max * 0.1。用戶在使用Sampling功能時必須清楚這個細節,不然容易出現采樣偏差。一般我們推薦Sampling鍵是列值加一個Hash函數進行隨機打散。
MergeTree的數據掃描部分提供了三種不同的模式:
Final模式:該模式對CollapsingMergeTree、SummingMergeTree等表引擎提供一個最終Merge后的數據視圖。前文已經提到過MergeTree基礎上的高級MergeTree表引擎都是對MergeTree Data Part采用了特定的Merge邏輯。它帶來的問題是由于MergeTree Data Part是異步Merge的過程,在沒有最終Merge成一個Data Part的情況下,用戶無法看到最終的數據結果。所以ClickHouse在查詢是提供了一個final模式,它會在各個Data Part的多條BlockInputStream基礎上套上一些高級的Merge Stream,例如DistinctSortedBlockInputStream、SummingSortedBlockInputStream等,這部分邏輯和異步Merge時的邏輯保持一致,這樣用戶就可以提前看到“最終”的數據結果了。
Sorted模式:sort模式可以認為是一種order by下推存儲的查詢加速優化手段。因為每個MergeTree Data Part內部的數據是有序的,所以當用戶查詢中包括排序鍵order by條件時只需要在各個Data Part的BlockInputStream上套一個做數據有序歸并的InputStream就可以實現全局有序的能力。
Normal模式:這是基礎MergeTree表最常用的數據掃描模式,多個Data Part之間進行并行數據掃描,對于單查詢可以達到非常高吞吐的數據讀取。
接下來展開介紹下Normal模式中幾個關鍵的性能優化點:
并行掃描:傳統的計算引擎在數據掃描部分的并發度大多和存儲文件數綁定在一起,所以MergeTree Data Part并行掃描是一個基礎能力。但是MergeTree的存儲結構要求數據不斷mege,最終合并成一個Data Part,這樣對索引和數據壓縮才是最高效的。所以ClickHouse在MergeTree Data Part并行的基礎上還增加了Mark Range并行。用戶可以任意設定數據掃描過程中的并行度,每個掃描線程分配到的是Mark Range In Data Part粒度的任務,同時多個掃描線程之間還共享了Mark Range Task Pool,這樣可以避免在存儲掃描中的長尾問題。
數據Cache:MergeTree的查詢鏈路中涉及到的數據有不同級別的緩存設計。主鍵索引和分區鍵索引在load Data Part的過程中被加載到內存,Mark文件和列存文件有對應的MarkCache和UncompressedCache,MarkCache直接緩存了Mark文件中的binary內容,而UncompressedCache中緩存的是解壓后的Block數據。
SIMD反序列化:部分列類型的反序列化過程中采用了手寫的sse指令加速,在數據命中UncompressedCache的情況下會有一些效果。
PreWhere過濾:ClickHouse的語法支持了額外的PreWhere過濾條件,它會先于Where條件進行判斷。當用戶在sql的filter條件中加上PreWhere過濾條件時,存儲掃描會分兩階段進行,先讀取PreWhere條件中依賴的列值,然后計算每一行是否符合條件。相當于在Mark Range的基礎上進一步縮小掃描范圍,PreWhere列掃描計算過后,ClickHouse會調整每個Mark對應的Granule中具體要掃描的行數,相當于可以丟棄Granule頭尾的一部分行。
以上是“MergeTree中clickhouse稀疏索引怎么用”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





