溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Pandas數據結構的基礎用法”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Pandas數據結構的基礎用法”吧!
head()與tail()用于快速預覽Series與DataFrame,默認顯示5條數據,也可以指定顯示數據的數量。

屬性與底層數據
Pandas可以通過多個屬性訪問元數據:
shape:輸出對象的軸維度,與ndarray一致
軸標簽:
Series:Index(僅有此軸)
DataFrame:Index(行)與列

Pandas對象(Index、Series、DataFrame)相當于數組的容器,用于存儲數據、執行計算。大部分類型的底層數組都是numpy.ndarray。不過,Pandas與第三方支持庫一般都會擴展NumPy類型系統,添加自定義數組。
.array屬性用于提取Index或Series里的數據。
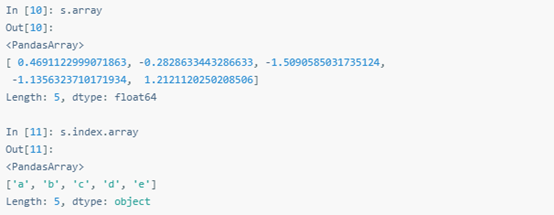
array一般指ExtensionArray。
提取NumPy數組,用to_numpy()或numpy.asarray()。

Series與Index的類型是ExtensionArray時,to_numpy()會復制數據,并強制轉換值。
to_numpy()可以控制numpy.ndarray生成的數據類型。以帶時區的datetme為例,NumPy未提供時區信息的datetime數據類型,Pandas則提供了兩種表現形式:
1.一種是帶Timestamp的numpy.ndarray,提供了正確的tz信息。
2.另一種是datetime64[ns],這也是一種numpy.ndarray,值被轉化為UTC,但去掉了時區信息。
時區信息可以用dtype=object保存
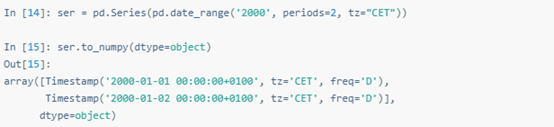
或用dtype=’datetime64[ns]’去除。

提取DataFrame里的原數據稍微有點復雜。DataFrame里所有列的數據類型都一樣時,DataFrame.to_numpy()返回底層數據:
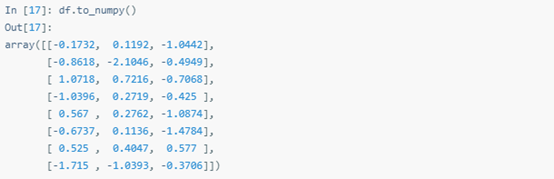
DataFrame為同構型數據時,Pandas直接修改原始ndarray,所以修改會直接反應在數據結構里。對于異構型數據,即DataFrame列的數據類型不一樣時,就不是這種操作模式了,與軸標簽不同,不能為值的屬性賦值。
這里我們要注意處理異構型數據時,輸出結果ndarray的數據類型適用于涉及的各類數據。若DataFrame里包含字符串,輸出結構的數據類型就是object。要是只有浮點數或整數,則輸出結果的數據類型是浮點數。
以前,Pandas推薦用Series.values或DataFrame.values從Series或DataFrame里提取數據。
但Pandas改進了此功能,現在,推薦用.array或to_numpy提取數據,別再用.values了。
.values有以下2個缺點:
1.Series含擴展類型時,Series.values無法判斷到底是改返回NumPy array,還是返回Extension array。而Series.array則只返回ExtensionArray,且不會復制數據。Series.to_numpy則返回NumPy數組,其代價是需要復制、并強制轉換數據的值。
2.DataFrame含多種數據類型時,DataFrame.values會復制數據,并將數據的值強制轉換同一種數據類型,這是一種代價較高的操作。DataFrame.to_numpy()則返回NumPy數組,這種方式更清晰,也不會把DataFrame里的數據都當作一種類型。
借助numexpr與bottleneck支持庫,Pandas可以加速特定類型的二進制數值與布爾操作。
處理大型數據集時,這兩個支持庫特別有用,加速效果也非常明顯。numexpr使用智能分塊、緩存與多核技術。bottleneck是一組專屬cython例程,處理含nans值的數組時,特別快。
請看下面這個例子(DataFrame包含100列×10萬行數據):

這兩個支持庫默認為啟用狀態,可用以下選項設置:

感謝各位的閱讀,以上就是“Pandas數據結構的基礎用法”的內容了,經過本文的學習后,相信大家對Pandas數據結構的基礎用法這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





