溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行批量SQL優化,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
有時在工作中,我們需要將大量的數據持久化到數據庫中,如果數據量很大的話直接插入的執行速度非常慢,并且由于插入操作也沒有太多能夠進行sql優化的地方,所以只能從程序代碼的角度進行優化。所以本文將嘗試使用幾種不同方式對插入操作進行優化,看看如何能夠最大程度的縮短SQL執行時間。
以插入1000條數據為例,首先進行數據準備,用于插入數據庫測試:
private List<Order> prepareData(){
List<Order> orderList=new ArrayList<>();
for (int i = 1; i <= 1000; i++) {
Order order=new Order();
order.setId(Long.valueOf(i));
order.setOrderNumber("A");
order.setMoney(100D);
order.setTenantId(1L);
orderList.add(order);
}
return orderList;
}首先測試直接插入1000條數據:
public void noBatch() {
List<Order> orderList = prepareData();
long startTime = System.currentTimeMillis();
for (Order order : orderList) {
orderMapper.insert(order);
}
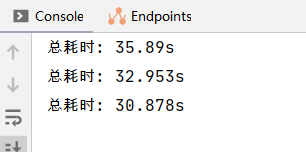
System.out.println("總耗時: " + (System.currentTimeMillis() - startTime) / 1000.0 + "s");
}執行時間如下:
接下來,使用mybatis-plus的批量查詢,我們自己的Service接口需要繼承IService接口:
public interface SqlService extends IService<Order> {
}在實現類SqlServiceImpl中直接調用saveBatch方法:
public void plusBatch() {
List<Order> orderList = prepareData();
long startTime = System.currentTimeMillis();
saveBatch(orderList);
System.out.println("總耗時: " + (System.currentTimeMillis() - startTime) / 1000.0 + "s");
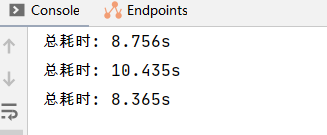
}執行代碼,查看運行時間:

可以發現,使用mybatis-plus的批量插入并沒有比循環單條插入顯著縮短時間,所以來查看一下saveBatch方法的源碼:
@Transactional(rollbackFor = Exception.class)
@Override
public boolean saveBatch(Collection<T> entityList, int batchSize) {
String sqlStatement = sqlStatement(SqlMethod.INSERT_ONE);
return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
}其中調用了executeBatch方法:
protected <E> boolean executeBatch(Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
Assert.isFalse(batchSize < 1, "batchSize must not be less than one");
return !CollectionUtils.isEmpty(list) && executeBatch(sqlSession -> {
int size = list.size();
int i = 1;
for (E element : list) {
consumer.accept(sqlSession, element);
if ((i % batchSize == 0) || i == size) {
sqlSession.flushStatements();
}
i++;
}
});
}在for循環中,consumer的accept執行的是sqlSession的insert操作,這一階段都是對sql的拼接,只有到最后當for循環執行完成后,才會將數據批量刷新到數據庫中。也就是說,之前我們向數據庫服務器發起了1000次請求,但是使用批量插入,只需要發起一次請求就可以了。如果拋出異常,則會進行回滾,不會向數據庫中寫入數據。但是雖然減少了數據庫請求的次數,對于縮短執行時間并沒有顯著的提升。
Stream是JAVA8中用于處理集合的關鍵抽象概念,可以進行復雜的查找、過濾、數據映射等操作。而并行流Parallel Stream,可以將整個數據內容分成多個數據塊,并使用多個線程分別處理每個數據塊的流。在大量數據的插入操作中,不存在數據的依賴的耦合關系,因此可以進行拆分使用并行流進行插入。測試插入的代碼如下:
public void stream(){
List<Order> orderList = prepareData();
long startTime = System.currentTimeMillis();
orderList.parallelStream().forEach(order->orderMapper.insert(order));
System.out.println("總耗時: " + (System.currentTimeMillis() - startTime) / 1000.0 + "s");
}還是先對上面的代碼進行測試:
可以發現速度比之前快了很多,這是因為并行流底層使用了Fork/Join框架,具體來說使用了“分而治之”的思想,對任務進行了拆分,使用不同線程進行執行,最后匯總(對Fork/Join不熟悉的同學可以回顧一下請求合并與分而治之這篇文章,里面介紹了它的基礎使用)。并行流在底層使用了ForkJoinPool線程池,從ForkJoinPool的默認構造函數中看出,它擁有的默認線程數量等于計算機的邏輯處理器數量:
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}也就是說,如果我們服務器是邏輯8核的話,那么就會有8個線程來同時執行插入操作,大大縮短了執行的時間。并且ForkJoinPool線程池為了提高任務的并行度和吞吐量,采用了任務竊取機制,能夠進一步的縮短執行的時間。
在并行流中,創建的ForkJoinPool的線程數量是固定的,那么通過手動修改線程池中線程的數量,能否進一步的提高執行效率呢?一般而言,在線程池中,設置線程數量等于處理器數量就可以了,因為如果創建過多線程,線程頻繁切換上下文也會額外消耗時間,反而會增加執行的總體時間。但是對于批量SQL的插入操作,沒有復雜的業務處理邏輯,僅僅是需要頻繁的與數據庫進行交互,屬于I/O密集型操作。而對于I/O密集型操作,程序中存在大量I/O等待占據時間,導致CPU使用率較低。所以我們嘗試增加線程數量,來看一下能否進一步縮短執行時間呢?
定義插入任務,因為不需要返回,直接繼承RecursiveAction父類。size是每個隊列中包含的任務數量,在構造方法中傳入,如果一個隊列中的任務數量大于它那么就繼續進行拆分,直到任務數量足夠小:
public class BatchInsertTask<E> extends RecursiveAction {
private List<E> list;
private BaseMapper<E> mapper;
private int size;
public BatchInsertTask(List<E> list, BaseMapper<E> mapper, int size) {
this.list = list;
this.mapper = mapper;
this.size = size;
}
@Override
protected void compute() {
if (list.size() <= size) {
list.stream().forEach(item -> mapper.insert(item));
} else {
int middle = list.size() / 2;
List<E> left = list.subList(0, middle);
List<E> right = list.subList(middle, list.size());
BatchInsertTask<E> leftTask = new BatchInsertTask<>(left, mapper, size);
BatchInsertTask<E> rightTask = new BatchInsertTask<>(right, mapper, size);
invokeAll(leftTask, rightTask);
}
}
}使用ForkJoinPool運行上面定義的任務,線程池中的線程數取CPU線程的2倍,將執行的SQL條數均分到每個線程的執行隊列中:
public class BatchSqlUtil {
public static <E> void runSave(List<E> list, BaseMapper<E> mapper) {
int processors = getProcessors();
ForkJoinPool forkJoinPool = new ForkJoinPool(processors);
int size = (int) Math.ceil((double)list.size() / processors);
BatchInsertTask<E> task = new BatchInsertTask<E>(list, mapper, size);
forkJoinPool.invoke(task);
}
private static int getProcessors() {
int processors = Runtime.getRuntime().availableProcessors();
return processors<<=1;
}
}啟動測試代碼:
public void batch() {
List<Order> orderList = prepareData();
long startTime = System.currentTimeMillis();
BatchSqlUtil.runSave(orderList,orderMapper);
System.out.println("總耗時: " + (System.currentTimeMillis() - startTime) / 1000.0 + "s");
}查看運行時間:
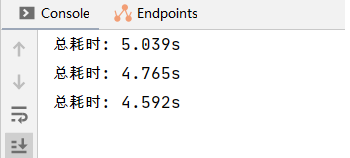
可以看到,通過增加ForkJoinPool中的線程,可以進一步的縮短批量插入的時間。
關于如何進行批量SQL優化問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





