溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“ClickHouse分析數據庫的原理及應用”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“ClickHouse分析數據庫的原理及應用”吧!
2020年下半年在OLAP領域有一匹黑馬以席卷之勢進入大數據開發者的領域,它就是ClickHouse。在2019年小編也曾介紹過ClickHouse,大家可以參考這里進行入門:
來自俄羅斯的兇猛彪悍的分析數據庫-ClickHouse
基于ClickHouse的用戶行為分析實踐
Prometheus+Clickhouse實現業務告警
那么我們有必要先從全局了解一下ClickHouse到底是個什么樣的數據庫?
ClickHouse是一個開源的,面向列的分析數據庫,由Yandex為OLAP和大數據用例創建。ClickHouse對實時查詢處理的支持使其適用于需要亞秒級分析結果的應用程序。ClickHouse的查詢語言是SQL的一種方言,它支持強大的聲明性查詢功能,同時為最終用戶提供熟悉度和較小的學習曲線。
ClickHouse全稱是Click Stream,Data Warehouse,簡稱ClickHouse就是基于頁面的點擊事件流,面向數據倉庫進行OLAP分析。ClickHouse是一款開源的數據分析數據庫,由戰斗民族俄羅斯Yandex公司研發的,Yandex是做搜索引擎的,就類似與Google,百度等。
我們都知道搜索引擎的營收主要來源與流量和廣告業務,所以搜索引擎公司會著重分析用戶網路流量,像Google有Anlytics,百度有百度統計,那么Yandex就對應于Yandex.Metrica。ClickHouse就式在Yandex.Metrica下產生的技術。
面向列的數據庫將記錄存儲在按列而不是行分組的塊中。通過不加載查詢中不存在的列的數據,面向列的數據庫在完成查詢時花費的時間更少。因此,對于某些工作負載(如OLAP),這些數據庫可以比傳統的基于行的系統更快地計算和返回結果。
優異的性能
根據官網的介紹(https://clickhouse.tech/benchmark/dbms/),ClickHouse在相同的服務器配置與數據量下,平均響應速度:
Vertica的2.63倍(Vertica是一款收費的列式存儲數據庫)
InfiniDB的17倍(可伸縮的分析數據庫引擎,基于Mysql搭建)
MonetDB的27倍(開源的列式數據庫)
Hive的126倍
MySQL的429倍
Greenplum的10倍
Spark的1倍
性能是衡量 OLAP 數據庫的關鍵指標,我們可以通過 ClickHouse 官方測試結果感受下 ClickHouse 的極致性能,其中綠色代表性能最佳,紅色代表性能較差,紅色越深代表性能越弱。

我們在之前用了一篇文章《數據告訴你ClickHouse有多快》 詳細講解了 ClickHouse的優異性能表現。
優勢和局限性
ClickHouse主要特點:
ROLAP(關系型的聯機分析處理,和它一起比較的還有OLTP聯機事務處理,我們常見的ERP,CRM系統就屬于OLTP)
在線實時查詢
完整的DBMS(關系數據庫)
列式存儲(區別與HBase,ClickHouse的是完全列式存儲,HBase具體說是列族式存儲)
不需要任何數據預處理
支持批量更新
擁有完善的SQl支持和函數
支持高可用(多主結構,在后面的結構設計中會講到)
不依賴Hadoop復雜生態(像ES一樣,開箱即用)
一些不足:
不支持事務(這其實也是大部分OLAP數據庫的缺點)
不擅長根據主鍵按行粒度查詢(但是支持這種操作)
不擅長按行刪除數據(但是支持這種操作)
ClickHouse 采用了典型的分組式的分布式架構,集群架構如下圖所示:
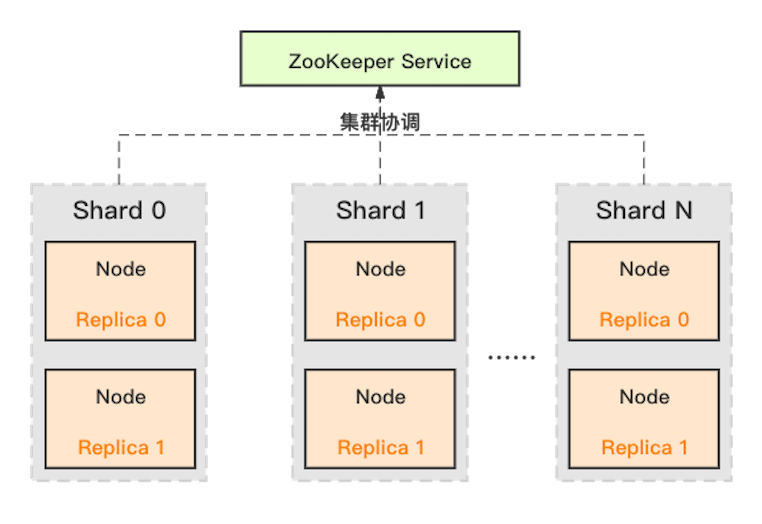
這其中的角色包括:
Shard :集群內劃分為多個分片或分組(Shard 0 … Shard N),通過 Shard 的線性擴展能力,支持海量數據的分布式存儲計算。
Node :每個 Shard 內包含一定數量的節點(Node,即進程),同一 Shard 內的節點互為副本,保障數據可靠。ClickHouse 中副本數可按需建設,且邏輯上不同 Shard 內的副本數可不同。
ZooKeeper Service :集群所有節點對等,節點間通過 ZooKeeper 服務進行分布式協調。
ClickHouse基礎架構如下圖所示:
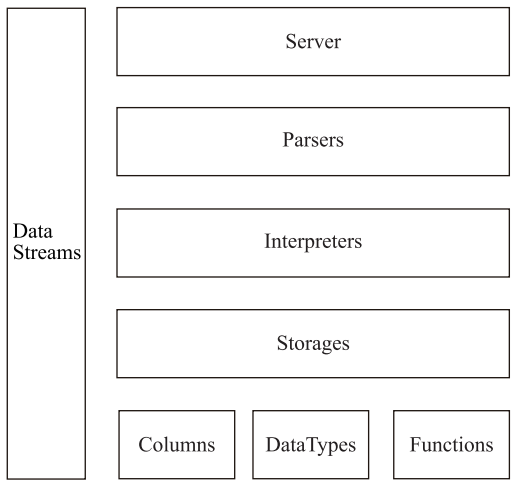
Column與Field
Column和Field是ClickHouse數據最基礎的映射單元。內存中的一列數據由一個Column對象表示。Column對象分為接口和實現兩個部分,在IColumn接口對象中,定義了對數據進行各種關系運算的方法。在大多數場合,ClickHouse都會以整列的方式操作數據,但凡事也有例外。如果需要操作單個具體的數值 ( 也就是單列中的一行數據 ),則需要使用Field對象,Field對象代表一個單值。與Column對象的泛化設計思路不同,Field對象使用了聚合的設計模式。在Field對象內部聚合了Null、UInt64、String和Array等13種數據類型及相應的處理邏輯。
DataType
數據的序列化和反序列化工作由DataType負責。IDataType接口定義了許多正反序列化的方法,它們成對出現。IDataType也使用了泛化的設計模式,具體方法的實現邏輯由對應數據類型的實例承載。DataType雖然負責序列化相關工作,但它并不直接負責數據的讀取,而是轉由從Column或Field對象獲取。
Block與Block流
ClickHouse內部的數據操作是面向Block對象進行的,并且采用了流的形式。Block對象可以看作數據表的子集。Block對象的本質是由數據對象、數據類型和列名稱組成的三元組,即Column、DataType及列名稱字符串。僅通過Block對象就能完成一系列的數據操作。Block并沒有直接聚合Column和DataType對象,而是通過ColumnWithTypeAndName對象進行間接引用。Block流操作有兩組頂層接口:IBlockInputStream負責數據的讀取和關系運算,IBlockOutputStream負責將數據輸出到下一環節。IBlockInputStream接口定義了讀取數據的若干個read虛方法,而具體的實現邏輯則交由它的實現類來填充。IBlockInputStream接口總共有60多個實現類,這些實現類大致可以分為三類:
第一類用于處理數據定義的DDL操作
第二類用于處理關系運算的相關操作
第三類則是與表引擎呼應,每一種表引擎都擁有與之對應的BlockInputStream實現
IBlockOutputStream的設計與IBlockInputStream如出一轍。這些實現類基本用于表引擎的相關處理,負責將數據寫入下一環節或者最終目的地。
Table
在數據表的底層設計中并沒有所謂的Table對象,它直接使用IStorage接口指代數據表。表引擎是ClickHouse的一個顯著特性,不同的表引擎由不同的子類實現。IStorage接口負責數據的定義、查詢與寫入。IStorage負責根據AST查詢語句的指示要求,返回指定列的原始數據。后續的加工、計算和過濾則由下面介紹的部分進行。
Parser與Interpreter
Parser分析器負責創建AST對象;而Interpreter解釋器則負責解釋AST,并進一步創建查詢的執行管道。它們與IStorage一起,串聯起了整個數據查詢的過程。Parser分析器可以將一條SQL語句以遞歸下降的方法解析成AST語法樹的形式。不同的SQL語句,會經由不同的Parser實現類解析。Interpreter解釋器的作用就像Service服務層一樣,起到串聯整個查詢過程的作用,它會根據解釋器的類型,聚合它所需要的資源。首先它會解析AST對象;然后執行"業務邏輯">
Functions 與Aggregate Functions
ClickHouse主要提供兩類函數—普通函數(Functions)和聚合函數(Aggregate Functions)。普通函數由IFunction接口定義,擁有數十種函數實現,采用向量化的方式直接作用于一整列數據。聚合函數由IAggregateFunction接口定義,相比無狀態的普通函數,聚合函數是有狀態的。以COUNT聚合函數為例,其AggregateFunctionCount的狀態使用整型UInt64記錄。聚合函數的狀態支持序列化與反序列化,所以能夠在分布式節點之間進行傳輸,以實現增量計算。
Cluster與Replication
ClickHouse的集群由分片 ( Shard ) 組成,而每個分片又通過副本 ( Replica ) 組成。這種分層的概念,在一些流行的分布式系統中十分普遍。這里有幾個與眾不同的特性。ClickHouse的1個節點只能擁有1個分片,也就是說如果要實現1分片、1副本,則至少需要部署2個服務節點。分片只是一個邏輯概念,其物理承載還是由副本承擔的。
ClickHouse的特性有很多,一款被認可的OLAP引擎能夠得到大家的頻繁使用一定是有獨特的特性,小編列舉了幾個ClickHouse異于常人的特性:
列式存儲&數據壓縮
按列存儲與按行存儲相比,前者可以有效減少查詢時所需掃描的數據量,這一點可以用一個示例簡單說明。假設一張數據表A擁有50個字段A1~A50,以及100行數據。現在需要查詢前5個字段并進行數據分析,那么通過列存儲,我們僅需讀取必要的列數據,相比于普通行存,可減少 10 倍左右的讀取、解壓、處理等開銷,對性能會有質的影響。
如果數據按行存儲,數據庫首先會逐行掃描,并獲取每行數據的所有50個字段,再從每一行數據中返回A1~A5這5個字段。不難發現,盡管只需要前面的5個字段,但由于數據是按行進行組織的,實際上還是掃描了所有的字段。如果數據按列存儲,就不會發生這樣的問題。由于數據按列組織,數據庫可以直接獲取A1~A5這5列的數據,從而避免了多余的數據掃描。
按列存儲相比按行存儲的另一個優勢是對數據壓縮的友好性。ClickHouse的數據按列進行組織,屬于同一列的數據會被保存在一起,列與列之間也會由不同的文件分別保存 ( 這里主要指MergeTree表引擎 )。數據默認使用LZ4算法壓縮,在Yandex.Metrica的生產環境中,數據總體的壓縮比可以達到8:1 ( 未壓縮前17PB,壓縮后2PB )。列式存儲除了降低IO和存儲的壓力之外,還為向量化執行做好了鋪墊。
向量化執行
坊間有句玩笑,即"能用錢解決的問題,千萬別花時間"。而業界也有種調侃如出一轍,即"能升級硬件解決的問題,千萬別優化程序"。有時候,你千辛萬苦優化程序邏輯帶來的性能提升,還不如直接升級硬件來得簡單直接。這雖然只是一句玩笑不能當真,但硬件層面的優化確實是最直接、最高效的提升途徑之一。向量化執行就是這種方式的典型代表,這項寄存器硬件層面的特性,為上層應用程序的性能帶來了指數級的提升。
向量化執行,可以簡單地看作一項消除程序中循環的優化。這里用一個形象的例子比喻。小胡經營了一家果汁店,雖然店里的鮮榨蘋果汁深受大家喜愛,但客戶總是抱怨制作果汁的速度太慢。小胡的店里只有一臺榨汁機,每次他都會從籃子里拿出一個蘋果,放到榨汁機內等待出汁。如果有8個客戶,每個客戶都點了一杯蘋果汁,那么小胡需要重復循環8次上述的榨汁流程,才能榨出8杯蘋果汁。如果制作一杯果汁需要5分鐘,那么全部制作完畢則需要40分鐘。為了提升果汁的制作速度,小胡想出了一個辦法。他將榨汁機的數量從1臺增加到了8臺,這么一來,他就可以從籃子里一次性拿出8個蘋果,分別放入8臺榨汁機同時榨汁。此時,小胡只需要5分鐘就能夠制作出8杯蘋果汁。為了制作n杯果汁,非向量化執行的方式是用1臺榨汁機重復循環制作n次,而向量化執行的方式是用n臺榨汁機只執行1次。
為了實現向量化執行,需要利用CPU的SIMD指令。SIMD的全稱是Single Instruction Multiple Data,即用單條指令操作多條數據。現代計算機系統概念中,它是通過數據并行以提高性能的一種實現方式 ( 其他的還有指令級并行和線程級并行 ),它的原理是在CPU寄存器層面實現數據的并行操作。
在計算機系統的體系結構中,存儲系統是一種層次結構。典型服務器計算機的存儲層次結構如圖1所示。一個實用的經驗告訴我們,存儲媒介距離CPU越近,則訪問數據的速度越快。
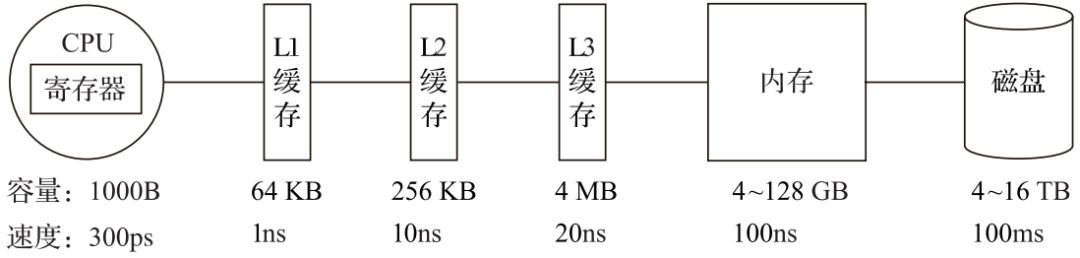
從上圖中可以看到,從左向右,距離CPU越遠,則數據的訪問速度越慢。從寄存器中訪問數據的速度,是從內存訪問數據速度的300倍,是從磁盤中訪問數據速度的3000萬倍。所以利用CPU向量化執行的特性,對于程序的性能提升意義非凡。
ClickHouse目前利用SSE4.2指令集實現向量化執行。
關系模型與SQL查詢
相比HBase和Redis這類NoSQL數據庫,ClickHouse使用關系模型描述數據并提供了傳統數據庫的概念 ( 數據庫、表、視圖和函數等 )。與此同時,ClickHouse完全使用SQL作為查詢語言 ( 支持GROUP BY、ORDER BY、JOIN、IN等大部分標準SQL ),這使得它平易近人,容易理解和學習。因為關系型數據庫和SQL語言,可以說是軟件領域發展至今應用最為廣泛的技術之一,擁有極高的"群眾基礎"。也正因為ClickHouse提供了標準協議的SQL查詢接口,使得現有的第三方分析可視化系統可以輕松與它集成對接。在SQL解析方面,ClickHouse是大小寫敏感的,這意味著SELECT a 和 SELECT A所代表的語義是不同的。
關系模型相比文檔和鍵值對等其他模型,擁有更好的描述能力,也能夠更加清晰地表述實體間的關系。更重要的是,在OLAP領域,已有的大量數據建模工作都是基于關系模型展開的 ( 星型模型、雪花模型乃至寬表模型 )。ClickHouse使用了關系模型,所以將構建在傳統關系型數據庫或數據倉庫之上的系統遷移到ClickHouse的成本會變得更低,可以直接沿用之前的經驗成果。
多樣化的表引擎
也許因為Yandex.Metrica的最初架構是基于MySQL實現的,所以在ClickHouse的設計中,能夠察覺到一些MySQL的影子,表引擎的設計就是其中之一。與MySQL類似,ClickHouse也將存儲部分進行了抽象,把存儲引擎作為一層獨立的接口。截至本書完稿時,ClickHouse共擁有合并樹、內存、文件、接口和其他6大類20多種表引擎。其中每一種表引擎都有著各自的特點,用戶可以根據實際業務場景的要求,選擇合適的表引擎使用。
通常而言,一個通用系統意味著更廣泛的適用性,能夠適應更多的場景。但通用的另一種解釋是平庸,因為它無法在所有場景內都做到極致。
在軟件的世界中,并不會存在一個能夠適用任何場景的通用系統,為了突出某項特性,勢必會在別處有所取舍。其實世間萬物都遵循著這樣的道理,就像信天翁和蜂鳥,雖然都屬于鳥類,但它們各自的特點卻鑄就了完全不同的體貌特征。信天翁擅長遠距離飛行,環繞地球一周只需要1至2個月的時間。因為它能夠長時間處于滑行狀態,5天才需要扇動一次翅膀,心率能夠保持在每分鐘100至200次之間。而蜂鳥能夠垂直懸停飛行,每秒可以揮動翅膀70~100次,飛行時的心率能夠達到每分鐘1000次。如果用數據庫的場景類比信天翁和蜂鳥的特點,那么信天翁代表的可能是使用普通硬件就能實現高性能的設計思路,數據按粗粒度處理,通過批處理的方式執行;而蜂鳥代表的可能是按細粒度處理數據的設計思路,需要高性能硬件的支持。
將表引擎獨立設計的好處是顯而易見的,通過特定的表引擎支撐特定的場景,十分靈活。對于簡單的場景,可直接使用簡單的引擎降低成本,而復雜的場景也有合適的選擇。
多線程與分布式
ClickHouse幾乎具備現代化高性能數據庫的所有典型特征,對于可以提升性能的手段可謂是一一用盡,對于多線程和分布式這類被廣泛使用的技術,自然更是不在話下。
如果說向量化執行是通過數據級并行的方式提升了性能,那么多線程處理就是通過線程級并行的方式實現了性能的提升。相比基于底層硬件實現的向量化執行SIMD,線程級并行通常由更高層次的軟件層面控制。現代計算機系統早已普及了多處理器架構,所以現今市面上的服務器都具備良好的多核心多線程處理能力。由于SIMD不適合用于帶有較多分支判斷的場景,ClickHouse也大量使用了多線程技術以實現提速,以此和向量化執行形成互補。
如果一個籃子裝不下所有的雞蛋,那么就多用幾個籃子來裝,這就是分布式設計中分而治之的基本思想。同理,如果一臺服務器性能吃緊,那么就利用多臺服務的資源協同處理。為了實現這一目標,首先需要在數據層面實現數據的分布式。因為在分布式領域,存在一條金科玉律—計算移動比數據移動更加劃算。在各服務器之間,通過網絡傳輸數據的成本是高昂的,所以相比移動數據,更為聰明的做法是預先將數據分布到各臺服務器,將數據的計算查詢直接下推到數據所在的服務器。ClickHouse在數據存取方面,既支持分區 ( 縱向擴展,利用多線程原理 ),也支持分片 ( 橫向擴展,利用分布式原理 ),可以說是將多線程和分布式的技術應用到了極致。
多主架構
HDFS、Spark、HBase和Elasticsearch這類分布式系統,都采用了Master-Slave主從架構,由一個管控節點作為Leader統籌全局。而ClickHouse則采用Multi-Master多主架構,集群中的每個節點角色對等,客戶端訪問任意一個節點都能得到相同的效果。這種多主的架構有許多優勢,例如對等的角色使系統架構變得更加簡單,不用再區分主控節點、數據節點和計算節點,集群中的所有節點功能相同。所以它天然規避了單點故障的問題,非常適合用于多數據中心、異地多活的場景。
在線查詢
ClickHouse經常會被拿來與其他的分析型數據庫作對比,比如Vertica、SparkSQL、Hive和Elasticsearch等,它與這些數據庫確實存在許多相似之處。例如,它們都可以支撐海量數據的查詢場景,都擁有分布式架構,都支持列存、數據分片、計算下推等特性。這其實也側面說明了ClickHouse在設計上確實吸取了各路奇技淫巧。與其他數據庫相比,ClickHouse也擁有明顯的優勢。例如,Vertica這類商用軟件價格高昂;SparkSQL與Hive這類系統無法保障90%的查詢在1秒內返回,在大數據量下的復雜查詢可能會需要分鐘級的響應時間;而Elasticsearch這類搜索引擎在處理億級數據聚合查詢時則顯得捉襟見肘。
正如ClickHouse的"廣告詞"所言,其他的開源系統太慢,商用的系統太貴,只有Clickouse在成本與性能之間做到了良好平衡,即又快又開源。ClickHouse當之無愧地闡釋了"在線"二字的含義,即便是在復雜查詢的場景下,它也能夠做到極快響應,且無須對數據進行任何預處理加工。
數據分片與分布式查詢
數據分片是將數據進行橫向切分,這是一種在面對海量數據的場景下,解決存儲和查詢瓶頸的有效手段,是一種分治思想的體現。ClickHouse支持分片,而分片則依賴集群。每個集群由1到多個分片組成,而每個分片則對應了ClickHouse的1個服務節點。分片的數量上限取決于節點數量 ( 1個分片只能對應1個服務節點 )。
ClickHouse并不像其他分布式系統那樣,擁有高度自動化的分片功能。ClickHouse提供了本地表 ( Local Table ) 與分布式表 ( Distributed Table ) 的概念。一張本地表等同于一份數據的分片。而分布式表本身不存儲任何數據,它是本地表的訪問代理,其作用類似分庫中間件。借助分布式表,能夠代理訪問多個數據分片,從而實現分布式查詢。
這種設計類似數據庫的分庫和分表,十分靈活。例如在業務系統上線的初期,數據體量并不高,此時數據表并不需要多個分片。所以使用單個節點的本地表 ( 單個數據分片 ) 即可滿足業務需求,待到業務增長、數據量增大的時候,再通過新增數據分片的方式分流數據,并通過分布式表實現分布式查詢。這就好比一輛手動擋賽車,它將所有的選擇權都交到了使用者的手中。
關于ClickHouse的安裝,我們在這里不再詳細展開,官網有詳細的文檔可以參考。
我們使用Java客戶端連接ClickHouse進行一些簡單的操作。首先Clickhouse 有兩種 JDBC 驅動實現:
一種是官方給出的
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2.4</version>
</dependency>
還有一種第三方提供的驅動:
<dependency>
<groupId>com.github.housepower</groupId>
<artifactId>clickhouse-native-jdbc</artifactId>
<version>2.5.2</version>
</dependency>
兩者間的主要區別如下:
驅動類加載路徑不同,分別為 ru.yandex.clickhouse.ClickHouseDriver 和 com.github.housepower.jdbc.ClickHouseDriver
默認連接端口不同,分別為 8123 和 9000
連接協議不同,官方驅動使用 HTTP 協議,而三方驅動使用 TCP 協議
需要注意的是,兩種驅動不可共用,同個項目中只能選擇其中一種驅動。
Class.forName("com.github.housepower.jdbc.ClickHouseDriver");
Connection connection = DriverManager.getConnection("jdbc:clickhouse://192.168.60.131:9000");
Statement statement = connection.createStatement();
statement.executeQuery("create table test.example(day Date, name String, age UInt8) Engine=Log");
PreparedStatement pstmt = connection.prepareStatement("insert into test.example values(?, ?, ?)");
// insert 10 records
for (int i = 0; i < 10; i++) {
pstmt.setDate(1, new Date(System.currentTimeMillis()));
pstmt.setString(2, "panda_"> pstmt.setInt(3, 18);
pstmt.addBatch();
}
pstmt.executeBatch();
Statement statement = connection.createStatement();
String sql = "select * from test.jdbc_example";
ResultSet rs = statement.executeQuery(sql);
while (rs.next()) {
// ResultSet 的下標值從 1 開始,不可使用 0,否則越界,報 ArrayIndexOutOfBoundsException 異常
System.out.println(rs.getDate(1) + ", " + rs.getString(2) + ", " + rs.getInt(3));
}
通過 clickhouse-client 命令行界面查看表情況:
ck-master :) show tables;
SHOW TABLES
┌─name─────────┐
│ hits │
│ jdbc_example │
└──────────────┘
ck-master :) select * from example;
SELECT *
FROM jdbc_example
┌────────day─┬─name─────┬─age─┐
│ 2019-04-25 │ panda_1 │ 18 │
│ 2019-04-25 │ panda_2 │ 18 │
│ 2019-04-25 │ panda_3 │ 18 │
│ 2019-04-25 │ panda_4 │ 18 │
│ 2019-04-25 │ panda_5 │ 18 │
│ 2019-04-25 │ panda_6 │ 18 │
│ 2019-04-25 │ panda_7 │ 18 │
│ 2019-04-25 │ panda_8 │ 18 │
│ 2019-04-25 │ panda_9 │ 18 │
│ 2019-04-25 │ panda_10 │ 18 │
└────────────┴──────────┴─────┘
從2019年起,已經有很多大廠開始在生產環境使用ClickHouse,小編在這里根據各大公司使用情況作了一些總結,適用場景、方案、優化等等。
ClickHouse在攜程酒店數據智能平臺的應用
下圖是攜程實際應用ClickHouse的架構圖,底層數據大部分是離線的,一部分是實時的,離線數據現在大概有將近 3000 多個 job 每天都是把數據從 HIVE 拉到 ClickHouse 里面去,實時數據主要是接外部數據,然后批量寫到 ClickHouse 里面。數據智能平臺 80%以上的數據都在 ClickHouse 上面。
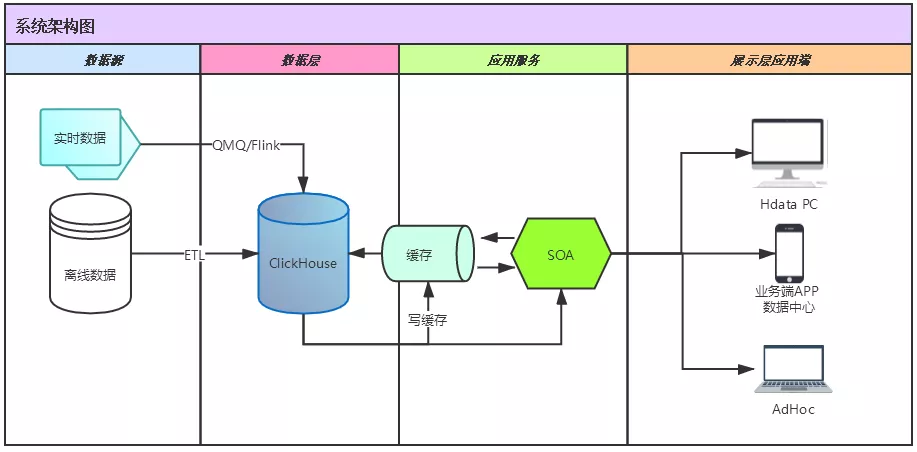
同時,攜程還存在全量數據同步和增量數據同步的場景。
全量數據同步的流程流程如下圖:
清空A_temp表,將最新的數據從Hive通過ETL導入到A_temp表
將A rename 成A_temp_temp
將A_temp rename成 A
將A_temp_temp rename成 A_tem
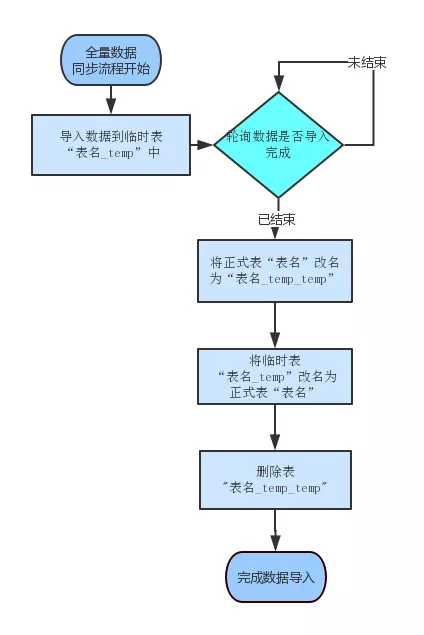
需要注意的是,ClickHouse每執行一個 insert 的時候會產生一個進程 ID,如果沒有執行完,直接 Rename 就會造成數據丟失,數據就不對了,所以必須要有一個 job 在輪詢看這邊是不是執行完了,只有當 insert 的進程 id 執行完成后再做后面一系列的 rename。
增量的數據同步流程入下圖所示:
清空A_temp表,將最近3個月的數據從Hive通過ETL導入到A_temp表
將A表中3個月之前的數據select into到A_temp表
將A rename 成A_temp_temp
將A_temp rename成 A
將A_temp_temp rename成 A_tem
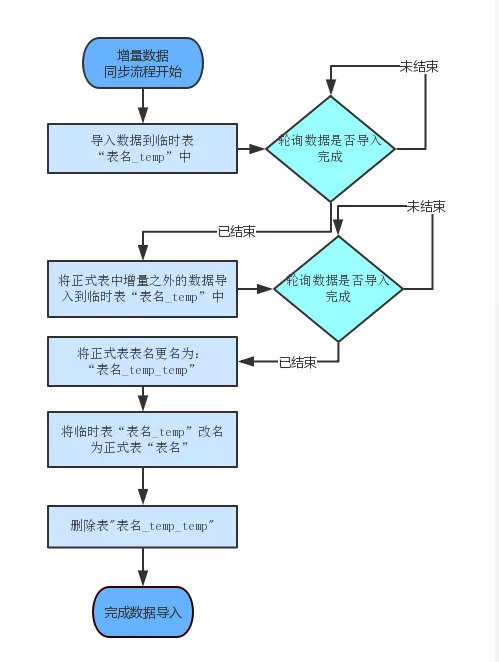
以下是攜程使用ClickHouse的經驗:
1、數據導入之前要評估好分區字段
ClickHouse 因為是根據分區文件存儲的,如果說你的分區字段真實數據粒度很細,數據導入的時候就會把你的物理機打爆。其實數據量可能沒有多少,但是因為你用的字段不合理,會產生大量的碎片文件,磁盤空間就會打到底。
2、數據導入提前根據分區做好排序,避免同時寫入過多分區導致 clickhouse 內部來不及 Merge
數據導入之前我們做好排序,這樣可以降低數據導入后 ClickHouse 后臺異步 Merge 的時候涉及到的分區數,肯定是涉及到的分區數越少服務器壓力也會越小。
3、左右表 join 的時候要注意數據量的變化
再就是左右表 join 的問題,ClickHouse 它必須要大表在左邊,小表在右邊。但是我們可能某些業務場景跑著跑著數據量會返過來了,這個時候我們需要有監控能及時發現并修改這個 join 關系。
4、根據數據量以及應用場景評估是否采用分布式
分布式要根據應用場景來,如果你的應用場景向上匯總后數據量已經超過了單物理機的存儲或者 CPU/內存瓶頸而不得不采用分布式 ClickHouse 也有很完善的 MPP 架構,但同時你也要維護好你的主 keyboard。
5、監控好服務器的 CPU/內存波動
再就是做好監控,我前面說過 ClickHouse 的 CPU 拉到 60%的時候,基本上你的慢查詢馬上就出來了,所以我這邊是有對 CPU 和內存的波動進行監控的,類似于 dump,這個我們抓下來以后就可以做分析。
6、數據存儲磁盤盡量采用 SSD
數據存儲盡量用 SSD,因為我之前也開始用過機械硬盤,機械硬盤有一個問題就是當你的服務器要運維以后需要重啟,這個時候數據要加載,我們現在單機數據量存儲有超過了 200 億以上,這還是我幾個月前統計的。這個數據量如果說用機械硬盤的話,重啟一次可能要等上好幾個小時服務器才可用,所以盡量用 SSD,重啟速度會快很多。
當然重啟也有一個問題就是說會導致你的數據合并出現錯亂,這是一個坑。所以我每次維護機器的時候,同一個集群我不會同時維護幾臺機器,我只會一臺一臺維護,A 機器好了以后會跟它的備用機器對比數據,否則機器起來了,但是數據不一定是對的,并且可能是一大片數據都是不對的。
7、減少數據中文本信息的冗余存儲
要減少一些中文信息的冗余存儲,因為中文信息會導致整個服務器的 IO 很高,特別是導數據的時候。
8、特別適用于數據量大,查詢頻次可控的場景,如數據分析、埋點日志系統
對于它的應用,我認為從成本角度來說,就像以前我們有很多業務數據的修改日志,大家開發的時候可能都習慣性的存到 MySQL 里面,但是實際上我認為這種數據非常適合于落到 ClickHouse 里面,比落到 MySQL 里面成本會更低,查詢速度會更快。
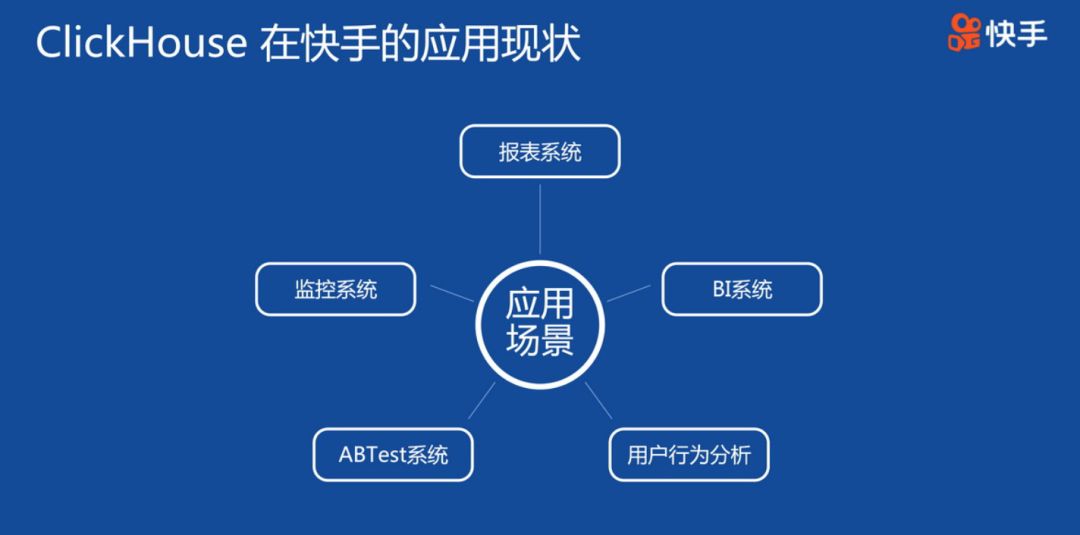
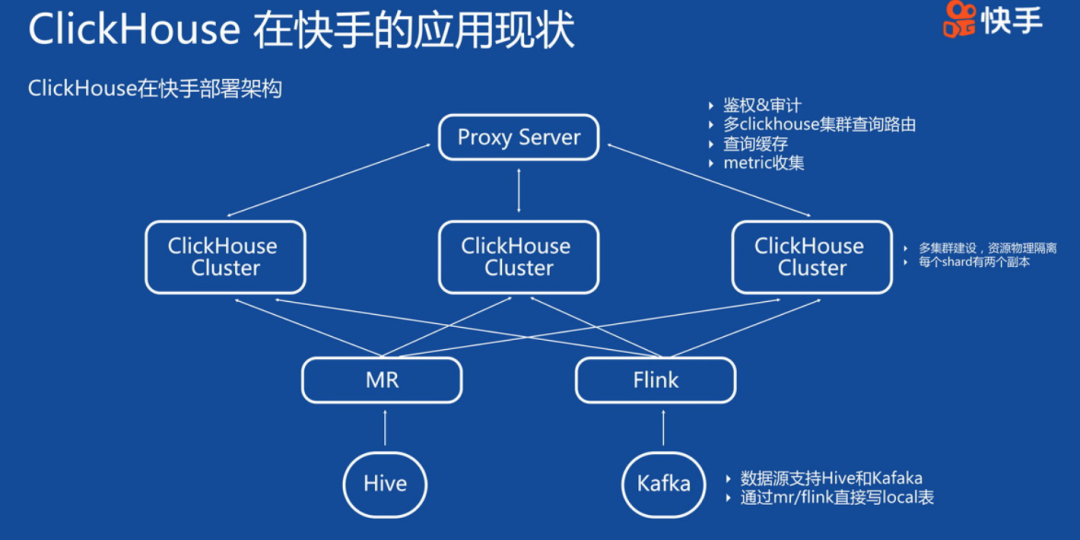
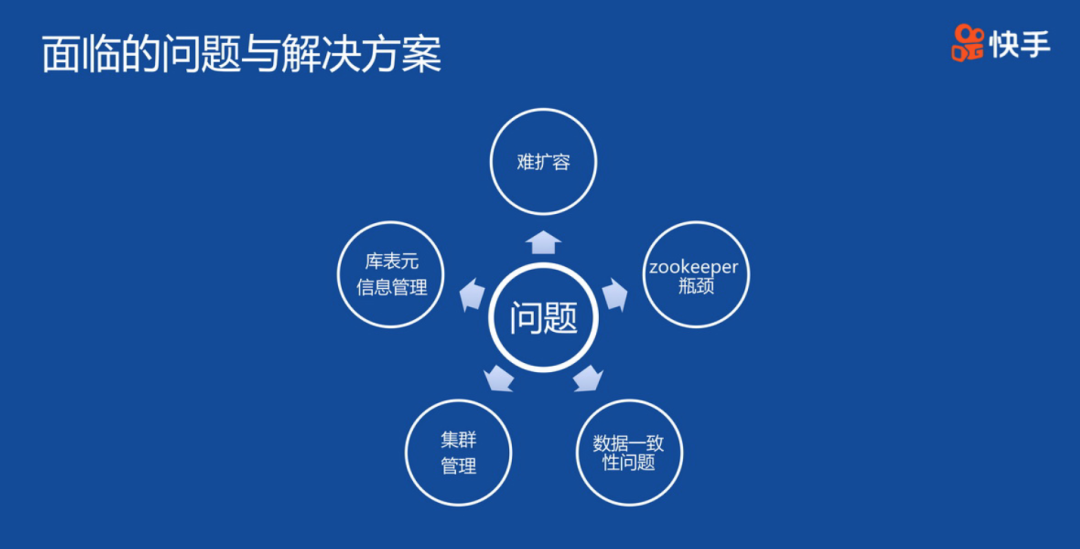
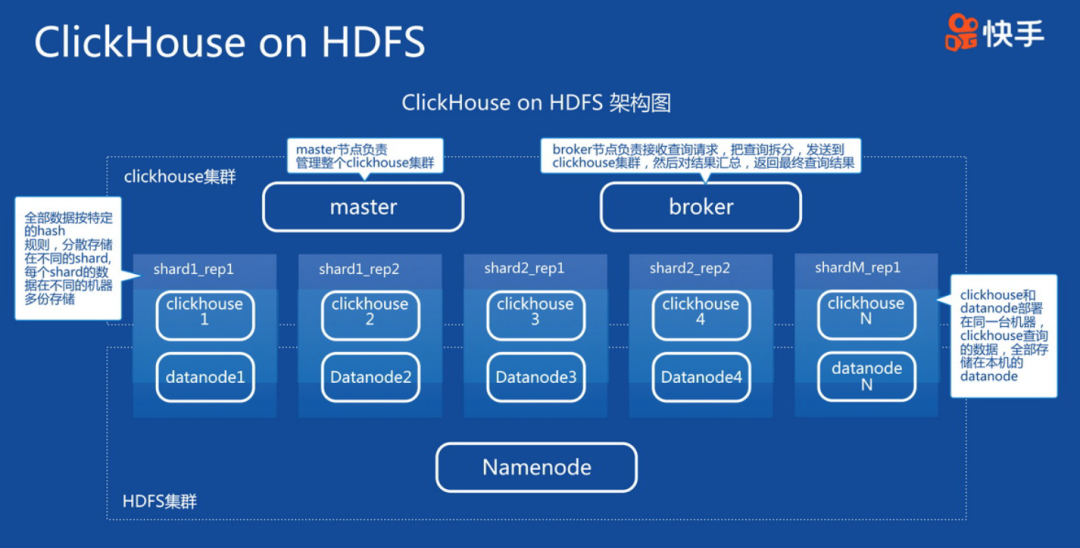
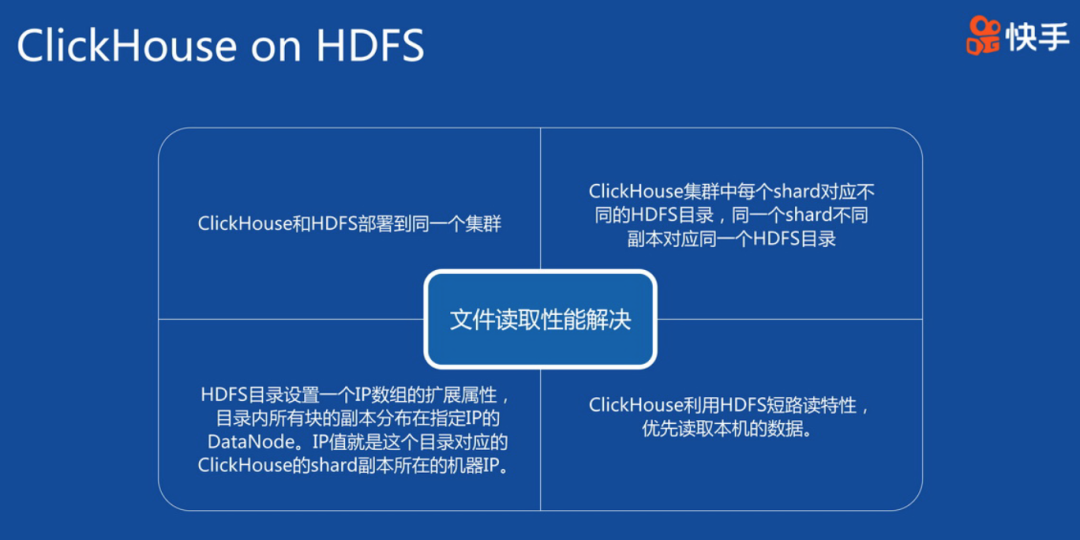
Clickhouse在快手的應用


Clickhouse在QQ的應用
QQ音樂大數據團隊基于ClickHouse+Superset等基礎組件,結合騰訊云EMR產品的云端能力,搭建起高可用、低延遲的實時OLAP分析計算可視化平臺。
集群日均新增萬億數據,規模達到上萬核CPU,PB級數據量。整體實現秒級的實時數據分析、提取、下鉆、監控數據基礎服務,大大提高了大數據分析與處理的工作效率。
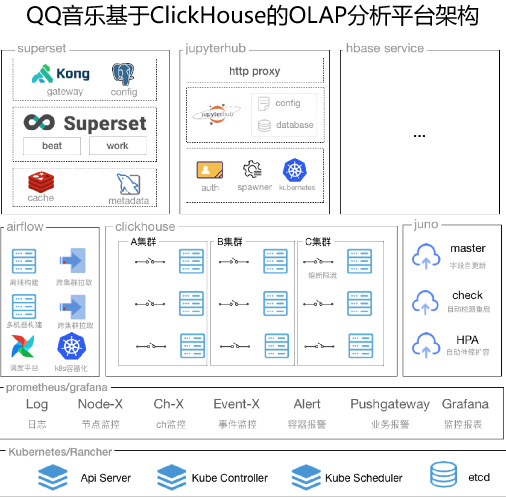
通過OLAP分析平臺,極大降低了探索數據的門檻,做到全民BI,全民數據服務,實現了實時PV、UV、營收、用戶圈層、熱門歌曲等各類指標高效分析,全鏈路數據秒級分析定位,加強數據上報規范,形成一個良好的正循環。
面對上萬核集群規模、PB級的數據量,經過QQ音樂大數據團隊和騰訊云EMR雙方技術團隊無數次技術架構升級優化,性能優化,逐步形成高可用、高性能、高安全的OLAP計算分析平臺。
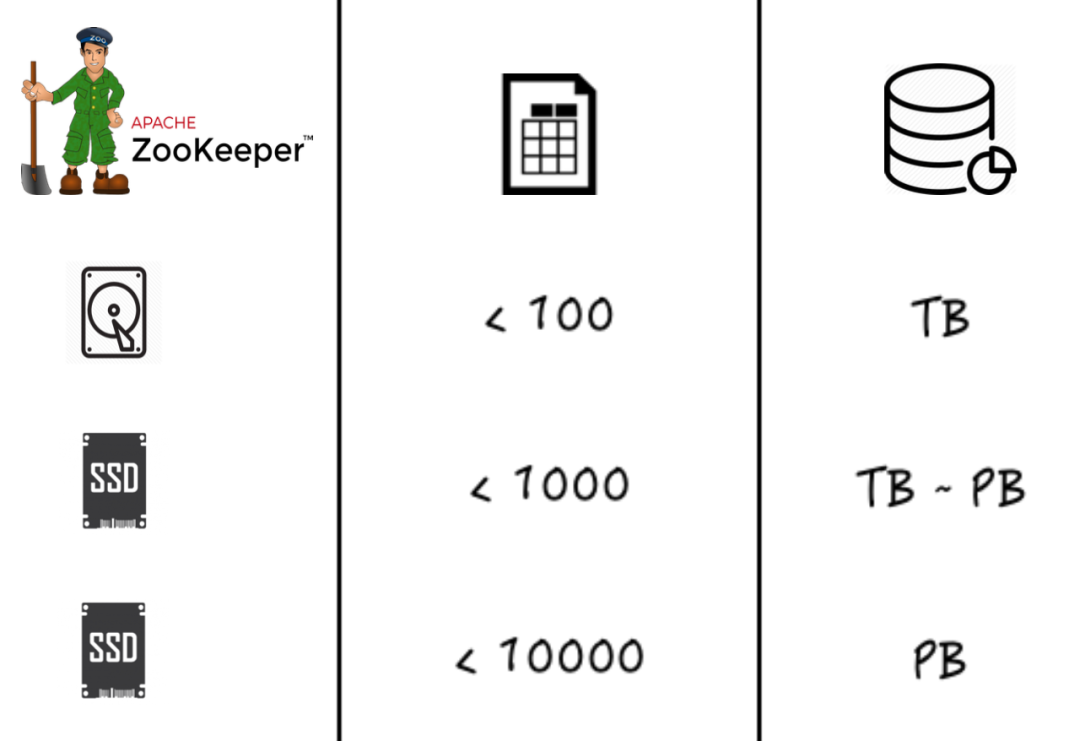
(1)基于SSD盤的ZooKeeper
ClickHouse依賴于ZooKeeper實現分布式系統的協調工作,在ClickHouse并發寫入量較大時,ZooKeeper對元數據存儲處理不及時,會導致ClickHouse副本間同步出現延遲,降低集群整體性能。
解決方案:采用SSD盤的ZooKeeper大幅提高IO的性能,在表個數小于100,數據量級在TB級別時,也可采用HDD盤,其他情況都建議采用SSD盤。
(2)數據寫入一致性
數據在寫入ClickHouse失敗重試后內容出現重復,導致了不同系統,如Hive離線數倉中分析結果,與ClickHouse集群中運算結果不一致。
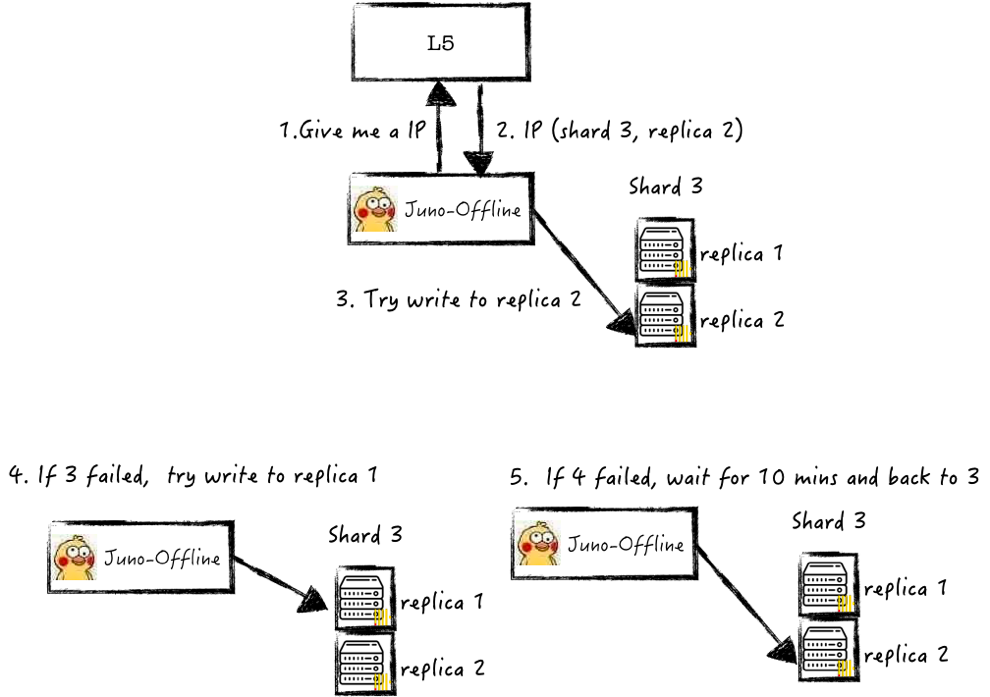
解決方案:基于統一全局的負載均衡調度策略,完成數據失敗后仍然可寫入同一Shard,實現數據冪等寫入,從而保證在ClickHouse中數據一致性。
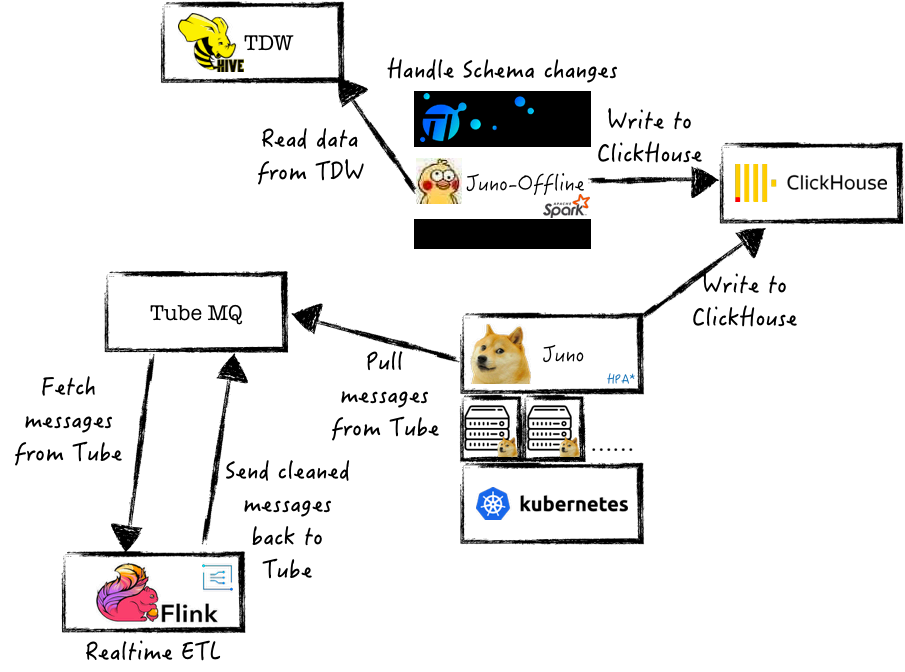
(3)實時離線數據寫入
ClickHouse數據主要來自實時流水上報數據和離線數據中間分析結果數據,如何在架構中完成上萬億基本數據的高效安全寫入,是一個巨大的挑戰。
解決方案:基于Tube消息隊列,完成統一數據的分發消費,基于上述的一致性策略實現數據冪同步,做到實時和離線數據的高效寫入。
(4)表分區數優化
部分離線數據倉庫采用按小時落地分區,如果采用原始的小時分區更新同步,會造成ClickHouse中Select查詢打開大量文件及文件描述符,進而導致性能低下。
解決方案:ClickHouse官方也建議,表分區的數量建議不超過10000,上述的數據同步架構完成小時分區轉換為天分區,同時程序中完成數據冪等消費。
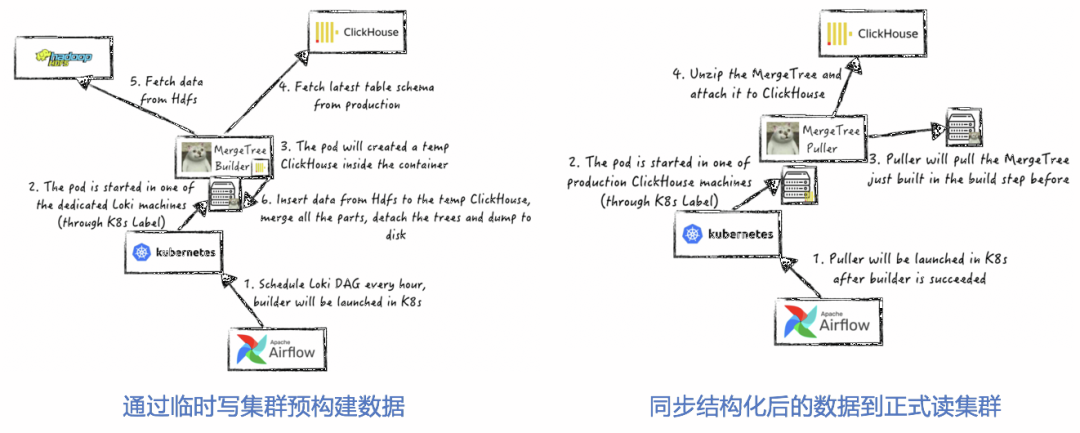
(5)讀/寫分離架構
頻繁的寫動作,會消耗大量CPU/內存/網卡資源,后臺合并線程得不到有效資源,降低Merge Parts速度,MergeTree構建不及時,進而影響讀取效率,導致集群性能降低。
解決方案:ClickHouse臨時節點預先完成數據分區文件構建,動態加載到線上服務集群,緩解ClickHouse在大量并發寫場景下的性能問題,實現高效的讀/寫分離架構,具體步驟和架構如下:
a)利用K8S的彈性構建部署能力,構建臨時ClickHouse節點,數據寫入該節點完成數據的Merge、排序等構建工作;
b)構建完成數據按MergeTree結構關聯至正式業務集群。
當然對一些小數據量的同步寫入,可采用10000條以上批量的寫入。
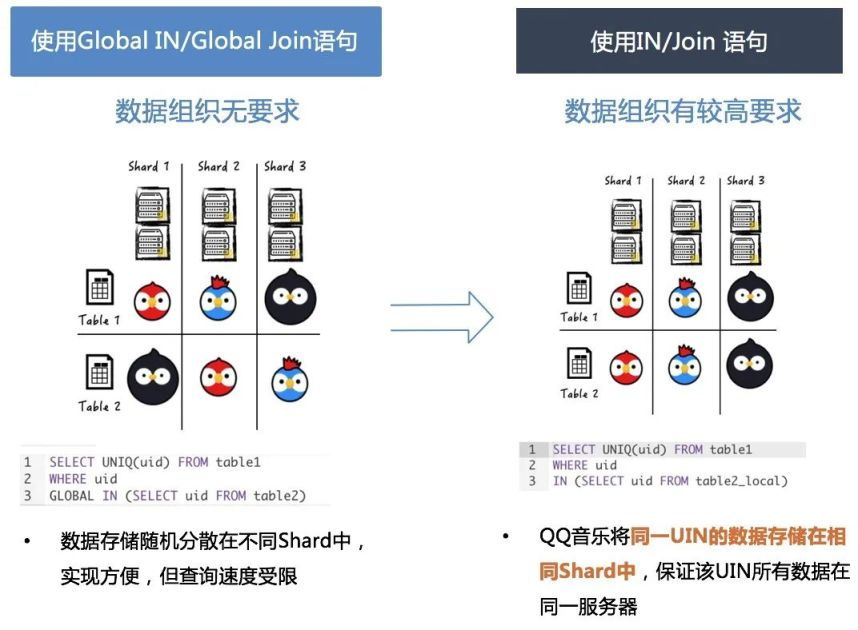
(6)跨表查詢本地化
在ClickHouse集群中跨表進行Select查詢時,采用Global IN/Global Join語句性能較為低下。分析原因,是在此類操作會生成臨時表,并跨設備同步該表,導致查詢速度慢。
解決方案:采用一致性hash,將相同主鍵數據寫入同一個數據分片,在本地local表完成跨表聯合查詢,數據均來自于本地存儲,從而提高查詢速度。
這種優化方案也有一定的潛在問題,目前ClickHouse尚不提供數據的Reshard能力,當Shard所存儲主鍵數據量持續增加,達到磁盤容量上限需要分拆時,目前只能根據原始數據再次重建CK集群,有較高的成本。
ClickHouse從進入大眾視野到開始廣泛應用實踐并不久,ClickHouse社區也在飛速發展中。ClickHouse仍然年輕,雖然在某些方面存在不足,但極致性能的存儲引擎,使得ClickHouse成為一個非常優秀的存儲底座。
感謝各位的閱讀,以上就是“ClickHouse分析數據庫的原理及應用”的內容了,經過本文的學習后,相信大家對ClickHouse分析數據庫的原理及應用這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





