溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python怎么爬取素材網站數據”,在日常操作中,相信很多人在Python怎么爬取素材網站數據問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Python怎么爬取素材網站數據”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
先看下效果圖
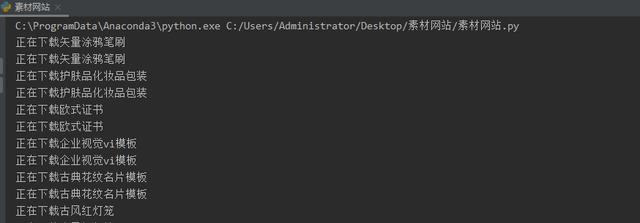
而今天的爬取目標是素材網站
http://www.sccnn.com/
基本環境配置
python 3.6
pycharm
requests
parsel
爬蟲代碼
請求網頁
import requests
import re
url = 'http://www.sccnn.com/shiliangtuku/default({}).html'.format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response.encoding = response.apparent_encoding分析網頁,解析數據
import parsel
r = re.findall('<a href="(.*?)" target="_blank">', response.text)
for i in urls:
page_url = 'http://www.sccnn.com' + i
response_2 = requests.get(url=page_url, headers=headers)
response_2.encoding = response_2.apparent_encoding
selector = parsel.Selector(response_2.text)
title = selector.css('#LeftBox h3::text').get()
img_url = selector.css('#LeftBox .PhotoDiv img::attr(src)').get()保存數據
def downlaod(title, url):
path = 'D:\\python\\demo\\素材網站\\img\\' + title + '.jpg'
response = requests.get(url=url, headers=headers)
with open(path, mode='wb') as f:
f.write(response.content)
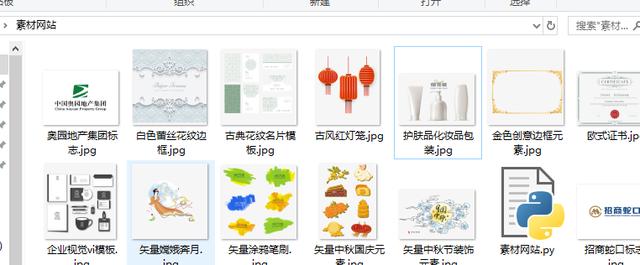
print('正在下載{}'.format(title))運行效果:
到此,關于“Python怎么爬取素材網站數據”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





