溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Python如何爬取實習僧招聘網站”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Python如何爬取實習僧招聘網站”這篇文章吧。
本次任務背景:
https://www.shixiseng.com
爬取一下實習僧IT互聯網的Python實習信息
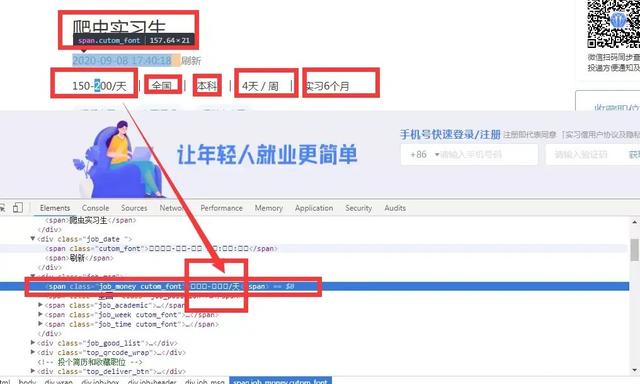
如上圖所示,該字段的數據看不見,可能它不希望你很簡單的就獲得它網站的這些數據,這些數據對他來說比較重要,所以啟用了反爬技巧
如果直接運行,這些數據是爬取不下來的,如下圖:
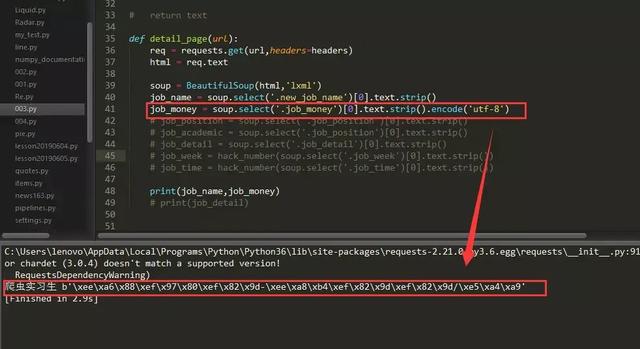
如上圖,相關數據已經以“utf-8”編碼的方式呈現出來
創建函數hack_number(),用于解碼數字

編寫好相關代碼之后,查看運行結果
完整代碼如下:
import requests
from bs4 import BeautifulSoup
headers = {"user-agent":"Mozilla/5.0"}
def hack_number(text):
text = text.encode('utf-8')
text = text.replace(b'\xef\x82\x9d', b'0')
text = text.replace(b'\xee\xa6\x88', b'1')
text = text.replace(b'\xee\xa8\xb4', b'2')
text = text.replace(b'\xef\x91\xbe', b'3')
text = text.replace(b'\xee\x88\x9d', b'4')
text = text.replace(b'\xef\x97\x80', b'5')
text = text.replace(b'\xee\x85\x9f', b'6')
text = text.replace(b'\xee\x98\x92', b'7')
text = text.replace(b'\xef\x80\x95', b'8')
text = text.replace(b'\xef\x94\x9b', b'9')
text = text.decode()
return text
def detail_page(url):
req = requests.get(url,headers=headers)
html = req.text
soup = BeautifulSoup(html,'lxml')
job_name = soup.select('.new_job_name')[0].text.strip()
job_money = hack_number(soup.select('.job_money')[0].text.strip())
job_position = soup.select('.job_position')[0].text.strip()
job_academic = soup.select('.job_academic')[0].text.strip()
job_detail = soup.select('.job_detail')[0].text.strip()
job_week = hack_number(soup.select('.job_week')[0].text.strip())
job_time = hack_number(soup.select('.job_time')[0].text.strip())
print(job_name,job_money,job_position,job_academic,job_week,job_time)
print(job_detail)
#detail_page('https://www.shixiseng.com/intern/inn_1k3vhcwwguaf?pcm=pc_SearchList')
#detail_page('https://www.shixiseng.com/intern/inn_uk1lm380lngh?pcm=pc_SearchList')
#detail_page('https://www.shixiseng.com/intern/inn_fr1o1nii5knw?pcm=pc_SearchList')
for pages in range(1,3):
url = f'https://www.shixiseng.com/interns?page={pages}&keyword=Python&type=intern&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E8%B4%B5%E9%98%B3&internExtend='
req = requests.get(url,headers=headers)
html = req.text
soup = BeautifulSoup(html,'lxml')
for item in soup.select('a.title ellipsis font'):
detail_url = f"https://www.shixiseng.com{item.get('href')}"
detail_page(detail_url)以上是“Python如何爬取實習僧招聘網站”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





