溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么理解web的時間與空間復雜度”,在日常操作中,相信很多人在怎么理解web的時間與空間復雜度問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么理解web的時間與空間復雜度”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
算法(Algorithm)是指用來操作數據、解決程序問題的一組方法。對于同一個問題,使用不同的算法,也許最終得到的結果是一樣的,比如排序就有前面的十大經典排序和幾種奇葩排序,雖然結果相同,但在過程中消耗的資源和時間卻會有很大的區別,比如快速排序與猴子排序:)。
那么我們應該如何去衡量不同算法之間的優劣呢?
主要還是從算法所占用的「時間」和「空間」兩個維度去考量。
時間維度:是指執行當前算法所消耗的時間,我們通常用「時間復雜度」來描述。
空間維度:是指執行當前算法需要占用多少內存空間,我們通常用「空間復雜度」來描述。
大O表示法:算法的時間復雜度通常用大O符號表述,定義為 T[n] = O(f(n))。稱函數T(n)以f(n)為界或者稱T(n)受限于f(n)。
如果一個問題的規模是n,解這一問題的某一算法所需要的時間為T(n)。T(n)稱為這一算法的“時間復雜度”。
上面公式中用到的 Landau符號是由德國數論學家保羅·巴赫曼(Paul Bachmann)在其1892年的著作《解析數論》首先引入,由另一位德國數論學家艾德蒙·朗道(Edmund Landau)推廣。Landau符號的作用在于用簡單的函數來描述復雜函數行為,給出一個上或下(確)界。在計算算法復雜度時一般只用到大O符號,Landau符號體系中的小o符號、Θ符號等等比較不常用。這里的O,最初是用大寫希臘字母,但現在都用大寫英語字母O;小o符號也是用小寫英語字母o,Θ符號則維持大寫希臘字母Θ。
大O符號是一種算法「復雜度」的「相對」「表示」方式。
這個句子里有一些重要而嚴謹的用詞:
相對(relative):你只能比較相同的事物。你不能把一個做算數乘法的算法和排序整數列表的算法進行比較。但是,比較2個算法所做的算術操作(一個做乘法,一個做加法)將會告訴你一些有意義的東西;
表示(representation):大O(用它最簡單的形式)把算法間的比較簡化為了一個單一變量。這個變量的選擇基于觀察或假設。例如,排序算法之間的對比通常是基于比較操作(比較2個結點來決定這2個結點的相對順序)。這里面就假設了比較操作的計算開銷很大。但是,如果比較操作的計算開銷不大,而交換操作的計算開銷很大,又會怎么樣呢?這就改變了先前的比較方式;
復雜度(complexity):如果排序10,000個元素花費了我1秒,那么排序1百萬個元素會花多少時間?在這個例子里,復雜度就是相對其他東西的度量結果。
我們先從常見的時間復雜度量級進行大O的理解:
常數階O(1)
線性階O(n)
平方階O(n2)
對數階O(logn)
線性對數階O(nlogn)
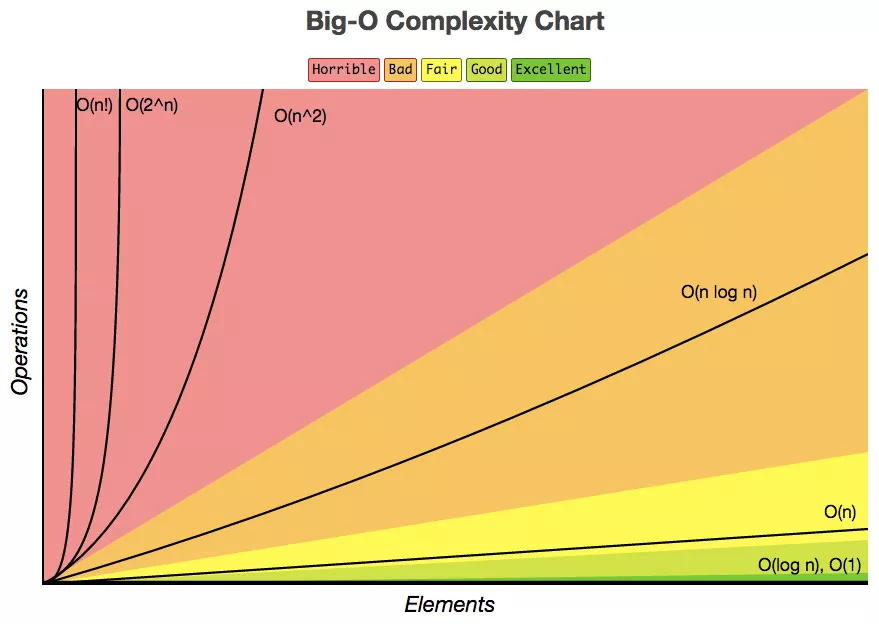

無論代碼執行了多少行,其他區域不會影響到操作,這個代碼的時間復雜度都是O(1)
void swapTwoInts(int &a, int &b){
int temp = a;
a = b;
b = temp;
}
在下面這段代碼,for循環里面的代碼會執行 n 遍,因此它消耗的時間是隨著 n 的變化而變化的,因此可以用O(n)來表示它的時間復雜度。
int sum ( int n ){
int ret = 0;
for ( int i = 0 ; i <= n ; i ++){
ret += i;
}
return ret;
}特別一提的是 c * O(n) 中的 c 可能小于 1 ,比如下面這段代碼:
void reverse ( string &s ) {
int n = s.size();
for (int i = 0 ; i < n/2 ; i++){
swap ( s[i] , s[n-1-i]);
}
}
當存在雙重循環的時候,即把 O(n) 的代碼再嵌套循環一遍,它的時間復雜度就是 O(n2) 了。
void selectionSort(int arr[],int n){
for(int i = 0; i < n ; i++){
int minIndex = i;
for (int j = i + 1; j < n ; j++ )
if (arr[j] < arr[minIndex])
minIndex = j;
swap ( arr[i], arr[minIndex]);
}
}這里簡單的推導一下
當 i = 0 時,第二重循環需要運行 (n - 1) 次
當 i = 1 時,第二重循環需要運行 (n - 2) 次
。。。。。。
不難得到公式:
(n - 1) + (n - 2) + (n - 3) + ... + 0 = (0 + n - 1) * n / 2 = O (n ^2)
當然并不是所有的雙重循環都是 O(n2),比如下面這段輸出 30n 次Hello,五分鐘學算法:)的代碼。
void printInformation (int n ){
for (int i = 1 ; i <= n ; i++)
for (int j = 1 ; j <= 30 ; j ++)
cout<< "Hello,五分鐘學算法:)"<< endl;
}int binarySearch( int arr[], int n , int target){
int l = 0, r = n - 1;
while ( l <= r) {
int mid = l + (r - l) / 2;
if (arr[mid] == target) return mid;
if (arr[mid] > target ) r = mid - 1;
else l = mid + 1;
}
return -1;
}在二分查找法的代碼中,通過while循環,成 2 倍數的縮減搜索范圍,也就是說需要經過 log2^n 次即可跳出循環。
同樣的還有下面兩段代碼也是 O(logn) 級別的時間復雜度。
// 整形轉成字符串
string intToString ( int num ){
string s = "";
// n 經過幾次“除以10”的操作后,等于0
while (num ){
s += '0' + num%10;
num /= 10;
}
reverse(s)
return s;
}void hello (int n ) {
// n 除以幾次 2 到 1
for ( int sz = 1; sz < n ; sz += sz)
for (int i = 1; i < n; i++)
cout<< "Hello,五分鐘學算法:)"<< endl;
}將時間復雜度為O(logn)的代碼循環N遍的話,那么它的時間復雜度就是 n * O(logn),也就是了O(nlogn)。
void hello (){
for( m = 1 ; m < n ; m++){
i = 1;
while( i < n ){
i = i * 2;
}
}
}下面來分析一波另外幾種復雜度: 遞歸算法的時間復雜度(recursive algorithm time complexity),最好情況時間復雜度(best case time complexity)、最壞情況時間復雜度(worst case time complexity)、平均時間復雜度(average case time complexity)和均攤時間復雜度(amortized time complexity)。
如果遞歸函數中,只進行一次遞歸調用,遞歸深度為depth;
在每個遞歸的函數中,時間復雜度為T;
則總體的時間復雜度為O(T * depth)。
在前面的學習中,歸并排序 與 快速排序 都帶有遞歸的思想,并且時間復雜度都是O(nlogn) ,但并不是有遞歸的函數就一定是 O(nlogn) 級別的。從以下兩種情況進行分析。
① 遞歸中進行一次遞歸調用的復雜度分析
二分查找法
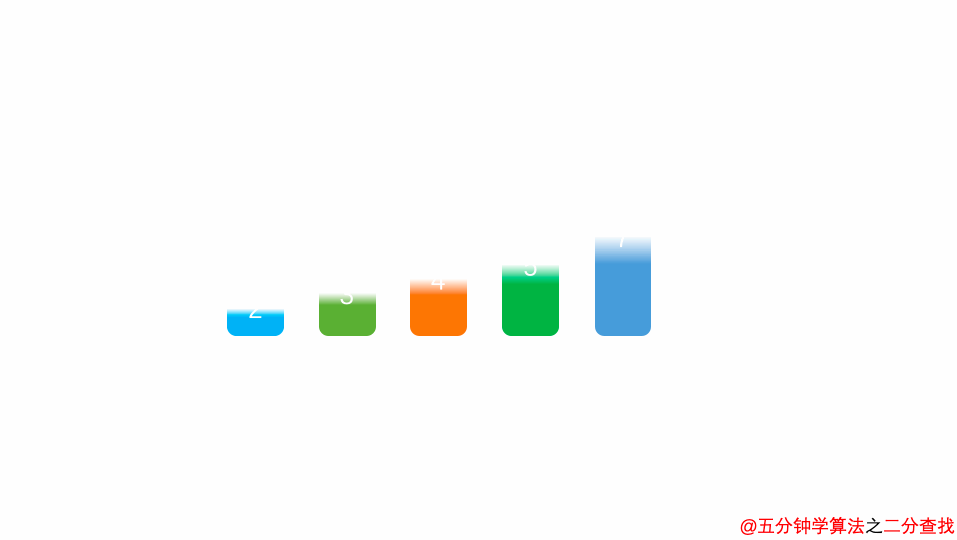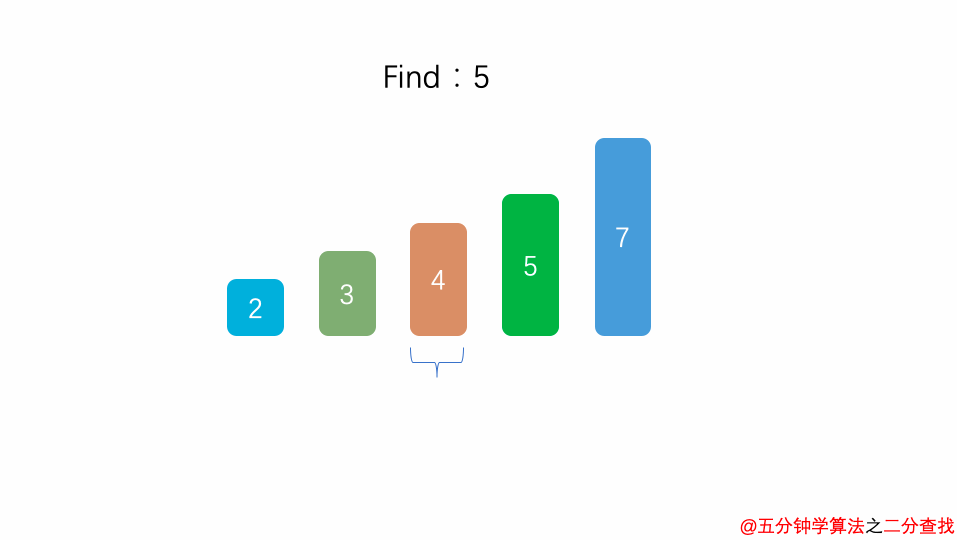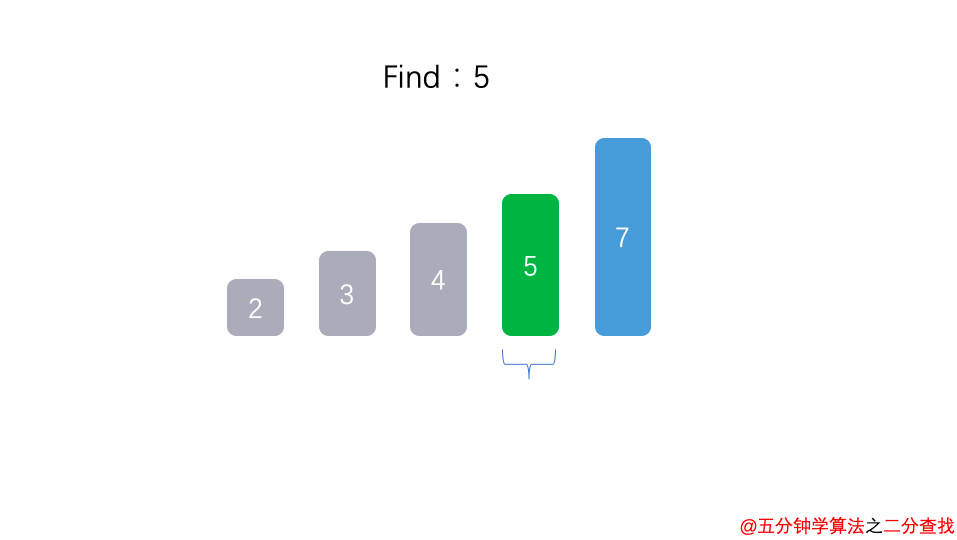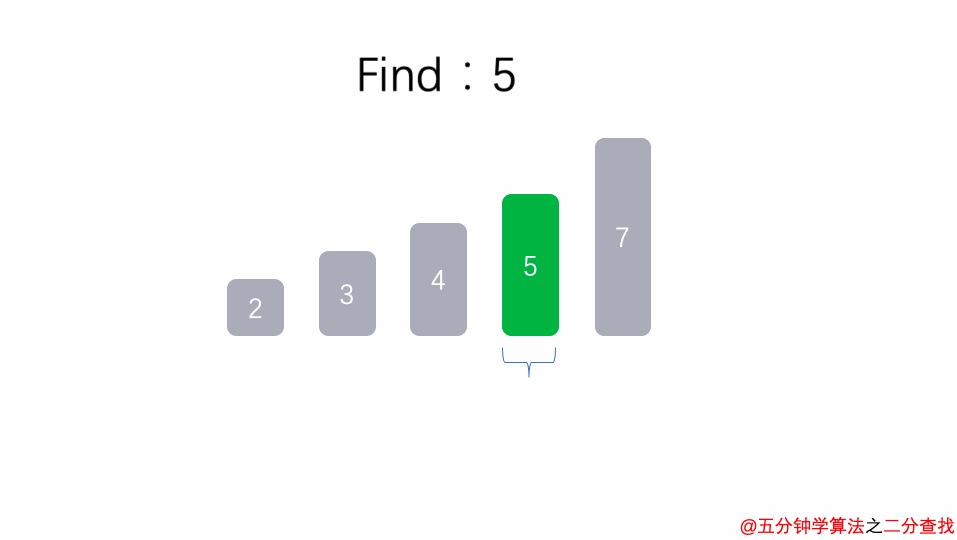
int binarySearch(int arr[], int l, int r, int target){
if( l > r ) return -1;
int mid = l + (r-l)/2;
if( arr[mid] == target ) return mid;
else if( arr[mid] > target )
return binarySearch(arr, l, mid-1, target); // 左邊
else
return binarySearch(arr, mid+1, r, target); // 右邊
}比如在這段二分查找法的代碼中,每次在 [ l , r ] 范圍中去查找目標的位置,如果中間的元素arr[mid]不是target,那么判斷arr[mid]是比target大 還是 小 ,進而再次調用binarySearch這個函數。
在這個遞歸函數中,每一次沒有找到target時,要么調用 左邊 的binarySearch函數,要么調用 右邊 的binarySearch函數。也就是說在此次遞歸中,最多調用了一次遞歸調用而已。根據數學知識,需要log2n次才能遞歸到底。因此,二分查找法的時間復雜度為 O(logn)。
求和

int sum (int n) {
if (n == 0) return 0;
return n + sum( n - 1 )
}在這段代碼中比較容易理解遞歸深度隨輸入 n 的增加而線性遞增,因此時間復雜度為 O (n)。
求冪

//遞歸深度:logn
//時間復雜度:O(logn)
double pow( double x, int n){
if (n == 0) return 1.0;
double t = pow(x,n/2);
if (n %2) return x*t*t;
return t * t;
}遞歸深度為logn,因為是求需要除以 2 多少次才能到底。
② 遞歸中進行多次遞歸調用的復雜度分析
遞歸算法中比較難計算的是多次遞歸調用。
先看下面這段代碼,有兩次遞歸調用。
// O(2^n) 指數級別的數量級,后續動態規劃的優化點
int f(int n){
if (n == 0) return 1;
return f(n-1) + f(n - 1);
}
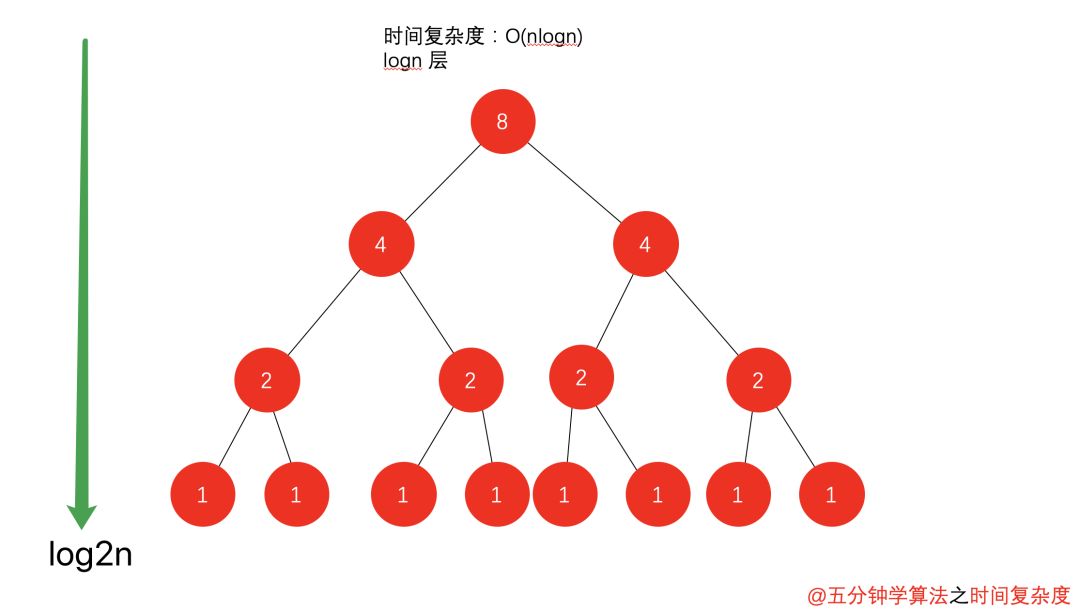
與之有所類似的是 歸并排序 的遞歸樹,區別點在于
1. 上述例子中樹的深度為n,而 歸并排序 的遞歸樹深度為logn。
2. 上述例子中每次處理的數據規模是一樣的,而在 歸并排序 中每個節點處理的數據規模是逐漸縮小的
因此,在如 歸并排序 等排序算法中,每一層處理的數據量為 O(n) 級別,同時有logn層,時間復雜度便是 O(nlogn)。

最好、最壞情況時間復雜度指的是特殊情況下的時間復雜度。
動圖表明的是在數組 array 中尋找變量 x 第一次出現的位置,若沒有找到,則返回 -1;否則返回位置下標。
int find(int[] array, int n, int x) {
for ( int i = 0 ; i < n; i++) {
if (array[i] == x) {
return i;
break;
}
}
return -1;
}在這里當數組中第一個元素就是要找的 x 時,時間復雜度是 O(1);而當最后一個元素才是 x 時,時間復雜度則是 O(n)。
最好情況時間復雜度就是在最理想情況下執行代碼的時間復雜度,它的時間是最短的;最壞情況時間復雜度就是在最糟糕情況下執行代碼的時間復雜度,它的時間是最長的。
最好、最壞時間復雜度反應的是極端條件下的復雜度,發生的概率不大,不能代表平均水平。那么為了更好的表示平均情況下的算法復雜度,就需要引入平均時間復雜度。
平均情況時間復雜度可用代碼在所有可能情況下執行次數的加權平均值表示。
還是以find函數為例,從概率的角度看, x 在數組中每一個位置的可能性是相同的,為 1 / n。那么,那么平均情況時間復雜度就可以用下面的方式計算:
((1 + 2 + … + n) / n + n) / 2 = (3n + 1) / 4
find函數的平均時間復雜度為 O(n)。
我們通過一個動態數組的push_back操作來理解均攤復雜度。

template <typename T>
class MyVector{
private:
T* data;
int size; // 存儲數組中的元素個數
int capacity; // 存儲數組中可以容納的最大的元素個數
// 復雜度為 O(n)
void resize(int newCapacity){
T *newData = new T[newCapacity];
for( int i = 0 ; i < size ; i ++ ){
newData[i] = data[i];
}
data = newData;
capacity = newCapacity;
}
public:
MyVector(){
data = new T[100];
size = 0;
capacity = 100;
}
// 平均復雜度為 O(1)
void push_back(T e){
if(size == capacity)
resize(2 * capacity);
data[size++] = e;
}
// 平均復雜度為 O(1)
T pop_back(){
size --;
return data[size];
}
};push_back實現的功能是往數組的末尾增加一個元素,如果數組沒有滿,直接往后面插入元素;如果數組滿了,即size == capacity,則將數組擴容一倍,然后再插入元素。
例如,數組長度為 n,則前 n 次調用push_back復雜度都為 O(1) 級別;在第 n + 1 次則需要先進行 n 次元素轉移操作,然后再進行 1 次插入操作,復雜度為 O(n)。
因此,平均來看:對于容量為 n 的動態數組,前面添加元素需要消耗了 1 * n 的時間,擴容操作消耗 n 時間 ,
總共就是 2 * n 的時間,因此均攤時間復雜度為 O(2n / n) = O(2),也就是 O(1) 級別了。
可以得出一個比較有意思的結論:一個相對比較耗時的操作,如果能保證它不會每次都被觸發,那么這個相對比較耗時的操作,它所相應的時間是可以分攤到其它的操作中來的。
一個程序的空間復雜度是指運行完一個程序所需內存的大小。利用程序的空間復雜度,可以對程序的運行所需要的內存多少有個預先估計。一個程序執行時除了需要存儲空間和存儲本身所使用的指令、常數、變量和輸入數據外,還需要一些對數據進行操作的工作單元和存儲一些為現實計算所需信息的輔助空間。程序執行時所需存儲空間包括以下兩部分:
(1) 固定部分,這部分空間的大小與輸入/輸出的數據的個數多少、數值無關。主要包括指令空間(即代碼空間)、數據空間(常量、簡單變量)等所占的空間。這部分屬于靜態空間。
(2) 可變空間,這部分空間的主要包括動態分配的空間,以及遞歸棧所需的空間等。這部分的空間大小與算法有關。
一個算法所需的存儲空間用f(n)表示。S(n)=O(f(n)),其中n為問題的規模,S(n)表示空間復雜度。
空間復雜度可以理解為除了原始序列大小的內存,在算法過程中用到的額外的存儲空間。
以二叉查找樹為例,舉例說明二叉排序樹的查找性能。
如果二叉樹的是以紅黑樹等平衡二叉樹實現的,則 n 個節點的二叉排序樹的高度為 log2n+1 ,其查找效率為O(Log2n),近似于折半查找。
如果二叉樹退變為列表了,則 n 個節點的高度或者說是長度變為了n,查找效率為O(n),變成了順序查找。
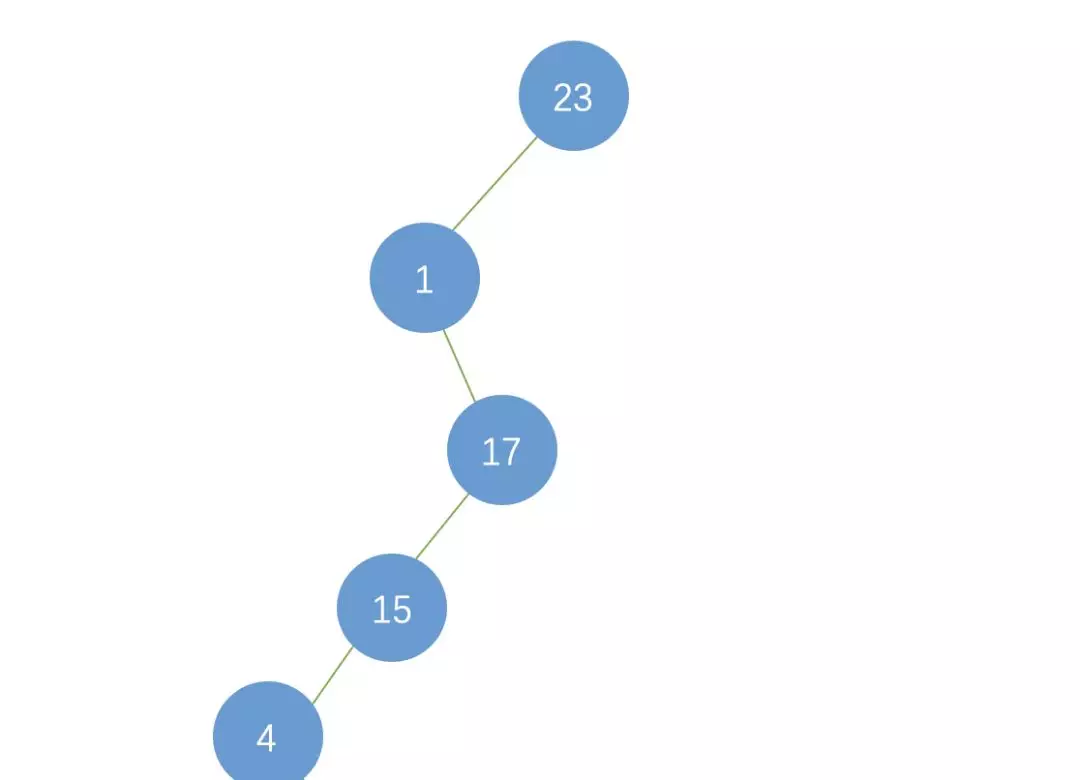
介于「列表二叉樹」與「平衡二叉樹」之間,查找性能也在O(Log2n)到O(n)之間。
對于一個算法,其時間復雜度和空間復雜度往往是相互影響的。
比如說,要判斷某某年是不是閏年:
1. 可以編寫一個算法來計算,這也就意味著,每次給一個年份,都是要通過計算得到是否是閏年的結果。
2. 還有另一個辦法就是,事先建立一個有 5555 個元素的數組(年數比現實多就行),然后把所有的年份按下標的數字對應,如果是閏年,此數組項的值就是1,如果不是值為0。這樣,所謂的判斷某一年是否是閏年,就變成了查找這個數組的某一項的值是多少的問題。此時,我們的運算是最小化了,但是硬盤上或者內存中需要存儲這 5555 個 0 和 1 。
這就是典型的使用空間換時間的概念。
當追求一個較好的時間復雜度時,可能會使空間復雜度的性能變差,即可能導致占用較多的存儲空間;
反之,求一個較好的空間復雜度時,可能會使時間復雜度的性能變差,即可能導致占用較長的運行時間。
另外,算法的所有性能之間都存在著或多或少的相互影響。因此,當設計一個算法(特別是大型算法)時,要綜合考慮算法的各項性能,算法的使用頻率,算法處理的數據量的大小,算法描述語言的特性,算法運行的機器系統環境等各方面因素,才能夠設計出比較好的算法。
到此,關于“怎么理解web的時間與空間復雜度”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





