溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下怎么通過postgresql數據倉庫實現湖倉一體數據分析,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
// 一.背景
隨著云計算的普及和數據分析需求的擴大,數據湖+數據倉庫的湖倉一體分析能力成為下一代數據分析系統的核心能力。相對于數據倉庫,數據湖在成本、靈活性、多源數據分析等多方面,都有著非常明顯的優勢。IDC發布的十項2021年中國云計算市場趨勢預測中,有三項和數據湖分析有關。可以預見,跨系統集成能力、數據控制能力和更加全面的數據驅動能力,將會是未來數據分析系統重要的競爭領域。
AnalyticDB PostgreSQL版(簡稱ADB PG)是阿里云數據庫團隊基于PostgreSQL內核(簡稱PG)打造的一款云原生數據倉庫產品。在PB級數據實時交互式分析、HTAP、ETL、BI報表生成等業務場景,ADB PG都有著獨特的技術優勢。作為一個數據倉庫產品,ADB PG是如何具備湖倉一體分析能力呢?本文將會介紹ADB PG如何基于PG外表、打造數據湖分析能力。
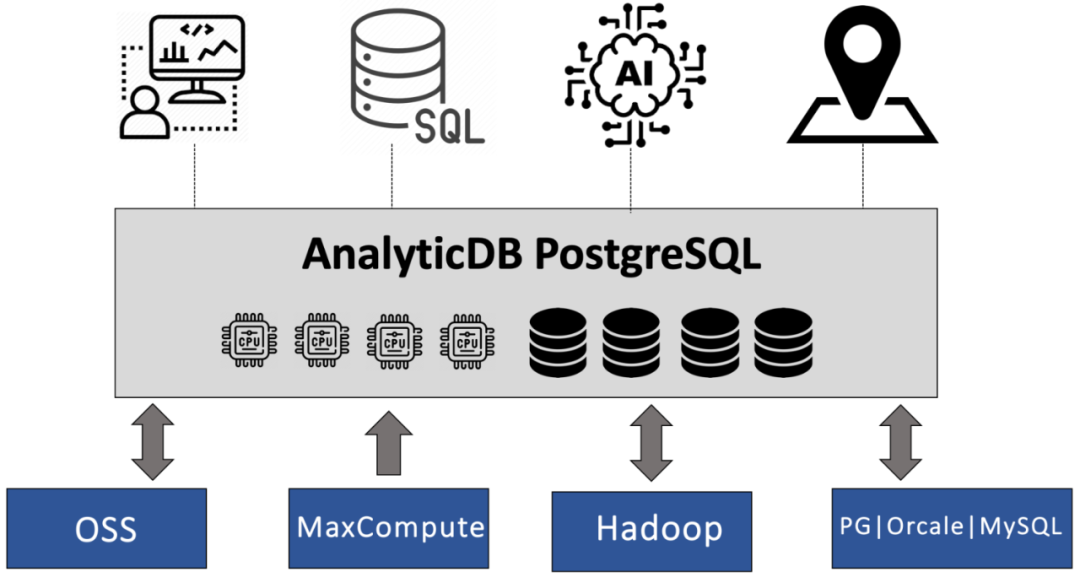
ADB PG繼承了PG的外表(Foreign Table)功能,目前ADB PG的湖倉一體能力主要是基于外表打造的。基于PG外表,ADB PG可以對其他數據分析系統的數據進行查詢和寫入,在兼容多種數據源的同時,復用ADB PG原有的優化器和執行引擎優勢。ADB PG的湖倉一體分析能力目前已經支持OSS、MaxCompute、Hadoop、RDS PG、Oracle、RDS MySQL等多種數據源的分析或者寫入。用戶可以靈活地將ADB PG應用于數據存儲、交互式分析、ETL等不同領域,可以在單個實例中實現多種數據分析功能。即可以用ADB PG完成數據分析的核心流程,也可以作為眾多環節中的一環去搭建數據鏈路。
不過,外表數據的分析依賴于外部SDK和網絡IO來實現數據讀寫,由于網絡本身的特性與本地磁盤有巨大差異,因此需要在技術層面與本地存儲不同、需要不同的性能優化方案。本文以OSS外表數據讀寫為例,介紹ADB PG在構建湖倉一體分析能力時,所遇到的一些重要問題和解決方案。
// 二.問題分析
ADB PG內核可以分為優化器、執行引擎和存儲引擎。外表數據分析可以復用ADB PG原有的優化器和執行引擎的核心部分,僅需少量修改。主要擴展是存儲引擎層的改造,也就是通過外表接口對外表數據進行讀寫。外表數據是存儲在另一個分布式系統當中,需要通過網絡與ADB PG進行連接,這是和讀取本地文件的最核心的區別。一方面,不同的外表數據會提供不同的遠程訪問接口,需要在工程上進行兼容,比如OSS、MaxCompute的數據讀取接口都不相同。另一方面,通過網絡訪問遠程機器上的數據有一定的共性,比如網絡的延遲、網絡放大、帶寬限制、網絡穩定性問題等。
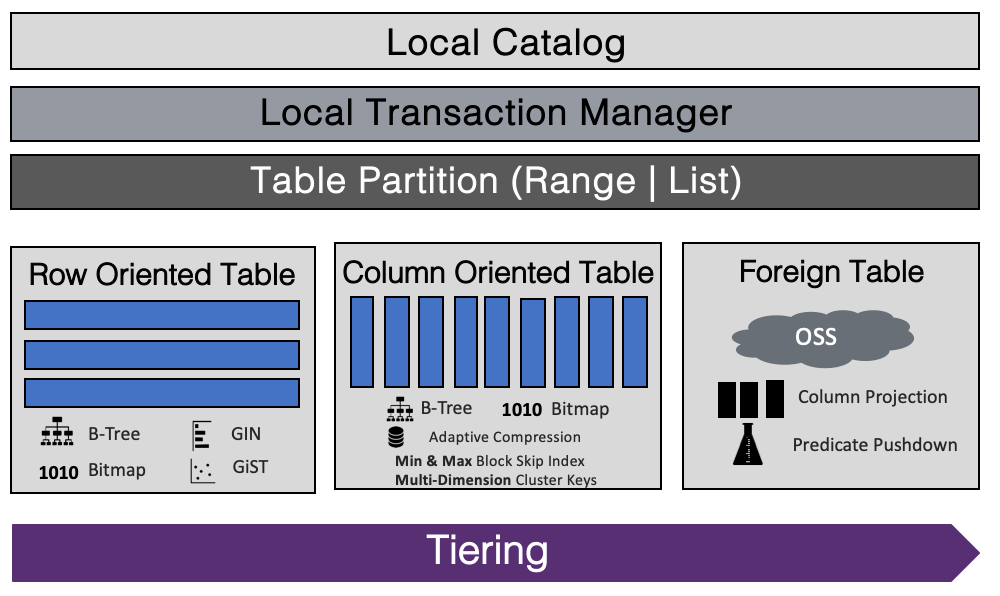
本文將會圍繞上述核心挑戰,介紹ADB PG外表分析項目在支持OSS數據分析過程中的一些重要技術點。OSS是一種阿里云推出的一種低成本分布式存儲系統,存儲了大量的冷熱數據,有較大的數據分析需求。為了方便開發者進行擴展,OSS提供了基于Java、Go、C/C++、Python等主流開發語言的SDK。ADB PG采用了OSS C SDK進行開發。目前ADB PG已經完美支持OSS外表分析的各項功能,除建表語句不同外,用戶可以像訪問本地表一樣訪問OSS外表。支持并發讀取和寫入,支持CSV、ORC、Parquet等常見數據格式。
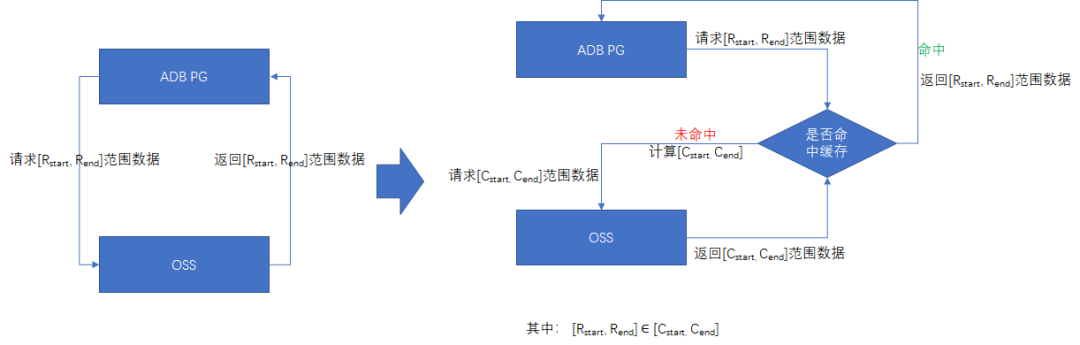
3.2 列過濾與謂詞下推
由于網絡本身的IO性能往往是低于本地存儲的IO性能的,因此在掃描外表數據時,要盡量減少IO的帶寬資源消耗。ADB PG在處理ORC、Parquet格式的文件時,采用了列過濾和謂詞下推技術,來達到這一目的。
列過濾,即外表只請求SQL查詢所需的數據列、忽略不需要的數據列。因為ORC、Parquet都是列式存儲格式,所以外表在發起網絡請求時,只需請求所需列所在的數據范圍即可,從而大幅減小網絡I/O。同時,ORC、Parquet會對列數據進行壓縮處理,進一步減小I/O。
謂詞下推,是將執行計劃里的上層的過濾條件(如WHERE子句中的條件),移動到下層的外表掃描節點,使外表掃描進行網絡請求時,過濾掉不符合查詢條件的數據塊,從而減少網絡I/O。在ORC/Parquet格式文件中,會在每一個block頭部保存該block中每一列數據的min/max/sum等統計信息,當外表掃描時,會先讀取該block的頭部統計信息,與下推的查詢條件進行比較,如果該列的統計信息不符合查詢條件,則可以直接跳過該列數據。
這里簡單介紹ORC格式的外表的謂詞下推的實現方案。一個ORC文件按數據行分成若干個Stripe組成,Stripe中數據按列式存儲。每個Stripe又分為若干個Row Group, 所有列的每 10000行 組成一個Row Group。如下圖所示。
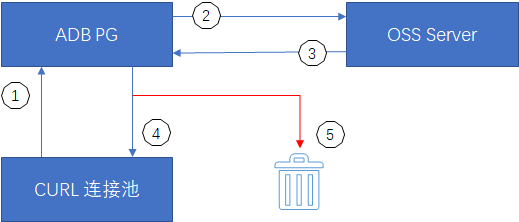
① ADB PG訪問OSS外表時,先從CURL連接池中獲取連接,若不存在則新建。
② ADB PG使用CURL連接句柄與OSS Server請求通信。
③ OSS Server通過CURL連接句柄返回通信結果。
④ 正常返回的CURL連接句柄使用完畢后加回連接池待下次使用。
⑤ 異常狀態的CURL連接句柄銷毀。
3.4 內存管理方案的兼容問題
ADB PG基于PostgreSQL內核打造,也繼承了PostgreSQL的內存管理機制。PostgreSQL的內存管理采用了進程安全的內存上下文MemoryContext,而OSS C SDK是線程安全的內存上下文APR Pool。在MemoryContext內存環境下,每個已經分配的內存,都可以顯式地調用free釋放,由MemoryContext進行內存碎片的整理,但在APR Pool中,我們只看到內存池的創建、內存的申請和內存池的銷毀等操作,卻沒有內存的顯式釋放接口。
這種情況意味著,我們需要對于OSS C SDK接口所持有的內存的生命周期有明確的了解,否則極易出現內存泄漏和訪問已經釋放的內存等問題。通常我們會按照如下兩種方式申請APR Pool的內存。
方式一適用于重入低頻的操作接口,如獲取OSS文件清單列表。
方式二適用于多次重入的操作接口,如周期性向OSS請求指定文件指定范圍的數據。
通過這種方法,可以很好地解決ADB PG與OSS C SDK在內存管理方面的不兼容問題。

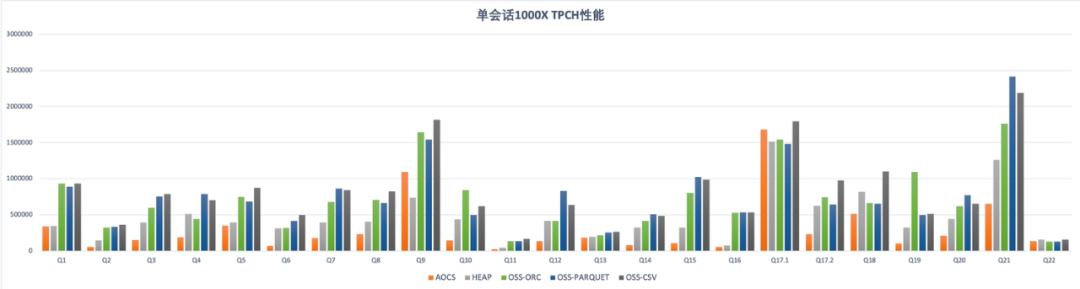
下圖是TPCH 22條查詢的詳細時間。本地表與外表的性能差距在不同的查詢上差距有所不同。考慮到外表在存儲成本、靈活性、擴展能力方面的優勢,ADB PG外表分析在應用場景的潛力是巨大的。
看完了這篇文章,相信你對“怎么通過postgresql數據倉庫實現湖倉一體數據分析”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





