溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何排查zuul版本升級產生的問題”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
事情的起因是由于早期的一些服務版本放到現在太低了,基本上都是SpringBoot1.5.x,因此準備統一對服務進行一次版本升級,升級到2.1.x,SpringCloud``版本升級到Greenwich。當然我們用的舊版本的zuul相關的都需要升級。
我們網關使用的是zuul,使用的是spring-cloud-netflix封裝的包,此次版本升級同步升級了相關的包。但是意外的情況發生了,在測試環境上我們發現上傳文件會出現異常。具體表現是這樣的:當上傳的文件超出一定大小后,在經過zuul網關并向其他服務轉發的時候,之前上傳的包就不見了。這個情況十分奇怪,因此馬上開始排查。
出現這樣的問題,第一反應是測試是不是根本沒有上傳包所以當然包沒法轉發到下一層,當然這種想法很快被否定了。好吧,那就認真的排查吧。
首先先去追蹤了一下路由以及出現的具體日志,將問題定位到zuul服務,排除了上游nginx和下游業務服務出現問題的可能。但是zuul服務沒有任何異常日志出現,所以非常困擾。檢查過后發現文件確實有通過zuul,但是之后憑空消失沒有留下一點痕跡。
明明當初考慮上傳文件的問題給zuul分配了兩個g的內存,怎么上傳500m的文件就出問題了呢?不對!此時我靈光一閃,會不會和垃圾回收機制有關。我們的文件是非常大的,這樣的大文件生成的大對象是會保存在java的堆上的,并且由于垃圾回收的機制,這樣的對象不會經歷年輕代,會直接分配到老年代,會不會是由于我們內存參數設置不合理導致老年代太小而放不下呢?想到做到,我們通過調整jvm參數,保證了老年代至少有一個G的空間,并且同步檢測了java的堆內存的狀態。然而讓人失望的是居然沒有奏效。不過此時事情和開始不同,我們有了線索。在剛才的堆的內存監控中發現了一些異常,隨即合理懷疑是堆中內存不夠導致了oom。隨后加大內存嘗試并且再次運行,發現居然上傳成功了。果然是老年代內存不足導致的oom,不過雖然上傳成功,但是老年代中的內存居然被占用了1.6G左右,明明是500M的文件,為什么會占用了這么大的內存呢?
雖然找到了原因,但是增加內存顯然不是解決問題的方法,因此,我們在啟動參數上新增了-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data準備查看oom的具體分析日志。
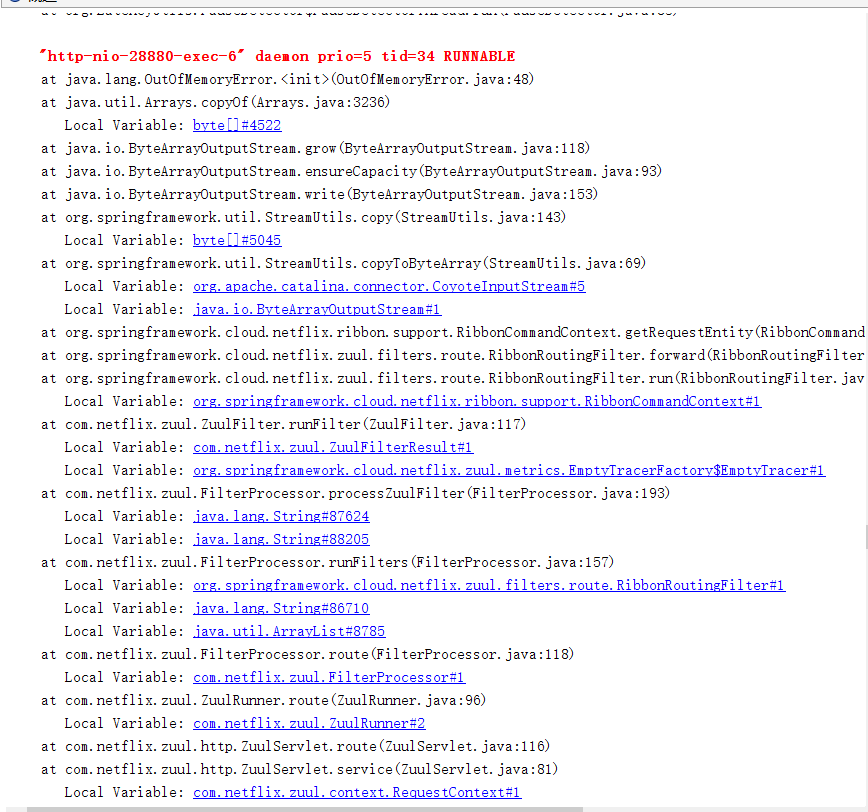
查看堆棧信息可以發現,溢出是發生在byte數組的拷貝上,我們迅速定位代碼,可以找到如下的代碼:
public InputStream getRequestEntity() {
if (requestEntity == null) {
return null;
}
if (!retryable) {
return requestEntity;
}
try {
if (!(requestEntity instanceof ResettableServletInputStreamWrapper)) {
requestEntity = new ResettableServletInputStreamWrapper(
StreamUtils.copyToByteArray(requestEntity));
}
requestEntity.reset();
}
finally {
return requestEntity;
}
}這段代碼源自RibbonCommandContext是在zuul中進行請求轉發的時候調用到的,具體的OOM是發生在調用StreamUtils.copyToByteArray(requestEntity));的時候。繼續進入方法查找源頭。最終經過排查找到了溢出的源頭。ribbon轉發中的用到了ByteArrayOutputStream的拷貝,代碼如下:
public synchronized void write(byte b[], int off, int len) {
if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) - b.length > 0)) {
throw new IndexOutOfBoundsException();
}
ensureCapacity(count + len);
System.arraycopy(b, off, buf, count, len);
count += len;
}可以看到這邊有一個ensureCapacity,查看源碼:
private void ensureCapacity(int minCapacity) {
// overflow-conscious code
if (minCapacity - buf.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = buf.length;
int newCapacity = oldCapacity << 1;
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
buf = Arrays.copyOf(buf, newCapacity);
}可以看到ensureCapacity做了一件事,就是當流拷貝的時候byte數組的大小不夠了,那就調用grow進行擴容,而grow的擴容和ArrayList不同,他的擴容是每一次將數組擴大兩倍。
至此溢出的原因就很清楚了,500m文件占用1.6g是因為剛好觸發擴容,導致用了多一倍的空間來容納拷貝的文件,再加上源文件,所以占用了文件的3倍空間。
至于解決方案,調整內存占用或者是老年代的占比顯然不是合理的解決方案。我們再回頭查看源代碼,可以看到這個部分
if (!retryable) {
return requestEntity;
}如果設置的不重試的話,那么body中的信息就不會被保存。所以,我們決定臨時先去除上傳文件涉及到的服務的重試,之后再修改上傳機制,在以后的上傳文件時繞過zuul。
雖然找到的原因,并且也有了解決方案,但是我們仍然不知道為什么舊版本是ok的,因此本著追根究底的態度,找到了舊版的zuul的源碼。
新版的ribbon代碼集成spring-cloud-netflix-ribbon,而舊版的ribbon的代碼集成在spring-cloud-netflix-core中,所以稍稍花費點時間才找到對應的代碼,檢查不同,發現舊版的getRequestEntity沒有任何的處理,直接返回了requestEntity
public InputStream getRequestEntity() {
return requestEntity;
}而在之后的版本中馬上就加上了拷貝機制。于是我們去github上找到了當初的那個commit
之后我們順著commit中給出的信息找到了最初的issue
查看過issue之后發現這原來是舊版的一個bug,這個bug會導致舊版的post請求在retry的時候有body丟失的情況,因此在新版本中進行了修復,當請求為post的時候會對于body進行緩存以便于重試。
“如何排查zuul版本升級產生的問題”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





