溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么理解垃圾收集器”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么理解垃圾收集器”吧!
如果說垃圾收集算法是內存回收的理論,那么垃圾收集器就是內存回收的具體實現。
垃圾收集器目前存在的有很多,但是依舊沒有哪個收集器是萬能的存在,我們只能選擇一個最適合應用的收集器。
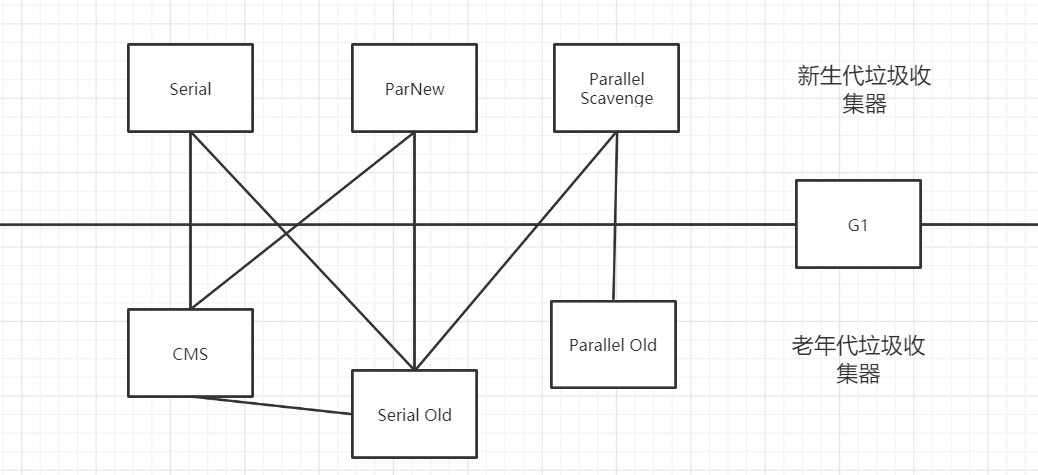
下面會介紹目前主流Java虛擬機中所采用的七種垃圾收集器: Serial、parNew、ParallelScavenge、SerialOld、ParallelOld、CMS、G1 上述垃圾收集器有些適用于新生代,有些適用于老年代,有些在新生代和老年代都適應。如下圖所示,連線表示可以配合使用。
Serial是一個單線程的收集器,Serial的特點是它在進行垃圾收集時,必須“Stop the World”,意思就是當這個垃圾收集器開始工作時,必須停止其他所有的工作線程。聽起來似乎很不靠譜,但是對于限定單個CPU的場景下,這種方式簡單而高效。對于簡單的桌面應用,分配給虛擬機的內存不會很大,對于一兩百兆的新生代,Serial的垃圾收集時間可以控制在一百毫秒以內,對于用戶來說基本上是無影響的。
Serial收集器在新生代使用復制算法。
ParNew垃圾收集器是Serial的多線程版本,使用多條線程進行垃圾收集。除此之外,和Serial基本相同,ParNew在多線程收集垃圾時依舊需要**“Stop the World”**。ParNew可以使用-XX:ParallelGCThreads參數來限制垃圾收集的線程數量。
ParNew收集器在新生代使用復制算法
Parallel Scavenge也是新生代收集器,也同樣是多線程的收集器,但是和ParNew不同,Parallel Scavenge收集器關注的是一個可控制的吞吐量(Throughput)。所謂吞吐量指的是CPU用于運行代碼的時間和CPU總消耗的時間比例。
吞吐量=運行代碼的時間 /(運行代碼的時間+垃圾收集時間)
理論上吞吐量越高,用戶就越不能感受到停頓時間。
Parallel Scavenge提供了兩個參數用來控制吞吐量: -XX:MaxGCPauseMillis和**-XX:GCTimeRatio**
-XX:MaxGCPauseMillis設置內存回收花費時間最高毫秒值,但是不要一味地認為只要把值設置很小,垃圾回收就更快了。這個停頓時間是以犧牲吞吐量和新生代空間換來的。
-XX:GCTimeRatio表示垃圾收集時間占總時間的比例,(1~100),也就是吞吐量的倒數。默認這個值是99,就是允許最大百分之1的垃圾手機時間(1/(1+99))。
還有一個參數**-XX:+UseAdaptiveSizePolicy**,打開這個參數后,就不需要自己設置新生代大小、晉升老年代對象年齡等參數,因此Parallel Scavenge收集器也被叫做吞吐量優先垃圾收集器。
Parallel Scavenge采用復制算法。
一聽名字就知道這是Serial收集器的老年代版本,是單線程收集器,采用標記-整理算法,其余的和新Serial基本相同。
Parallel Scavenge收集器的老年版本,多線程收集器,采用標記-整理算法,也是吞吐量優先。
CMS(Concurrent Mark Sweep)收集器是一種以獲取最短回收停頓時間為目標的收集器。CMS是基于標記-清除算法的老年代垃圾回收器,CMS是目前應用最廣泛的老年代垃圾回收器,它進行垃圾回收分為以下四步:
1、初始標記:標記GC Roots可以直接關聯到的對象,速度很快(stop the world)
2、并發標記:根搜索算法的過程
3、重新標記:為了修正并發標記期間,因程序運行導致標記產生變動的對象。(stop the world)
4、并發清除:清除垃圾
這個過程中耗時最長的是并發標記和并發清除的過程,但是并不會stop the world,而初始標識和重新標記的速度都很快,即使stop the world也不會占用太多時間。
它的優點就是并發收集、并發清除、低停頓。
但是它有三個顯著的缺點:
1、對CPU資源十分敏感,因為并發標記和并發清除都是和程序同時運行,因此會占用CPU導致應用程序變慢。
2、無法處理浮動垃圾,浮動垃圾就是在并發清除過程中新生成的垃圾,這部分垃圾CMS無法在本次被清理,可能出現Concurrent Mode Failed報錯,因此需要預留一定的內存空間,無法等到老年代快被占滿時再清除。默認情況下,CMS在老年代使用了68%后就會被激活。可以設置-XX:CMSInitiatingOccupancyFraction設置這個值。
3、產生空間碎片,由于采用的是標記-清除算法,那就無法避免會產生空間碎片的問題,這會給分配大對象帶來困難。
上面的垃圾回收器基本上都是按新生代和老年代去區分,但是G1不一樣
堆結構
G1的堆結構就是把一整塊內存區域劃分為多個固定大小的塊,JVM一般把堆劃分為2000個region,然后每個region從1M到32M不等。
內存的分配
所有的region會被劃分為Eden、Survivor、Old和Humongous,其中對Eden、Survivor和Old的理解用其他垃圾回收器去理解,這里多了一種類型Humongous,這個類型主要用來存儲比標準塊大百分之50或者更大的對象。
G1中的YGC
第一次YGC時,Eden塊中存活的對象會被轉移到一個或多個survivor塊中,存活時間達到閾值,這些對象就會晉升到老年代。年輕代 GC 通過多線程并行進行。
此時會有一次 stop the world暫停,會計算出 Eden大小和 survivor 大小,用于下次young GC。統計信息會被保存下來,用于輔助計算size。比如暫停時間之類的指標也會納入考慮。
一旦發生一次新生代回收,整個新生代都會被回收(根據對暫停時間的預測值,新生代的大小可能會動態改變)
G1中的老年代垃圾收集
老年代回收不會回收全部老年代空間,只會選擇一部分收益最高的 Region,回收時一般會搭便車——把待回收的老年代 Region 和所有的新生代 Region 放在一起進行回收,這個過程一般被稱為 Mixed GC
G1中的老年代垃圾收集和CMS收集器很相似
1、初始標記:附加在正常的YGC過程中,標記所有的根。(stop the world)
2、掃描根區域:掃描Survivor Regions中指向老年代的被初始標記標記的引用及引用的對象,這個階段是并發執行的,但是在年輕代GC發生之前必須完成。(stop the world)
3、并發標記:在整個堆中查找活著的元素,此階段可被YGC打斷
4、再次標記:類似CMS的重新標記,處理并發標記階段產生的新的對象引用,這階段使用了SATB(snapshot-at-the-beginning)算法,該算法比CMS中所采用的快很多。(stop the world)
5、清理階段:G1 GC 會識別完全空閑的區域和可供進行混合垃圾回收的區域進行清理。(stop the world)
你可以發現,有四個階段都需要stop the world,為了降低stop the world的時間,G1使用了RSet(Remembered Set)來記錄不同代之間的引用關系。
RSet
RSet記錄了“誰引用了我”,RSet記錄了以下兩種引用:
1、老年代 Region 間的引用
2、老年代 Region 到新生代 Region 的引用,Young GC 時直接將這種引用加入 GC Roots。
RSet的工作原理是這樣的,進行 Young GC 時,選擇新生代所在的 Region 作為 GC Roots,這些 Region 中的 RSet 記錄了老年代->新生代的的跨代引用(「誰引用了我」),從而可以避免了掃描整個老年代。進行 Mixed GC 時,「老年代->老年代」之間的引用,可以通過待回收 Region 中的 RSet 記錄獲得,「新生代->老年代」之間的引用通過掃描全部的新生代獲得(前面提到過 Mixed GC 會搭 Young GC 的便車),也不需要掃描全部老年代。總之,引入 RSet 后,GC 的堆掃描范圍大大減少了。
感謝各位的閱讀,以上就是“怎么理解垃圾收集器”的內容了,經過本文的學習后,相信大家對怎么理解垃圾收集器這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





