溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“nginx負載均衡詳解”,在日常操作中,相信很多人在nginx負載均衡詳解問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”nginx負載均衡詳解”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
上面簡短的定義中我們大致可以看到兩個內容:將請求分發,操作單元;其實就是控制器+執行器模式、Master+Worker模式等等,是不是很熟悉;當然一個成熟的負載均衡器不光有這兩個核心功能,還有一些其他的功能,下面看看都有哪些核心功能:
操作單元配置 這里的操作單元其實就是上游的服務器,是真正來處理業務的執行者,這個需要可配置的(最好能支持動態配置),方便用戶添加和刪除操作單元;這些操作單元就是負載均衡器分發消息的對象;
負載均衡算法 既然需要分發,那具體通過何種方式把消息分給配置的執行器,這就需要有相關的分發算法了,比如我們常見的輪詢、隨機、一致性哈希等等;
失敗重試 既然配置了多個執行單元,所以某臺服務器宕機是大概率事件,這樣我們在分發請求給某臺已經宕機的服務器時,需要有失敗重試功能,將請求重新分發給正常的執行器;
健康檢查 上面的失敗重試是只有真正轉發的時候才知道服務器宕機了,是一種惰性策略,健康檢查就是提前將宕機的機器排除掉,比如常見的通過心跳的方式去檢查執行器是否還存活;
有了以上幾個核心的功能,一個負載均衡器大致就形成了,可以把這幾個原則用在很多地方,形成不同的中間件或者說內嵌在各種中間件中,比如接入層的LVS,F5,Nginx等,服務層各種RPC框架,消息隊列RocketMQ、Kafka,分布式緩存Redis、memcached,數據庫中間件shardingsphere、mycat等等,這種分而治之的思路在各種中間件中廣泛使用,下面對一些常見的中間件是如何做負載均衡的進行分析,大體上可以分為有狀態和無狀態兩種類型;
執行單元本身沒有狀態,其實是更加容易去做負載均衡,每個執行單元都是一樣的,常見的無狀態的中間件有Nginx,RPC框架,分布式調度等;
Nginx可以說是我們最常見的接入層中間件了,提供四層到七層的負載均衡功能,提供了高性能的轉發,對以上的幾個核心功能提供了支持;
操作單元配置 Nginx提供了簡單的靜態的操作單元配置,如下:
upstream tomcatTest {
server 127.0.0.1:8081; #tomcat-8081
server 127.0.0.1:8082; #tomcat-8082
}
location / {
proxy_pass http://tomcatTest;
}以上配置是靜態的,如果需要添加或者刪除,需要對Nginx重啟,很不方便,當然也提供了動態的單元配置,需要借助第三方的服務注冊中心比如Consul,etcd等;原理大致如下:
操作單元啟動就會注冊到Consul中,同樣宕機會從Consul中移除;Nginx側會啟動一個Consul-template監聽程序,監聽Consul上操作單元的變更,然后更新Nginx的upstream,最好重加載upstream;
負載均衡算法 常見的比如:ip_hash,round-robin,hash;配置也很簡單:
upstream tomcatTest {
ip_hash //根據ip負載均衡,也就是常說的ip綁定
server 127.0.0.1:8081; #tomcat-8081
server 127.0.0.1:8082; #tomcat-8082
}失敗重試
upstream tomcatTest {
server 127.0.0.1:8081 max_fails=2 fail_timeout=20s;
}
location / {
proxy_pass http://tomcatTest;
proxy_next_upstream error timeout http_500;
}當在fail_timeout內出現了max_fails次失敗,表示此執行單元不可用;通過proxy_next_upstream配置,當出現配置的錯誤時,會重試下一臺執行單元;
健康檢查 Nginx通過集成nginx_upstream_check_module模塊來進行健康檢查;支持TCP心跳和Http心跳檢測;
upstream tomcatTest {
server 127.0.0.1:8081;
check interval=3000 rise=2 fall=5 timeout=5000 type=tcp;
}interval:檢測間隔時間; rise:檢測成功多少次后,操作單元標識為可用; fall:檢測失敗多少次后,操作單元標識為不可用; timeout:檢測請求超時時間; type:檢測類型包括tcp,http;
服務層主要的就是微服務框架比如Dubbo,Spring Cloud等,內部都集成了負載均衡策略,使用起來也是非常方便;
操作單元配置 RPC框架一般都依賴注冊中心組件,其實和Nginx通過注冊中心來動態改變操作單元是一樣的,RPC框架默認就已經依賴注冊中心了,服務啟動就注冊到中心,服務不可用就移除,并且會自動同步到消費端,用戶完全無感知,消費端要做的就是根據注冊中心提供的服務列表,然后使用分發算法進行負載均衡;
負載均衡算法 Spring Cloud提供了Ribbon組件來實現負載均衡,而Dubbo直接內置均衡策略,常見的算法包括:輪詢,隨機,最少活躍調用數,一致性 Hash等等;比如dubbo配置輪詢算法:
<dubbo:reference interface="" loadbalance="roundrobin" />
Ribbon配置隨機規則:
@Bean
public IRule loadBalancer(){
return new RandomRule();
}失敗重試 對于RPC框架來說其實就是容錯機制,比如Dubbo內置了多種容錯機制包括:Failover、Failfast、Failsafe、Failback、Forking、Broadcast;默認的容錯機制就是Failover失敗自動切換,當出現失敗重試其它服務器;配置容錯機制也很簡單:
<dubbo:reference cluster="failback" retries="2"/>
健康檢查 注冊中心一般都有健康檢查功能,會實時檢測服務器是否可用,如果不可用會移除,同時將更新推送給消費端;對用戶來說完全無感知;
分布式調度將調度器和執行器分離,執行器也是通過注冊中心的方式提供給調度器,然后由調度器進行負載均衡操作,流程已基本相似,此處不再一一介紹; 可以發現無狀態的負載均衡其實更多情況以來注冊中心,通過注冊中心來動態的增減執行單元,從而很方便的達到擴容縮容;
有狀態的執行單元相對于無狀態來說更加有難度,因為每個節點的狀態是整個系統的一部分,不是能隨意增減的節點的;常見的有狀態中間件有:消息隊列,分布式緩存,數據庫中間件等;
現在高吞吐量,高性能的消息隊列越來越成為主流,比如RocketMQ,Kafka等,有強大的水平擴展能力;RocketMQ中引入Message Queue機制,Kafka引入分區(Partition),一個Topic對應多個分區,采用分而治之的思路來提高吞吐量,性能;可以看一個RocketMQ的簡易圖: 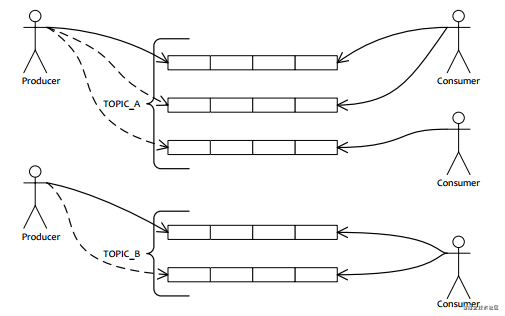
操作單元配置 消息隊列里面的操作單元其實就是這里的分區或者說Message Queue,比如RocketMQ是可以動態去修改讀寫隊列的數量;RocketMQ還提供了rocketmq-console控制臺,可以直接修改;
負載均衡算法 消息隊列一般都有生產端和消費端,生產端默認是輪流給每個Message Queue發送消息,當然也可以自定義發送策略可以通過MessageQueueSelector來實現;消費端分配策略包括:分頁模式(隨機分配模式)、手動配置模式、指定機房模式、就近機房模式、統一哈希模式、環型模式;
失敗重試 對于有狀態的執行單元來說,不是說宕機就可以直接移除的,需要保證數據的完整性,正常來說一般都會做主備處理,主機掛了備機接管;以RocketMQ為例,每個分區都有各自的備份,RocketMQ采取的策略是,備區僅僅是做數據的完整性保證,消費者能消息備區的數據,但是并不會重新來接收數據;
健康檢查 消息隊列也有一個核心組件,可以理解為協調者,或者可以理解為注冊中心,Kafka使用zookeeper,RocketMQ使用NameServer,里面其實就是保存了相關的對應信息比如Topic對應Message Queue,如果發現某臺broker不可用,會將信息告知生產者,方式和注冊中心類似;
常見的分布式緩存有redis、memcached,為了能夠容納更多的數據一般都會做分片處理,分片的方式也是多種多樣,就拿redis來說可以客戶端做分片,基于代理的分片,還有官方提供的Cluster方案;
操作單元配置 緩存雖然也有有狀態的,但是有其特殊性,其更多關注的是命中率,其實是可以容忍數據丟失的,比如基于代理的分片中間件codis,對客戶端全透明不影響服務的情況下可以完成增減redis實例;
負載均衡算法 基于保證命中率的前提下,基于代理分片的方式一般都會采用一致性哈希算法;而redis官方提供的Cluster方案,因為其內置有16384個虛擬槽,所以直接使用取模即完成分片;
失敗重試 有狀態的分片一般都有會備區,在主區宕機后,備區接管實現故障遷移,比如redis的哨兵模式,或者codis這種中間件內置的功能;也無需去切換其他分區,對用戶來說這種接管完全是無感知的;
健康檢查 以redis為例,哨兵模式中,sentinel通過心跳的方式實時監測節點,通過客觀下線來實施故障遷移;可以發現健康檢查基本都是通過心跳來檢測的方式;
數據庫層做均衡處理應該說是最復雜的,首先是有狀態的,其次是數據的安全性至關重要,常見的數據庫中間件包括:mycat,shardingjdbc等;
操作單元配置 以分表為例,這里的操作單元其實就是一個個分片數據表,數據量有時候往往出乎我們的預料,一般很少說固定給它分配多少個分片,最好是通過負載算法自動生成數據表,而且最好事先就評估好某種負載算法,不然后期如果想改變是很難的;
負載均衡算法 以mycat為例提供了多種負載算法:范圍約定,取模,按日期分片,hash,一致性hash,分片枚舉等等;比如下面的按天分區配置:
<tableRule name="sharding-by-date"> <rule> <columns>create_time</columns> <algorithm>sharding-by-date</algorithm> </rule> </tableRule> <function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate"> <property name="dateFormat">yyyy-MM-dd</property> <property name="sBeginDate">2021-01-01</property> <property name="sEndDate">2051-01-01</property> <property name="sPartionDay">10</property> </function>
指定了開始時間,結束時間,以及分區的天數;因為數據是隨時間連續的,所以這種方式擴展性是很好的;如果是取模的方式就要考慮清楚分片的數量了,后面如果想改變分片數量就很麻煩了,不像緩存可以使用一致性hash來保證命中率就行了;
失敗重試 有狀態的節點,備庫是少不了的,比如mycat提供了故障的主從切換功能,主宕機切換到從,基本都是這個套路,數據是不能丟的;
健康檢查 同樣的主動檢測也必不可少,一般也是基于心跳語句去定時檢測,然后做故障主從切換;
到此,關于“nginx負載均衡詳解”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





