溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Spark分區并行度決定機制”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Spark分區并行度決定機制”吧!
大家都知道Spark job中最小執行單位為task,合理設置Spark job每個stage的task數是決定性能好壞的重要因素之一,但是Spark自己確定最佳并行度的能力有限,這就要求我們在了解其中內在機制的前提下,去各種測試、計算等來最終確定最佳參數配比。
對于通過SparkContext的parallelize方法或者makeRDD生成的RDD分區數可以直接在方法中指定,如果未指定,則參考spark.default.parallelism的參數配置。下面是默認情況下確定defaultParallelism的源碼:
override def defaultParallelism(): Int = {
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
}
通常,RDD的分區數與其所依賴的RDD的分區數相同,除非shuffle。但有幾個特殊的算子:
1.coalesce和repartition算子
筆者先放兩張關于該coalesce算子分別在RDD和DataSet中的源碼圖:(DataSet是Spark SQL中的分布式數據集,后邊說到Spark時再細講)
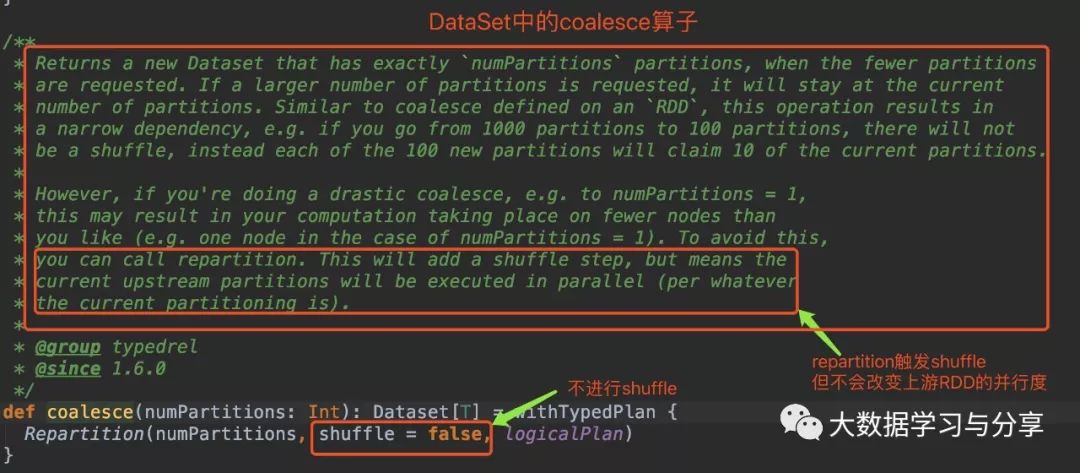
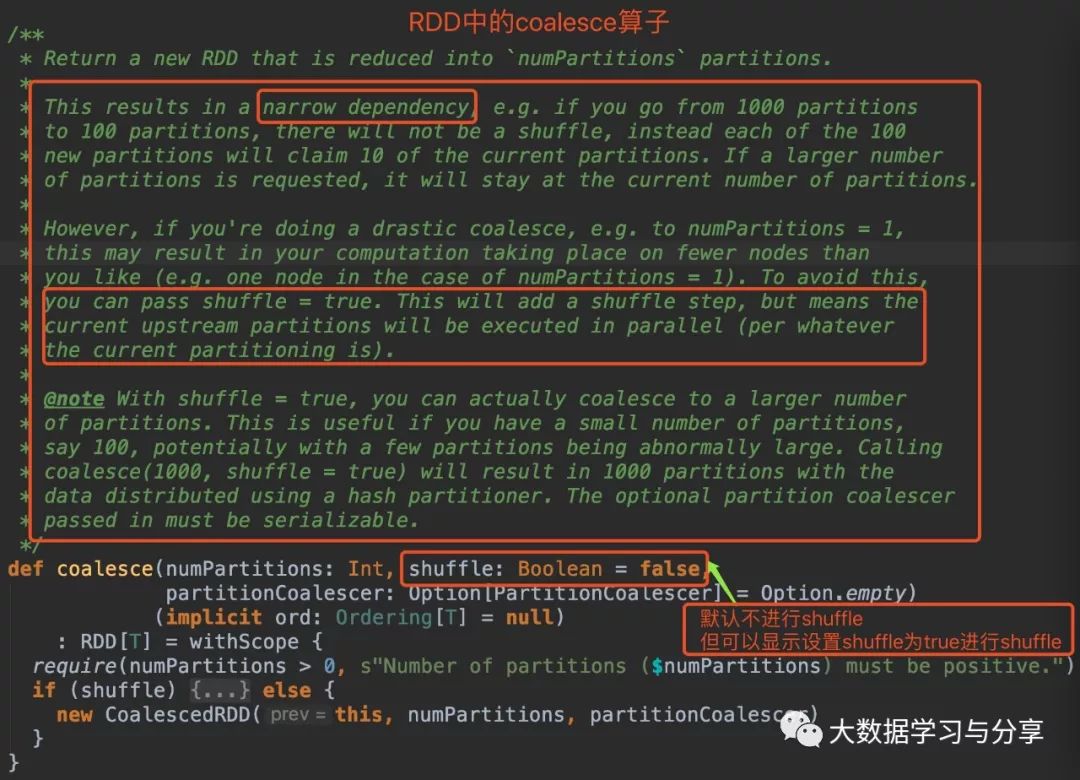
通過coalesce源碼分析,無論是在RDD中還是DataSet,默認情況下coalesce不會產生shuffle,此時通過coalesce創建的RDD分區數小于等于父RDD的分區數。
筆者這里就不放repartition算子的源碼了,分析起來也比較簡單,圖中我有所提示。但筆者建議,如下兩種情況,請使用repartition算子:
coalesce默認不觸發shuffle,即使調用該算子增加分區數,實際情況是分區數仍然是當前的分區數。
2.union算子
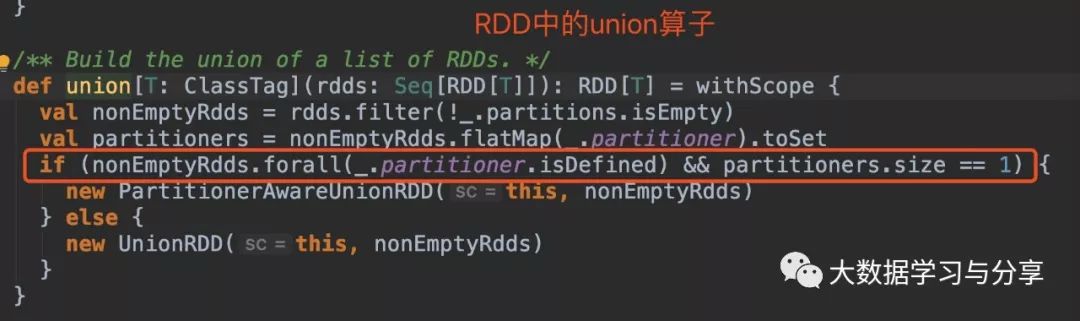
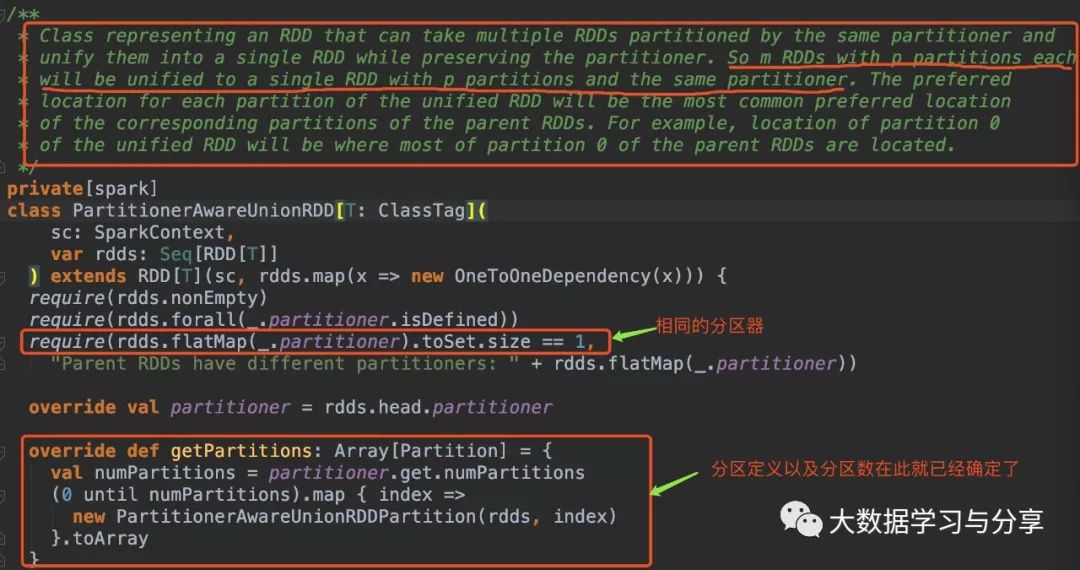

多個父RDD具有相同的分區器,union后產生的RDD的分區器與父RDD相同且分區數也相同。比如,n個RDD的分區器相同且是defined,分區數是m個。那么這n個RDD最終union生成的一個RDD的分區數仍是m,分區器也是相同的
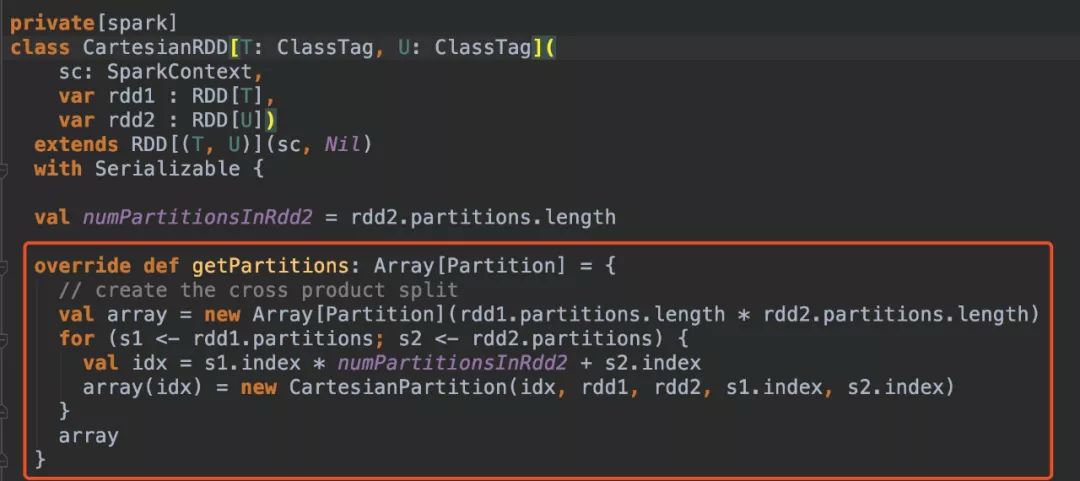
通過上述coalesce、repartition、union算子介紹和源碼分析,很容易分析cartesian算子的源碼。通過cartesian得到RDD分區數是其父RDD分區數的乘積。
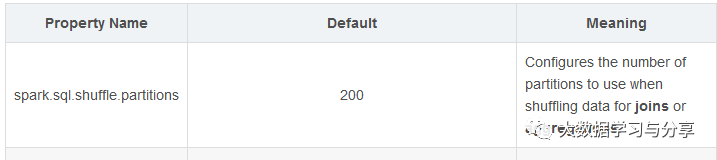
在Spark SQL中,任務并行度參數則要參考spark.sql.shuffle.partitions,筆者這里先放一張圖,詳細的后面講到Spark SQL時再細說:
看下圖在Spark流式計算中,通常將SparkStreaming和Kafka整合,這里又分兩種情況:
1.Receiver方式生成的微批RDD即BlockRDD,分區數就是block數
到此,相信大家對“Spark分區并行度決定機制”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





