溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
關于YOLO v3原理的實例分析,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
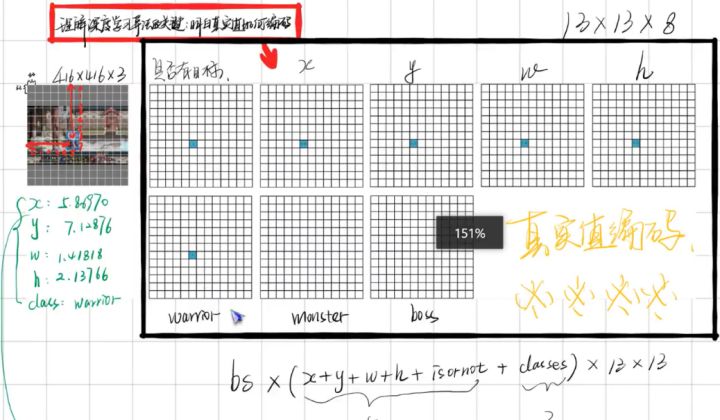
首先通過特征提取網絡對輸入特征提取特征,得到特定大小的特征圖輸出。輸入圖像分成13×13的grid cell,接著如果真實框中某個object的中心坐標落在某個grid cell中,那么就由該grid cell來預測該object。每個object有固定數量的bounding box,YOLO v3中有三個bounding box,使用邏輯回歸確定用來預測的回歸框。
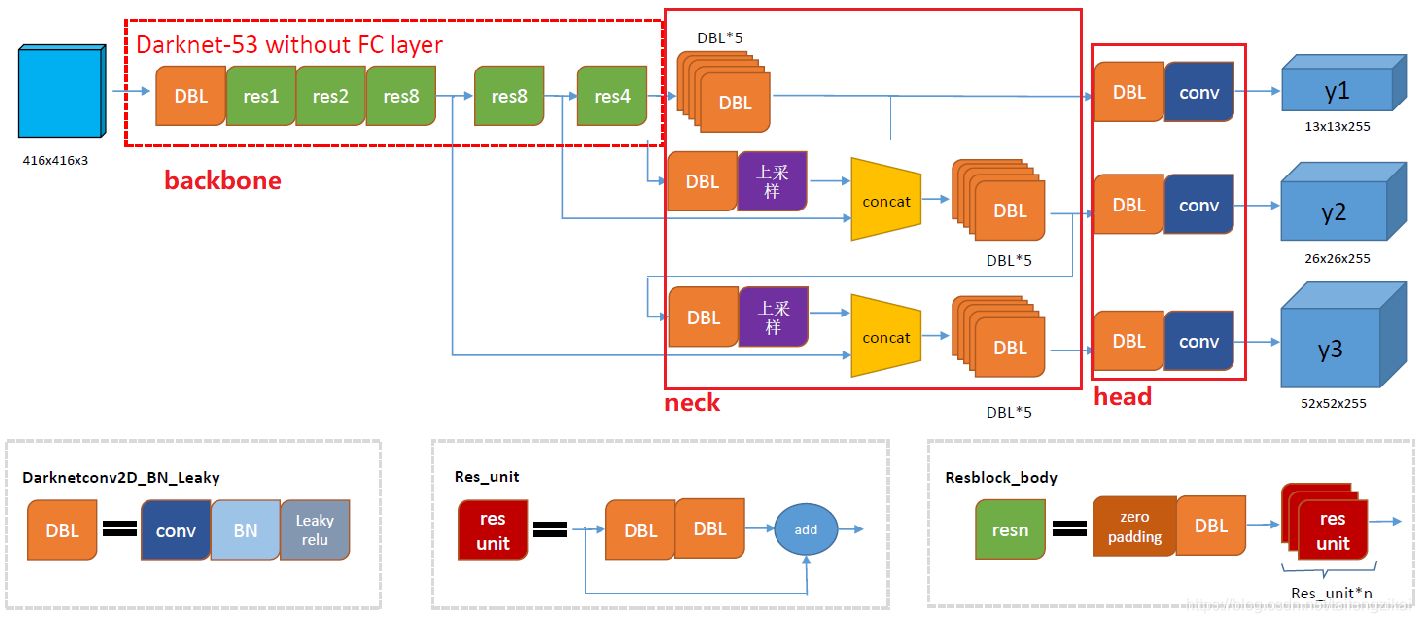
上圖DBL是Yolo v3的基本組件。Darknet的卷積層后接BatchNormalization(BN)和LeakyReLU。除最后一層卷積層外,在yolo v3中BN和LeakyReLU已經是卷積層不可分離的部分了,共同構成了最小組件。
主干網絡中使用了5個resn結構。n代表數字,有res1,res2, … ,res8等等,表示這個res_block里含有n個res_unit,這是Yolo v3的大組件。從Yolo v3開始借鑒了ResNet的殘差結構,使用這種結構可以讓網絡結構更深。對于res_block的解釋,可以在上圖網絡結果的右下角直觀看到,其基本組件也是DBL。
在預測支路上有張量拼接(concat)操作。其實現方法是將darknet中間層和中間層后某一層的上采樣進行拼接。值得注意的是,張量拼接和Res_unit結構的add的操作是不一樣的,張量拼接會擴充張量的維度,而add只是直接相加不會導致張量維度的改變。
Yolo_body一共有252層。23個Res_unit對應23個add層。BN層和LeakyReLU層數量都是72層,在網絡結構中的表現為:每一層BN后面都會接一層LeakyReLU。上采樣和張量拼接操作各2個,5個零填充對應5個res_block。卷積層一共有75層,其中有72層后面都會接BatchNormalization和LeakyReLU構成的DBL。三個不同尺度的輸出對應三個卷積層,最后的卷積層的卷積核個數是255,針對COCO數據集的80類:3×(80+4+1)=255,3表示一個grid cell包含3個bounding box,4表示框的4個坐標信息,1表示置信度。
下圖為具體網絡結果圖。
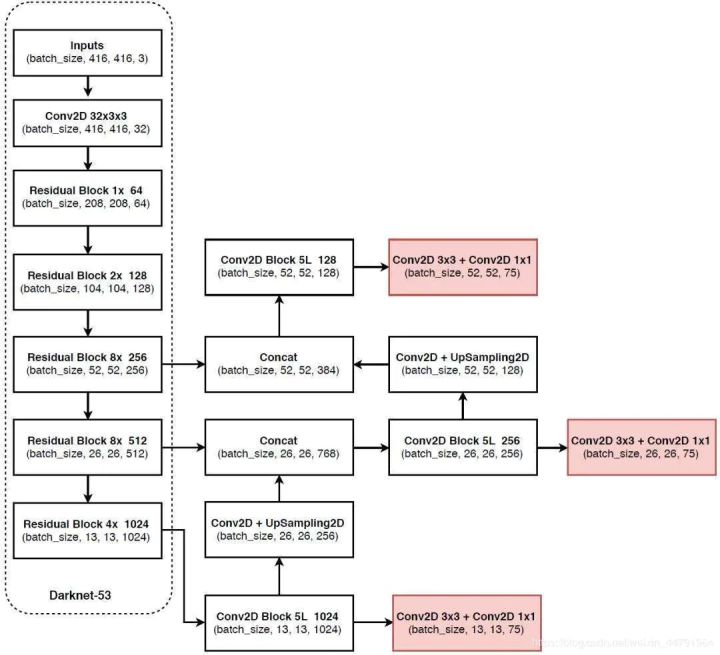
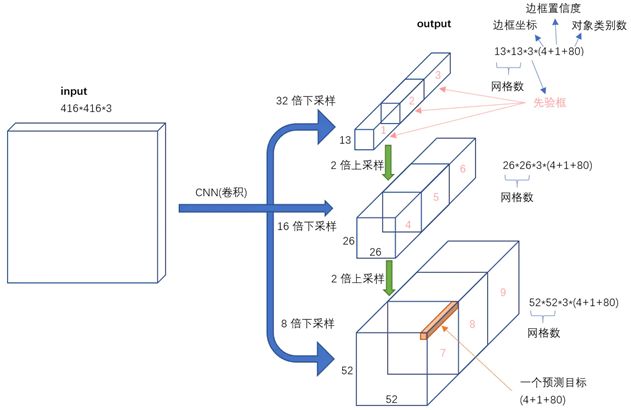
不考慮神經網絡結構細節的話,總的來說,對于一個輸入圖像,YOLO3將其映射到3個尺度的輸出張量,代表圖像各個位置存在各種對象的概率。
我們看一下YOLO3共進行了多少個預測。對于一個416*416的輸入圖像,在每個尺度的特征圖的每個網格設置3個先驗框,總共有 13*13*3 + 26*26*3 + 52*52*3 = 10647 個預測。每一個預測是一個(4+1+80)=85維向量,這個85維向量包含邊框坐標(4個數值),邊框置信度(1個數值),對象類別的概率(對于COCO數據集,有80種對象)。
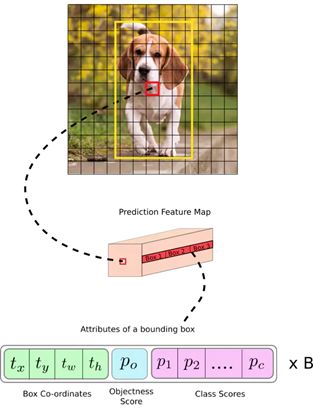
Yolo v3關于bounding box的初始尺寸還是采用Yolo v2中的k-means聚類的方式來做,這種先驗知識對于bounding box的初始化幫助還是很大的,畢竟過多的bounding box雖然對于效果來說有保障,但是對于算法速度影響還是比較大的。
在COCO數據集上,9個聚類如下表所示,注這里需要說明:特征圖越大,感受野越小。對小目標越敏感,所以選用小的anchor box。特征圖越小,感受野越大。對大目標越敏感,所以選用大的anchor box。

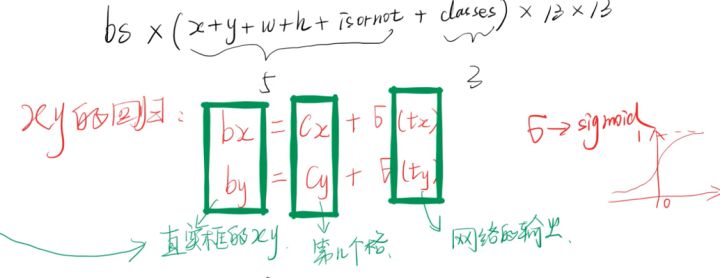
Yolo v3采用直接預測相對位置的方法。預測出b-box中心點相對于網格單元左上角的相對坐標。直接預測出(tx,ty,tw,th,t0),然后通過以下坐標偏移公式計算得到b-box的位置大小和confidence。
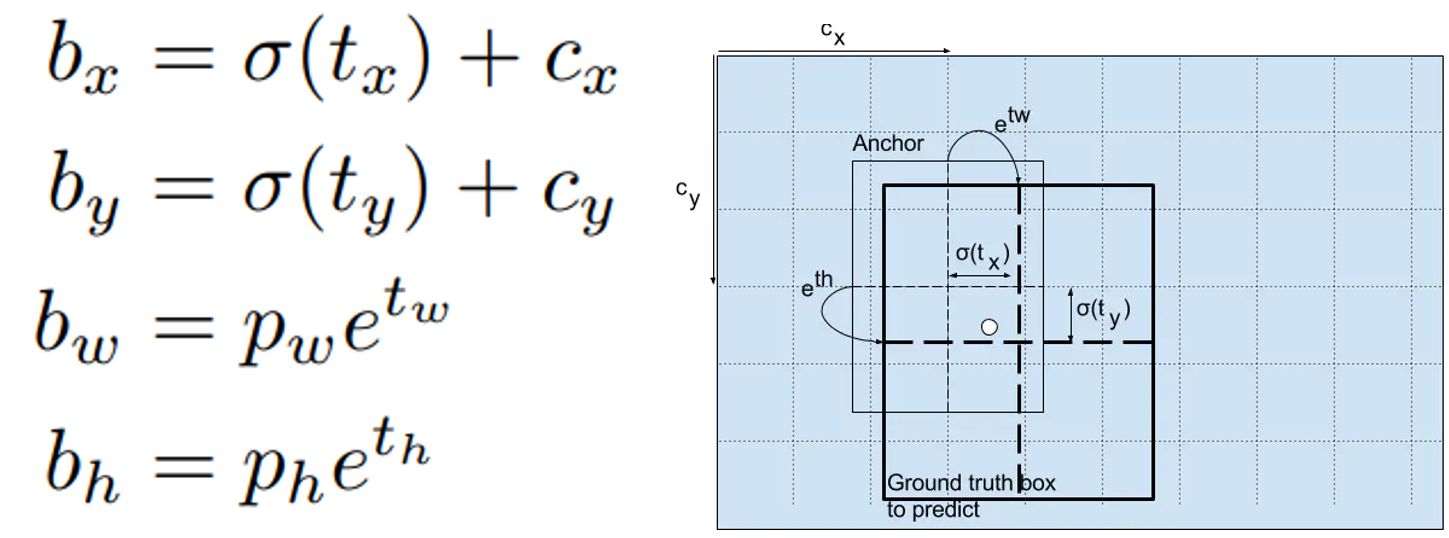
tx、ty、tw、th就是模型的預測輸出。cx和cy表示grid cell的坐標,比如某層的feature map大小是13×13,那么grid cell就有13×13個,第0行第1列的grid cell的坐標cx就是0,cy就是1。pw和ph表示預測前bounding box的size。bx、by、bw和bh就是預測得到的bounding box的中心的坐標和size。在訓練這幾個坐標值的時候采用了sum of squared error loss(平方和距離誤差損失),因為這種方式的誤差可以很快的計算出來。
注:這里confidence = Pr(Object)*IoU 表示框中含有object的置信度和這個box預測的有多準。也就是說,如果這個框對應的是背景,那么這個值應該是 0,如果這個框對應的是前景,那么這個值應該是與對應前景 GT的IoU。
Yolo v3使用邏輯回歸預測每個邊界框的分數。如果邊界框與真實框的重疊度比之前的任何其他邊界框都要好,則該值應該為1。如果邊界框不是最好的,但確實與真實對象的重疊超過某個閾值(Yolo v3中這里設定的閾值是0.5),那么就忽略這次預測。Yolo v3只為每個真實對象分配一個邊界框,如果邊界框與真實對象不吻合,則不會產生坐標或類別預測損失,只會產生物體預測損失。
在上面網絡結構圖中可以看出,Yolo v3設定的是每個網格單元預測3個box,所以每個box需要有(x, y, w, h, confidence)五個基本參數。Yolo v3輸出了3個不同尺度的feature map,如上圖所示的y1, y2, y3。y1,y2和y3的深度都是255,邊長的規律是13:26:52。
每個預測任務得到的特征大小都為N ×N ×[3?(4+1+80)] ,N為格子大小,3為每個格子得到的邊界框數量, 4是邊界框坐標數量,1是目標預測值,80是類別數量。對于COCO類別而言,有80個類別的概率,所以每個box應該對每個種類都輸出一個概率。所以3×(5 + 80) = 255。這個255就是這么來的。
Yolo v3用上采樣的方法來實現這種多尺度的feature map。在Darknet-53得到的特征圖的基礎上,經過六個DBL結構和最后一層卷積層得到第一個特征圖譜,在這個特征圖譜上做第一次預測。Y1支路上,從后向前的倒數第3個卷積層的輸出,經過一個DBL結構和一次(2,2)上采樣,將上采樣特征與第2個Res8結構輸出的卷積特征張量連接,經過六個DBL結構和最后一層卷積層得到第二個特征圖譜,在這個特征圖譜上做第二次預測。Y2支路上,從后向前倒數第3個卷積層的輸出,經過一個DBL結構和一次(2,2)上采樣,將上采樣特征與第1個Res8結構輸出的卷積特征張量連接,經過六個DBL結構和最后一層卷積層得到第三個特征圖譜,在這個特征圖譜上做第三次預測。
就整個網絡而言,Yolo v3多尺度預測輸出的feature map尺寸為y1:(13×13),y2:(26×26),y3:(52×52)。網絡接收一張(416×416)的圖,經過5個步長為2的卷積來進行降采樣(416 / 2?5 = 13,y1輸出(13×13)。從y1的倒數第二層的卷積層上采樣(x2,up sampling)再與最后一個26×26大小的特征圖張量連接,y2輸出(26×26)。從y2的倒數第二層的卷積層上采樣(x2,up sampling)再與最后一個52×52大小的特征圖張量連接,y3輸出(52×52)
感受一下9種先驗框的尺寸,下圖中藍色框為聚類得到的先驗框。黃色框式ground truth,紅框是對象中心點所在的網格。

預測框一共分為三種情況:正例(positive)、負例(negative)、忽略樣例(ignore)。
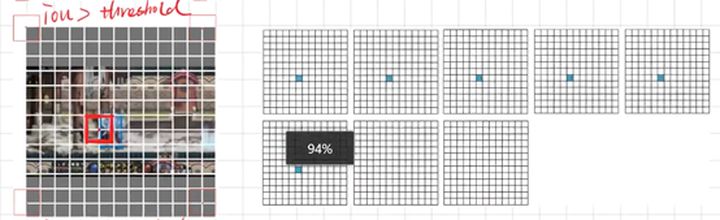
(1)正例:任取一個ground truth, 與上面計算的10647個框全部計算IOU, IOU最大的預測框, 即為正例。并且一個預測框, 只能分配給一個ground truth。 例如第一個ground truth已經匹配了一個正例檢測框, 那么下一個ground truth, 就在余下的10646個檢測框中, 尋找IOU最大的檢測框作為正例。ground truth的先后順序可忽略。正例產生置信度loss、檢測框loss、類別loss。預測框為對應的ground truth box標簽(使用真實的x、y、w、h計算出); 類別標簽對應類別為1, 其余為0; 置信度標簽為1。
(2)忽略樣例:正例除外, 與任意一個ground truth的IOU大于閾值(論文中使用5), 則為忽略樣例。忽略樣例不產生任何loss。
為什么會有忽略樣例?
由于Yolov3采用了多尺度檢測, 那么再檢測時會有重復檢測現象. 比如有一個真實物體,在訓練時被分配到的檢測框是特征圖1的第三個box,IOU達0.98,此時恰好特征圖2的第一個box與該ground truth的IOU達0.95,也檢測到了該ground truth,如果此時給其置信度強行打0的標簽,網絡學習效果會不理想。
(3)負例:正例除外(與ground truth計算后IOU最大的檢測框,但是IOU小于閾值,仍為正例), 與全部ground truth的IOU都小于閾值(0.5), 則為負例。負例只有置信度產生loss, 置信度標簽為0。
如下圖所示:
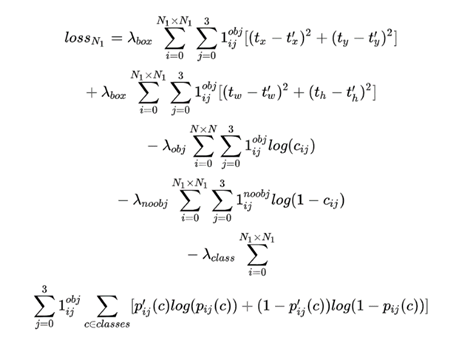
λ為權重參數, 用于控制檢測框loss, obj與noobj的置信度loss, 以及類別
對于正類而言, 1ijobj輸出為1; 對于負例而言, 1ijnoobj輸出為1; 對于忽略樣例而言, 全部為0;
類別采用交叉熵作為損失函數。
類別預測方面Yolo v2網絡中的Softmax分類器,認為一個目標只屬于一個類別,通過輸出Score大小,使得每個框分配到Score最大的一個類別。但在一些復雜場景下,一個目標可能屬于多個類(有重疊的類別標簽),因此Yolo v3用多個獨立的Logistic分類器替代Softmax層解決多標簽分類問題,且準確率不會下降。
舉例說明,原來分類網絡中的softmax層都是假設一張圖像或一個object只屬于一個類別,但是在一些復雜場景下,一個object可能屬于多個類,比如你的類別中有woman和person這兩個類,那么如果一張圖像中有一個woman,那么你檢測的結果中類別標簽就要同時有woman和person兩個類,這就是多標簽分類,需要用Logistic分類器來對每個類別做二分類。Logistic分類器主要用到sigmoid函數,該函數可以將輸入約束在0到1的范圍內,因此當一張圖像經過特征提取后的某一類輸出經過sigmoid函數約束后如果大于0.5,就表示該邊界框負責的目標屬于該類。
物體分數:表示一個邊界框包含一個物體的概率,對于紅色框和其周圍的框幾乎都為1,但邊角的框可能幾乎都為0。物體分數也通過一個sigmoid函數,表示概率值。
類置信度:表示檢測到的物體屬于一個具體類的概率值,以前的YOLO版本使用softmax將類分數轉化為類概率。在YOLOv3中作者決定使用sigmoid函數取代,原因是softmax假設類之間都是互斥的,例如屬于“Person”就不能表示屬于“Woman”,然而很多情況是這個物體既是“Person”也是“Woman”。
我們的網絡生成10647個錨框,而圖像中只有一個狗,怎么將10647個框減少為1個呢?首先,我們通過物體分數過濾一些錨框,例如低于閾值(假設0.5)的錨框直接舍去;然后,使用NMS(非極大值抑制)解決多個錨框檢測一個物體的問題(例如紅色框的3個錨框檢測一個框或者連續的cell檢測相同的物體,產生冗余),NMS用于去除多個檢測框。
具體使用以下步驟:拋棄分數低的框(意味著框對于檢測一個類信心不大);當多個框重合度高且都檢測同一個物體時只選擇一個框(NMS)。
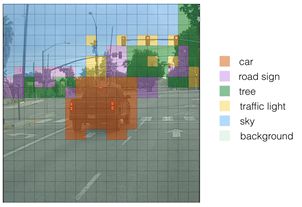
為了更方便理解,我們選用上面的汽車圖像。首先,我們使用閾值進行過濾一部分錨框。模型有19*19*3*85個數,每個盒子由85個數字描述。將(19,19,3,85)分割為下面的形狀:
box_confidence:(19,19,3,1)表示19*19個cell,每個cell的 3個框,每個框有物體的置信度概率;
boxes:(19,19,3,4)表示每個cell 的3個框,每個框的表示;
box_class_probs:(19,19,3,80)表示每個cell的3個框,每個框80個類檢測概率。
每個錨框我們計算下面的元素級乘法并且得到錨框包含一個物體類的概率,如下圖:

即使通過類分數閾值過濾一部分錨框,還剩下很多重合的框。第二個過程叫NMS,里面有個IoU,如下圖所示。
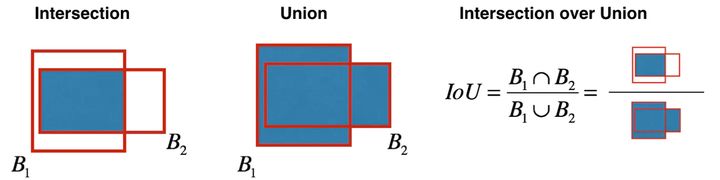
實現非極大值抑制,關鍵在于:選擇一個最高分數的框;計算它和其他框的重合度,去除重合度超過IoU閾值的框;回到步驟1迭代直到沒有比當前所選框低的框。

在Yolo v3的論文里沒有明確提出所用的損失函數,確切地說,Yolo系列論文里面只有Yolo v1明確提了損失函數的公式。在Yolo v1中使用了一種叫sum-square error的損失計算方法,只是簡單的差方相加。我們知道,在目標檢測任務里,有幾個關鍵信息是需要確定的:(x,y),(w,h),class,confidence 。根據關鍵信息的特點可以分為上述四類,損失函數應該由各自特點確定。最后加到一起就可以組成最終的loss function了,也就是一個loss function搞定端到端的訓練。

視頻地址: https://www.bilibili.com/video/BV12y4y1v7L6?from=search&seid=442233808730191461

錨框與目標框做iou


看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





