溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Fractured Mirrors知識點有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Fractured Mirrors知識點有哪些”吧!
背景知識
PAX 是優化 NSM 的 cache 表現,而這篇文章主要關注磁盤IO。NSM 主要針對投影率和選擇率都比較高的場景,而 DSM 適用投影率和選擇率都比較低的場景。
投影率(projectivity)就是 select 語句后邊跟的列數,就是查詢的列數。投影率高就是查的列多。選擇率(selectivity)就是挑剔度,選擇率高,結果集就少。
投影率和選擇率都高,就是只選擇很少的數據,并且把這些數據的大部分屬性都拿出來,比較適合 NSM。
DSM 的缺點及實現優化
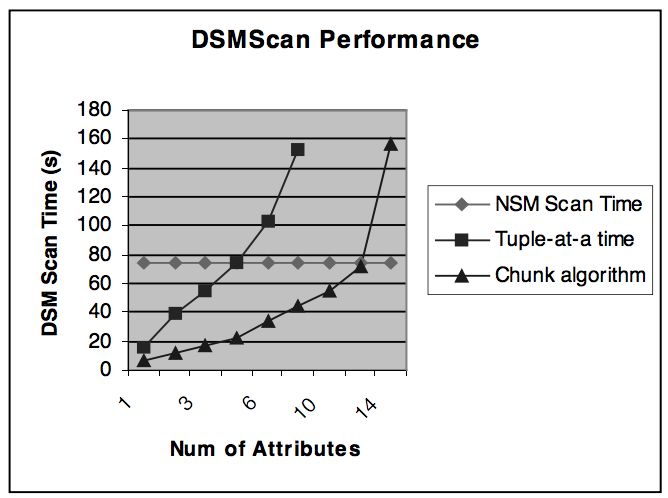
都說 DSM 重組數據耗時,到底多耗時呢?這篇文章給出了一個測試結果。
用 TPC-H 數據集的 Line-item 表(每行數據有16個屬性),一共 1GB 數據。采用 NSM 會占用 1.1 GB 磁盤空間,并且一個全表掃描需要 74.5 秒。
DSM (16個關系,每個關系表有一個 ID 列和一個屬性列)占用 2.8 GB 空間,
為了實現全表掃描,需要對每行數據都重組,隨著選擇的列數從 1 列到 8列,掃描的時間為 68.29s 到 759.39s。比 NSM 模型差的有點大,即使只選擇一列也沒好多少。

這和我一直說的 DSM 在選擇列數少的時候性能很好說法相悖啊,這里有實現問題,作者是用一種最簡單的 DSM 實現對比的,用 slotted page 存放每一對 《ID,屬性列》,不管這個屬性列是定長還是變長。這種實現方式比較浪費空間。
除此之外,每個屬性需要帶一個 ID,比較浪費空間,雖然現在磁盤幾乎沒啥成本,多占空間不是問題,但是多占空間會導致多占 IO,這就成問題了。因此,減少 IO 數據傳輸是很有必要的。
作者針對 DSM 的一些實現上的問題,提出了一個稀疏的 B-Tree 索引,去掉了多余的 ID 列。在這些 DSM 優化的基礎上,又提出了一個基于 Chunk 的多路歸并算法,主要思想就是從單點加載變成批量加載。
作者比較了優化后的單點加載算法、批量加載的算法以及 NSM 掃描的時間。這基本是 DSM 應該有的速度,可以看到一種思想的表現和實現也很相關,你可以把一個非常巧妙的想法實現成一坨屎,也可以把一個很傻的算法實現的很快。
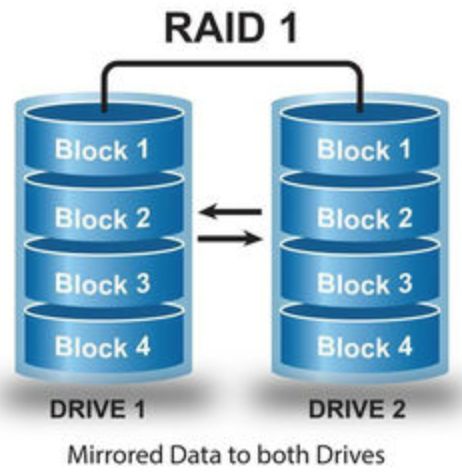
鏡像:Raid 1
鏡像技術就是使用兩塊磁盤將數據做個拷貝,兩塊盤都可以對外提供訪問服務,做負載均衡。兩塊盤的數據存儲結構都一樣。
簡單版 fractured mirror
前邊都是在講 DSM 和 NSM 的基礎和實現。其實這篇文章主要在鏡像上做文章。
因為 NSM 和 DSM 分別適用于不同場景,所以一個簡單的想法是,兩個鏡像,一個用 NSM ,一個用 DSM。這樣不同的查詢負載就可以分配到不同的盤上去執行,哪個快用哪個。
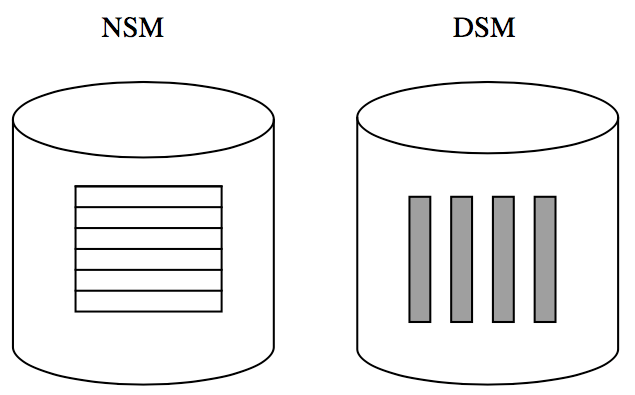
這樣是最簡單的方式,但是有個問題,那就是負載不均衡,可能查詢都是偏 NSM 場景的,那 NSM 的盤就比較忙碌了。
升級版 fractured mirror
為了解決負載均衡的問題,又提出了升級版的。下圖:
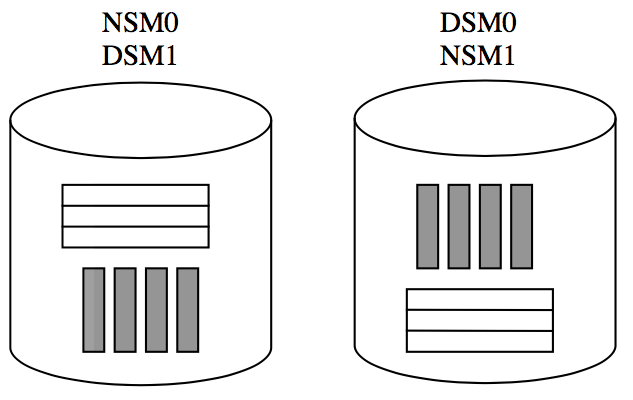
一張表,在一塊盤上前一半數據用 NSM 結構存儲,后一半用 DSM。在另一塊盤上反過來。這是比較簡單的分配策略,也可以用輪轉的分配方式。
這樣,一個全部偏 NSM 的查詢負載,對于每一個查詢來說,假設這個查詢訪問的數據是隨機分布的,這個查詢也可以被均攤到兩塊盤上。負載均衡也沒問題了。
同步方式
原來的 Raid 1,在兩個磁盤上的插入更新操作都一樣,現在物理存儲不同了,一個涉及1行記錄10個屬性的更新操作,在 NSM 上只需要一次寫入就可以了,在 DSM 上就需要 10 次寫入,這個極大地不同步。
解決方式是用全部駐留在內存中的 Differential file,將修改都記錄在這里,定期和磁盤文件合并,保證這個文件大小適中。
刪除使用 bitmap記錄,查詢時候需要將 Differential file 和 bitmap 一起合并。
查詢計劃生成
這樣一個查詢來了之后,可以生成兩個最優計劃,基于 NSM 的最優計劃和基于 DSM 的最優計劃,哪個快用哪個,查詢優化器就變復雜了。而且需要生成兩種查詢計劃,相當于優化了兩遍(optimize-twice)。
另一種方式是自底向上的搜索查詢計劃,把所有可能的掃描操作符和join操作符都生成出來,然后拼出來一個最優的。通過這種方式避免 optimize-twice,而且能生成混合查詢計劃(既包含NSM的又包含DSM的)。
局限
先說查詢計劃生成,都是基于規則的,作者說是避免了優化兩次,但是我覺得只是將兩種查詢計劃生成器混合起來了,打散放到了每一小步上去,比optimize-twice并不簡單,優點是能生成混合的計劃。由于底層存儲的不同,需要維護兩套查詢引擎是比較頭大的。
僅有兩種不同的物理存儲結構,即 NSM 和 DSM,僅適用兩個副本的情況。
Differential file 是個潛在的性能問題,一個盤掛了,從另一個盤恢復的時間沒有度量。
感謝各位的閱讀,以上就是“Fractured Mirrors知識點有哪些”的內容了,經過本文的學習后,相信大家對Fractured Mirrors知識點有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





