溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
源碼 補碼 反碼
數組定義,初始化,使用,隨機數
找最大數,逆置,冒泡排序,
scanf 輸入字符串
字符串處理
字符串溢出等問題
scanf()
gets()
puts()
fputs()
strlen()
strcat()
strncat()
strcmp()
strncmp()
strchr()
strstr()
strtok()
atoi()
atof()
atol()
C 字符串數組
定義數組
遍歷輸出數組每個元素的值
//GCC 編譯方式: C:\MinGW\project>gcc -std=c99 main.c
//編碼環境 GBK
#include <stdio.h>
int main(){
int array[3][4]={{0,1,2,3},{4,5,6,7},{8,9,10,11}};
//遍歷二維數組,并打印
for(int i=0;i< 3;i++){
for(int j=0;j<4;j++){
printf("array[%d][%d]=%d\n",i,j,array[i][j]);
}
}
/*
輸出 :
array[0][0]=0
array[0][1]=1
array[0][2]=2
array[0][3]=3
array[1][0]=4
array[1][1]=5
array[1][2]=6
array[1][3]=7
array[2][0]=8
array[2][1]=9
array[2][2]=10
array[2][3]=11
*/
}字符數組多種初始化方式
研究\0 對字符串數組的影響
#include <stdio.h>
int main(){
//字符串的初始化
//char str[100] ; //定義一個字符串
//char str[100] = {'h','e','l','l','o'}; //定義一個字符串,并初始化
char str[100] = "hello"; //多種初始化
str[0] = 'H';
str[1] = 'e';
str[2] = '\0'; //遇到\0,字符串就結束了
str[3] = 'l';
str[4] = 'o';
printf("%s\n",str); //字符串就是以\0結尾的數組
//輸出 He
printf("str =%d\n",sizeof(str));
//輸出 str =100
}看看字符串數組\0后面是什么東西
#include <stdio.h>
int main(){
//固定字符數組大小,研究字符串初始化后是什么東西
char str[10] = "Hello";
printf("str =%d\n",sizeof(str));
//輸出 str2 =10
printf("str[4] char=>%c HEX=>%x\n",str[4],str[4]);
printf("str[5] char=>%c HEX=>%x\n",str[5],str[5]);
printf("str[6] char=>%c HEX=>%x\n",str[6],str[6]);
printf("str[7] char=>%c HEX=>%x\n",str[7],str[7]);
//輸出:
// str[4] char=>o HEX=>6f
// str[5] char=> HEX=>0
// str[6] char=> HEX=>0
// str[7] char=> HEX=>0
}顯示字符串長度大小
#include <stdio.h>
int main(){
//打印字符數組大小
char str1[] = "Hello";
printf("str1 =%d\n",sizeof(str1));
// 輸出 str1 =6
}修改字符串的內容
#include <stdio.h>
int main(){
//修改字符串內容
char str3[99]="Hello World!";
printf("%s",str3);
printf(str3);
str3[4]='A';
printf(str3);
//輸出 Hello World!Hello World!HellA World!
}逆置數組
#include <stdio.h>
int main(){
char str3[99]="Hello World!";
int low=0;
int high=11; //注意上面的那個字符,11位之后就是\0了
int tmp_var;
while(low<high){
tmp_var =str3[low];
str3[low] =str3[high];
str3[high] =tmp_var;
low++;
high--;
}
printf(str3);
//輸出:
//數組逆置:
//!dlroW AlleH
}顯示GBK編碼的漢字編碼
//GBK 編碼
#include <stdio.h>
int main(){
char str4[100] ="你好 世界";
printf("\n%s\n",str4);
for(int i=0;i<13;i++){
printf("%x\n",str4[i]);
}
}
/*
C:\MinGW\project>gcc -std=c99 str.c
C:\MinGW\project>a.exe
你好 世界
ffffffc4
ffffffe3
ffffffba
ffffffc3
20
ffffffca
ffffffc0
ffffffbd
ffffffe7
0
0
0
0
*/顯示GBK編碼的漢字
//GBK 編碼
#include <stdio.h>
int main(){
//用GBK編碼顯示 漢字
char str5[100];
str5[0]=0xc4;
str5[1]=0xe3;
str5[2]=0;
printf(str5);
//輸出 你
}scanf函數漏洞演示:
遇到空格一定會對scanf有影響
#include <stdio.h>
int main(){
char a[3]={0};
char b[3]={0};
scanf("%s",a);
scanf("%s",b);
printf("==========\n");
printf("%s\n",a);
printf("%s\n",b);
}
測試:
C:\MinGW\project>gcc -std=c99 str.c
正常輸入:
C:\MinGW\project>a.exe
12
qw
==========
12
qw溢出測試1
C:\MinGW\project>a.exe 12 qwqwqwwqwqw ========== wqwwqwqw qwqwqwwqwqw 溢出測試2 C:\MinGW\project>a.exe 123 qwerty ========== rty qwerty
scanf 溢出的原因:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(){
char a[10]={0};
char b[300]={0};
int c[10];
printf("a address %p\n",a);
printf("b address %p\n",b);
printf("c address %p\n",c);
system("pause"); //程序等待在這里
}
/*
C:\MinGW\project>gcc str.c
C:\MinGW\project>a.exe
a address 0028FF16
b address 0028FDEA
c address 0028FDC0
請按任意鍵繼續. . .
*/scanf會把接受到的值,在內存從開始存,不會去管是否已經溢出
這樣會導致覆蓋其他變量的數值
可以看出,程序已經出錯
gets可以解決scanf的無法記錄空格的問題
#include <stdio.h>
int main(){
char a[30]={0};
gets(a);
printf(a);
}
C:\MinGW\project>a.exe
hello world !
hello world !但是依然會緩沖區溢出
#include <stdio.h>
int main(){
char a[3]={0};
char b[3]={0};
gets(a);
gets(b);
printf("%s\n",a);
printf("%s\n",b);
}
C:\MinGW\project>a.exe
123456789
qwertyuioop
rtyuioop
qwertyuioop
C:\MinGW\project>fgets解決了空格 緩存區溢出問題
#include <stdio.h>
int main(){
char a[5]={0};
// fgets(a,5,stdin);
fgets(a,sizeof(a),stdin);
printf("%s\n",a);
}
C:\MinGW\project>gcc -std=c99 str.c
C:\MinGW\project>a.exe
12 e343 423
12 eputs會在輸出后面加入一個\n
#include <stdio.h>
int main(){
char a[]="Hello world !";
puts(a);
printf("==================");
printf(a);
printf("==================");
}
C:\MinGW\project>gcc -std=c99 str.c
C:\MinGW\project>a.exe
Hello world !
==================Hello world !==================fput函數,可以代替printf
#include <stdio.h>
int main(){
char a[]="Hello world !";
fputs(a,stdout);
}
C:\MinGW\project>gcc -std=c99 str.c
C:\MinGW\project>a.exe
Hello world !對輸入的字符,逆置
#include <stdio.h>
int main(){
char a[99]={0};
scanf("%s",a);
printf("%s \n",a);
//strlen 返回是數組有效長度,不包含\0
//獲取字符串真實長度,相當于strlen
int i = 0;
while(a[i] != '\0') i++;
//逆置字符數組
int low = 0;
int high= i-1; //因為字符數組有一個'\0'
char tmp;
while(low < high){
tmp = a[low];
a[low] = a[high];
a[high]= tmp;
low++;
high--;
}
printf("%s \n",a);
}
C:\MinGW\project>gcc -std=c99 str.c
C:\MinGW\project>a.exe
qwertyuio09876
qwertyuio09876
67890oiuytrewq
C:\MinGW\project>a.exe
你好
你好
strlen 4
sizeof 99
煤隳字符串追加:
注意:可能導致溢出
#include <stdio.h>
#include <string.h>
int main(){
char a[99]={0};
char b[300]={0};
scanf("%s",a);
scanf("%s",b);
strcat(a,b); //把b追加到a后面,a要足夠大
printf("a+b=%s\n",a);
}
C:\MinGW\project>a.exe
123
abc
a+b=123abc手動實現strcat
#include <stdio.h>
#include <string.h>
int main(){
char a[99]={0};
char b[300]={0};
scanf("%s",a);
scanf("%s",b);
//strcat(a,b); //把b追加到a后面,a要足夠大
//手寫一個strcat
int lena = strlen(a);
int lenb = strlen(b);
for(int i = lena;i < lena + lenb;i++){
a[i] = b[i-lenb];
}
printf("a+b=%s\n",a);
}
C:\MinGW\project>gcc -std=c99 str.c
C:\MinGW\project>a.exe
123
abc
a+b=123abcstrncat指定追加個數
#include <stdio.h>
#include <string.h>
int main(){
char a[10]={0};
char b[300]={0};
scanf("%s",a);
scanf("%s",b);
strncat(a,b,sizeof(a)-strlen(b)-1); //留一個'\0'
printf("a+b=%s\n",a);
}
/*
C:\MinGW\project>gcc -std=c99 str.c
C:\MinGW\project>a.exe
12345
qwertyuiop
a+b=12345qwertyuiop
*/將最高位做為符號位(0代表正,1代表負),其余各位代表數值本身的絕對值
+7的原碼是00000111 -7的原碼是10000111 +0的原碼是00000000 -0的原碼是10000000
|
一個數如果值為正,那么反碼和原碼相同
一個數如果為負,那么符號位為1,其他各位與原碼相反
+7的反碼00000111 -7的反碼11111000 -0的反碼11111111 |
原碼和反碼都不利于計算機的運算,如:原碼表示的7和-7相加,還需要判斷符號位。
正數:原碼,反碼補碼都相同
負數:最高位為1,其余各位原碼取反,最后對整個數 + 1
-7的補碼:= 10000111(原碼) 111111000(反碼) 11111001(補碼) +0的補碼為00000000 -0的補碼也是00000000 |
補碼符號位不動,其他位求反,最后整個數+ 1,得到原碼
用補碼進行運算,減法可以通過加法實現 |
7-6=1 7的補碼和-6的補碼相加:00000111 + 11111010 = 100000001 進位舍棄后,剩下的00000001就是1的補碼 |
-7+6 = -1 -7的補碼和6的補碼相加:11111001 + 00000110 = 11111111 11111111是-1的補碼 |
內存連續,并且是同一種數據類型的變量,C語言的數組小標好是從0開始的,到n-1.
類型變量名稱[數組元素的個數];
在內存當中是連續的內存空間地址。
int array[10] = {0};//將數組所有元素都初始化為0
int array[10] = {0,1,2,3,4,5,6,7,8,9}
數組中找最大值思路
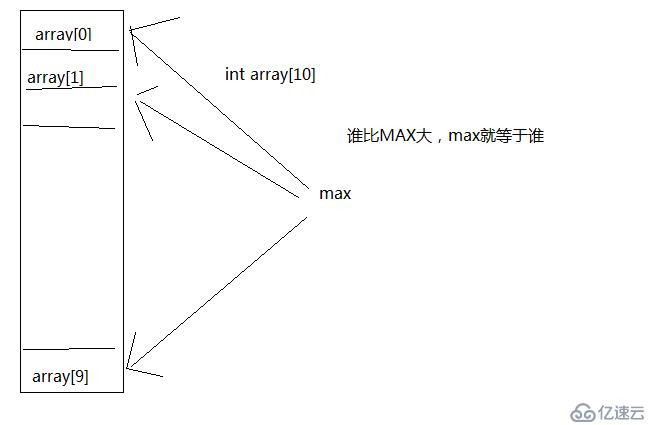
數組中找第二大值思路

逆置數組思路

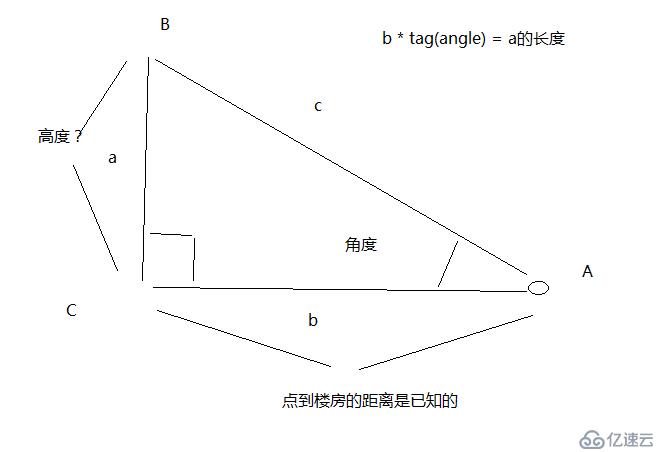
測量樓宇高度的說明
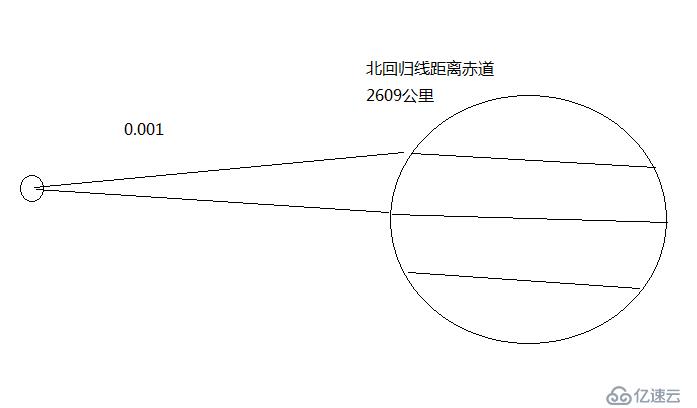
測量地球太陽距離的說明
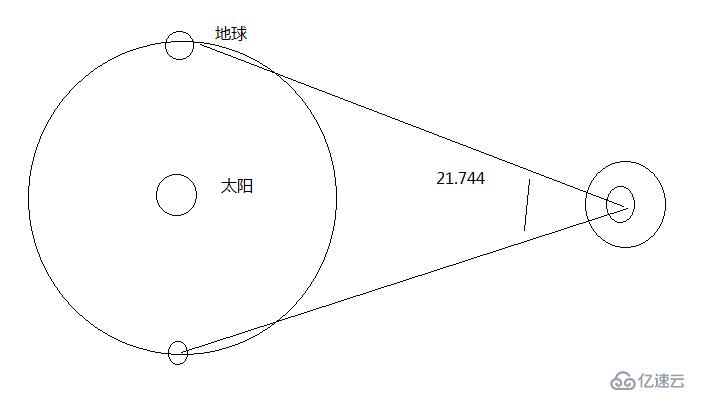
測量太陽木星距離的說明
intarray[3][4];//12個元素的二維數組
int a[3][4] = { { 1, 2, 3, 4 }, { 5, 6, 7, 8 }, { 9, 10, 11, 12 } }; |
char buf[100];
對于C語言字符串其實就是一個最后一個元素為’\0’的char數組.
char buf[] = “hello world”;
頭文件stdlib.h
#include<time.h> int t = (int)time(NULL); srand(t); for (int i = 0; i < 10; i++) { printf("%d\n", rand()); } |
char buf[100] = {0};
scanf(“%s”, buf);
scanf("請輸入i的值%d",&i);
gets沒有解決緩沖區溢出的問題.
gets函數不檢查預留緩沖區是否能夠容納用戶實際輸入的數據。多出來的字符會導致內存溢出,fgets函數改進了這個問題。
由于fgets函數是為讀取文件設計的,所以讀取鍵盤時沒有gets那么方便
char s[100] = { 0 }; fgets(s, sizeof(s), stdin); |
puts函數打印字符串,與printf不同,puts會在最后自動添加一個’\n’
char s[] = "hello world"; puts(s); |
fputs是puts的文件操作版本,
char s[] = "hello world"; fputs(s, stdout); |
strlen返回字符串的長度,但是不包含字符串結尾的’\0’
char buf[10]
sizeof(buf);//返回的是數組buf一共占據了多少字節的內存空間.
char str1[100];
char str2[100];
strcat(str1, str2);//把str2追加到str1的后面
str1一定要有足夠的空間來放str2,不然會內存溢出.
strncat(str1, str2, sizeof(str1) –strlen(str1) - 1);
strcmp(a, “str”);//如果兩個參數所指的字符串內容相同,函數返回0
strncmp(str, “exit”, 4);
strcpy(str, “hello world”);//存在溢出的問題,
strcpy(str, “hello world”, 7);
printf是向屏幕輸出一個字符串
sprintf是向char數組輸出一個字符串,其他行為和printf一模一樣
sprintf也存在緩沖區溢出的問題
strchr(str, ‘c’);
返回值是字符’c’在字符串str中的位置
字符在第一次調用時strtok()必需給予參數s字符串,往后的調用則將參數s設置成NULL每次調用成功則返回指向被分割出片段的指針
char buf[] = "abc@defg@igk"; char *p = strtok(buf, "@");; while (p) { printf("%s\n", p); p = strtok(NULL, "@"); } |
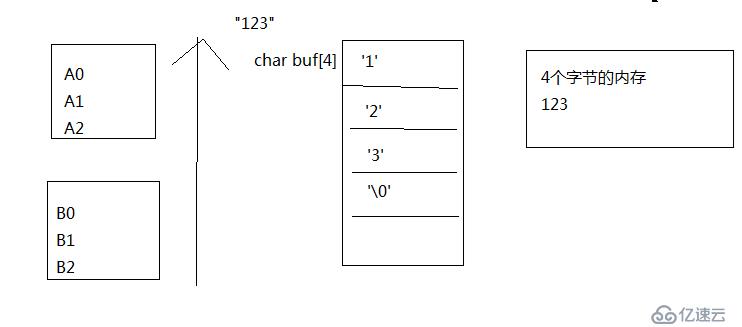
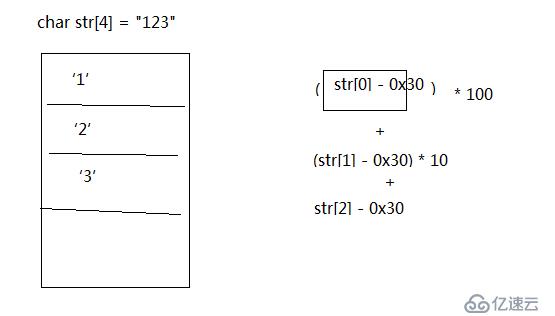
作業說明:
不可以用任何已有的函數,完全自己寫代碼,完成十進制字符串轉化為十進制的整數
作業思路:
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





