溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么深入分析ip2region實現,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
在移動互聯網的應用中,經常需要根據用戶的位置信息等做一些用戶側信息的統計分析。而要拿到用戶的位置信息,一般有兩個方法: GPS 定位的信息和用戶 IP 地址。由于每個手機都不一定會打開 GPS,而且有時并不太需要太精確的位置(到城市這個級別即可),所以根據 IP 地址入手來分析用戶位置是個不錯的選擇。 要做到這個功能得需要一個 IP 和地理位置的映射關系庫,并依賴這個庫啟動一個 IP 轉地理位置的服務。下面結合的 ip2region 來分析映射關系庫的設計以及 IP 如何快速轉換成地理位置。
IP 定位服務很常見,而且很多公司都提供了類似的付費服務,比如阿里,高德,百度等,當然也有公開的免費服務,像 GeoIP,純真IP等。這些服務要么通過 HTML 頁面解析,要么通過接口請求,但不管怎樣都離不開一次 http 請求,更不用說大部分服務都對 QPS 作了限制。下表枚舉了一些常見的通過 IP 獲取地址的方式。
| 開放API服務 | 方式 | 限制 | 樣例 |
|---|---|---|---|
| 淘寶IP地址庫 | 接口 | 每個用戶的 QPS 要小于1 | curl -d "ip=218.97.9.25&accessKey=alibaba-inc" http://ip.taobao.com/outGetIpInfo |
| 高德地圖 | 接口 | 每個用戶每天有10萬的訪問限制,企業開發者有3000萬的訪問限制 | curl "https://restapi.amap.com/v3/ip?ip=218.97.9.25&key=f4cf14aca974dfbb0501c582ce3fce77" |
| GeoIP | HTML 解析 | curl -d "ip=218.97.9.25&submit=提交" https://www.geoip.com | |
| 純真IP | HTML 解析 | curl http://www.cz88.net/ip/?ip=218.97.9.25 |
在日常工作通常需要將大量用戶請求日志中 IP 轉換成用戶位置信息,用作后續的分析。這其中的關鍵是數據量大,處理要快。顯然每次都通過請求 API 公共服務的方式無法滿足我們的日常需求。
對于日常的需求,一種簡單粗暴的做法就是提前通過 API 獲取所有公網 IP 對應的位置信息,按照下面的 TIPS 中我們可以估算出如果通過訪問淘寶IP地址庫來遍歷 3.3 億的國內 IP 地址要 10 年。如果是高德的企業用戶遍歷國內 IP 地址大概要 11 天。感覺這個 11 天還是能夠接受的。
TIPS: IPv4
目前所說的 IP 地址是指 IPv4,它是使用 32 位(4 字節)地址,因此地址空間約有 42.9 億$2^32=4294967296$個, 不過一些地址是作為特殊用途所保留的,如專用網絡(約 1800 萬個)和多播地址(約 2.7 億個),這些減少了可在互聯網上路由的地址數量。 據 wiki 上統計,中國的 IPv4 數量達到 3.3 億,而美國有 15.4 億個。
這里我們約定一下位置信息的數據格式: 國家|區域|省份|城市|ISP,如果接口中返回的字段沒有對應的信息,則對應的字段填充0。那么我們通過順序請求 API 服務可以獲取到如下文件數據(地址依次遞增):
0.0.0.0|0|0|0|內網IP|內網IP 0.0.0.1|0|0|0|內網IP|內網IP ... 1.0.15.255|中國|0|廣東省|廣州市|電信 ... 255.255.255.255|0|0|0|內網IP|內網IP
只要有了這個文件,可以將其讀到內存中,使用字典保存,鍵為 IP 地址,值為位置信息。程序可以在 O(1) 時間復雜度內返回位置信息,不過該程序或文件占用的大小我們可以粗略的計算一下。 假定我們使用 utf-8 進行存儲,一條記錄最短的情況是 0.0.0.0|0|0|0|0|0,占用17個字節,IP 庫文件的大小為 17*4294967296 = 73014444032 B = 71303MB = 71GB。這個大小是任意一個程序不能接受的。
從上面的文件數據發現大量的相鄰 IP 擁有相同的位置信息(客戶在申請一段 IP 地址都會盡量連在一起),所以我們可以將這樣的記錄合成一條記錄。如下文件數據(地址段依次遞增):
0.0.0.0|0.255.255.255|0|0|0|內網IP|內網IP ... 1.0.8.0|1.0.15.255|中國|0|廣東省|廣州市|電信 ... 224.0.0.0|255.255.255.255|0|0|0|內網IP|內網IP
ip2region 庫中最新的 ip.merge.txt 共有 658207 記錄,文件大小 39 M。
從上面的文件數據發現大量的IP地址以字符串形式存儲,而 IPv4 是使用 32 位地址。所以將其轉換成整型進行存儲可以大大節省空間,比如像最短的字符串 0.0.0.0 占據 7 字節,最長的字符串 111.111.111.111 占據 15 字節,如果將其轉換成整型,他們都占據 4 字節。0.0.0.0 是 int(0), 111.111.111.111 是 int(1869573999)。
從上面的文件數據發現相同的位置信息會對應不同的 IP 段(客戶可能在不同的時間段去申請 IP 段),所以還是有大量的位置信息在 IP 庫文件中,在內存中我們可以只保留一份位置信息,并使用指針或者文件偏移量+數據長度來獲取對應的位置信息。
根據上面的優化,我們可以生成最終的IP庫:ip2region.db,該文件只有8.1M。
IP 庫文件ip2region.db的結構分為四個部分:super 塊, header索引區,數據區,索引區。具體如下圖所示:
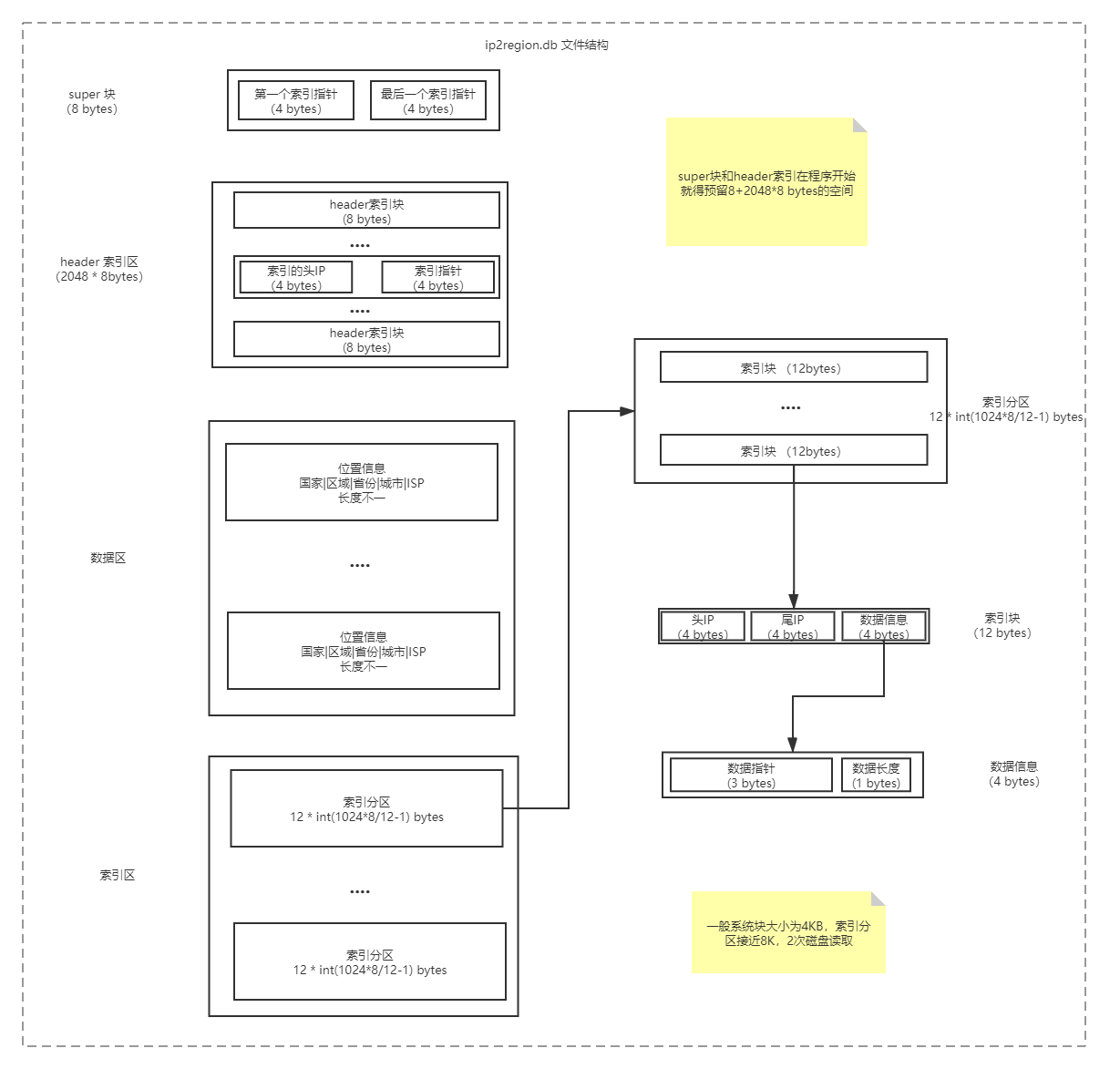
super 塊
用來保存索引塊的起始地址和結束地址,第一個索引指針指向索引塊的開始位置,也就是第一個索引分區的第一個索引塊, 最后一個索引指針 指向索引塊的結束位置-12,也就是最后一個索引分區的最后一個索引塊的頭地址。這樣查詢的時候直接讀取super塊 8 個字節,就能快速獲取索引塊的地址范圍。
header 索引區
header索引是對索引塊的二級索引,專門為b+tree搜索服務的。索引區總長度除以索引分區長度12*(1024*8/12-1)就是 header 索引的實際索引數。該區域大小為 2048*8 bytes, 由 2048 個 8 bytes 的 header 索引塊組成。header索引塊前四個字節存儲每個索引分區第一個索引塊的起始ip值,后四個字節指向該索引塊的地址。
header索引區之所以定義為接近16k,是因為可以通過四次磁盤讀取讀取整個header索引區,然后在內存中進行查詢,查詢的結果可以確定該ip在索引區的某個索引分區內,然后再根據地址兩次讀取8k 索引分區到內存,再在內存中查詢,從而減少磁盤讀取的次數。
數據區
保存的數據,數據格式如下:中國|華南|廣東省|深圳市|鵬博士, 分別表示國家,區域,省份,城市,運營商
索引區
索引區是由索引塊構成, 每個索引塊占 12 字節,包括起始IP, 結束IP, 數據信息。數據信息中前三個字節保存數據地址,后一個字節保存數據長度。 每一條索引塊對應 ip.merge.txt 中的一條記錄,表示一個 IP 段的索引。
在檢索中當指定 IP 在某個索引塊的起始IP和結束IP中間,即表示命中索引。再通過索引塊中的數據地址和數據長度,就能從 ip2region.db 讀取對應的位置信息數據。
ip2region 的 Github 倉庫中提供了 ip2region.db 的生成過程,是用 JAVA 寫的,其類圖如下所示: 
通過熟悉生成 ip2region.db 的源碼,簡述一下其生成過程如下:
通過 RandomAccessFile 在文件中預留 8 bytes 的 super 塊和 2048*8 bytes 的 header 索引區
掃描 ip.merge.txt 文件,對每一條記錄作如下處理:
依據每一條記錄的起始IP, 結束IP 和數據,生成一個索引塊, 前四個字節存儲起始IP, 中間四個字節存儲結束IP, 后四個字節存儲已經計算出的數據地址(通過 RandomAccessFile 寫入,這里維護一個位置信息到文件位置的字典,保證同一個位置信息只寫入一次。),并將索引塊暫存在 indexPool 鏈表中。這一步會將數據區的所有位置信息確定。
掃描完 ip.merge.txt 中所有的記錄, 將 indexPool 中所有的索引塊寫到數據區后面。在此過程中將 int(1024*8/12-1)= 681 個索引塊組成一個索引分區,并記錄下每個索引分區第一個索引塊的起始IP和地址信息(header塊),并暫存在 headerPool 鏈表中。此外還會將索引區的起始位置和結束位置記錄下來。
調整 RandomAccessFile 指向文件開頭,寫入索引區的起始位置存儲到 super 塊的前四個字節,結束位置存儲到 super 塊的后四個字節。
繼續將 headerPool 中的 header 塊寫入到 header 區。
調整 RandomAccessFile 指向文件結尾,寫入時間戳和版權信息。
TIPS: ip2region 倉庫中還使用了 global_region.csv 數據,該文件有5列(行號,,區域,,郵政編碼),對應著區域的具體信息,可以往數據區每個位置信息中填充。
ip2region 提供三種查詢算法,最差的查詢耗時都是ms級別的。分別是內存二分搜索,b+tree搜索,二分查找。耗時依次增加。其搜索結構圖如下: 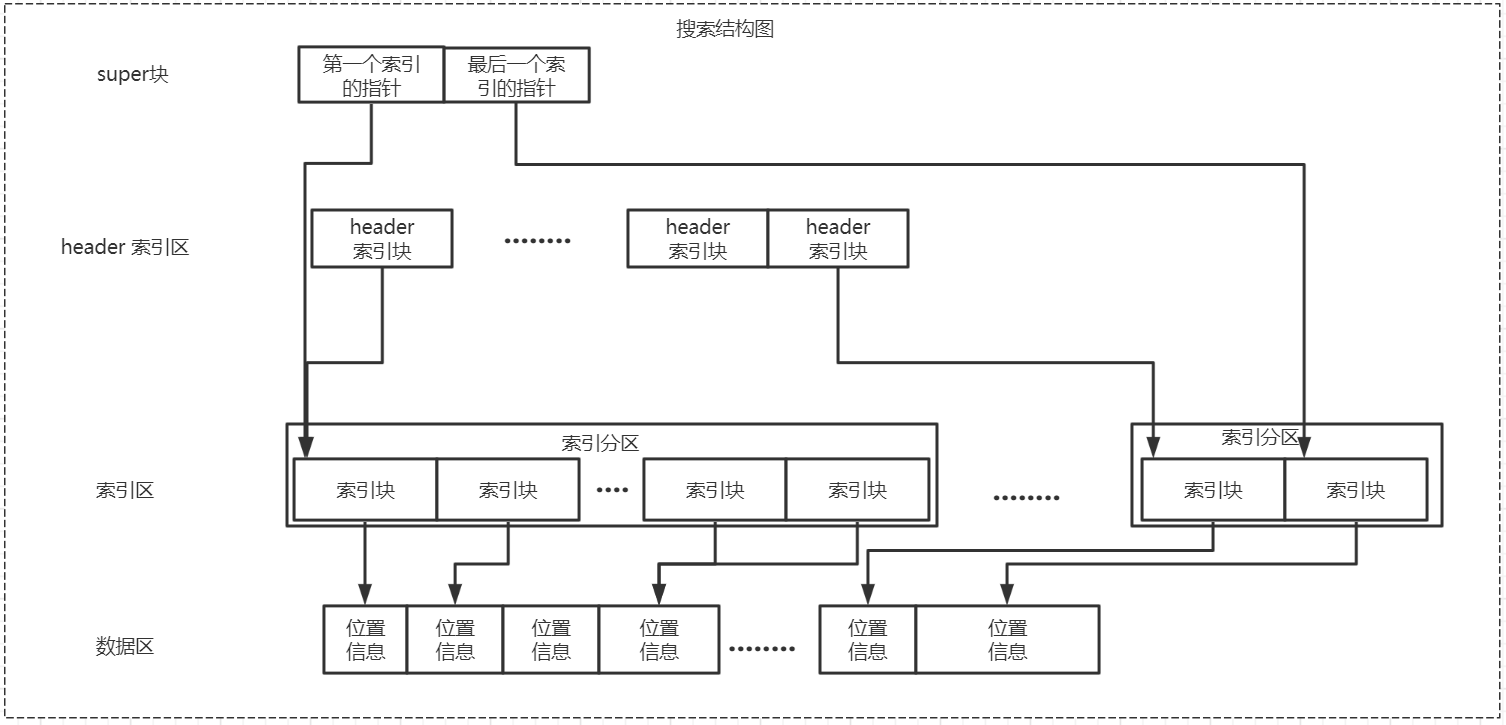
通過 super 塊可以拿到索引區的起始位置和結束位置,而且每個索引塊都是 12 bytes,其中的 IP 地址都是遞增的,所以可以使用二分搜索來快速獲取位置信息。其步驟如下:
把 IP 值通過 ip2long 方法轉為整型
讀取 super 塊獲取索引區的起始位置和結束位置,二者相減 +1 可得索引塊的總個數
采用二分法直接求解,比較索引塊中起始IP,結尾IP 和當前 IP 的大小,即可找到該 IP 對應的索引塊,根據索引塊后面四個字節得到數據地址和數據長度,從而拿到位置信息。
b+tree 搜索用到了 header 索引區,第一步先在 header 索引區中使用二分搜索,定位到某個索引分區后,再在對應的索引分區中使用二分搜索。相比較二分搜索而言,它的速度更快,原因是讀磁盤的次數遠低于二分搜索。其步驟如下:
把 IP 值通過 ip2long 轉為整型
使用二分法在 header 索引區中搜索,比較得到對應的 header 索引塊以及其對應的索引分區。
讀取對應索引分區,再通過二分法定位到對應的索引塊,從而獲得位置信息。
該方法和二分搜索方法類似,區別就是前者將 ip2region.db 全部讀進內存中,后者則是通過不斷讀取 ip2region.db 文件。
ip2region 庫只解決了一個非常常見的 IP 定位問題,但將這個服務做到了又小又快(當然還提供了多語言的客戶端),從而在 Github 上獲得了 8.4k 的 star。
相鄰 IP 的位置信息相同,通過 IP 段來解決相鄰 IP 對應相同位置信息,避免位置信息被重復存儲
IP 轉換成 INT,像字符串 111.111.111.111 被轉換成int(1869573999),從 15Byte 縮小到 4Byte
不同的 IP 段也有相同的位置信息,通過指針來指向特定的位置信息,保證位置信息只保存一次(全量掃描存儲進字典中)
IP 有序,使用二分搜索將時間復雜度降到 O(logN)
二級索引 header 索引區的使用,降低磁盤讀寫頻率,先確定索引分區,再從索引分區確定索引位置,再確定位置信息數據。
支持 java、C#、php、c、python、nodejs、php擴展(php5和php7)、golang、rust、lua、lua_c, nginx。
關于怎么深入分析ip2region實現問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





