溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
基于Mixerless Telemetry如何實現漸進式灰度發布系,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
作為CNCF成員,Weave Flagger提供了持續集成和持續交付的各項能力。Flagger將漸進式發布總結為3類:
灰度發布/金絲雀發布(Canary):用于漸進式切流到灰度版本(progressive traffic shifting)
A/B測試(A/B Testing):用于根據請求信息將用戶請求路由到A/B版本(HTTP headers and cookies traffic routing)
藍綠發布(Blue/Green):用于流量切換和流量復制 (traffic switching and mirroring)
本篇將介紹Flagger on ASM的漸進式灰度發布實踐。
1 部署Flagger
執行如下命令部署flagger(完整腳本參見:demo_canary.sh)。
alias k="kubectl --kubeconfig $USER_CONFIG" alias h="helm --kubeconfig $USER_CONFIG" cp $MESH_CONFIG kubeconfig k -n istio-system create secret generic istio-kubeconfig --from-file kubeconfig k -n istio-system label secret istio-kubeconfig istio/multiCluster=true h repo add flagger https://flagger.app h repo update k apply -f $FLAAGER_SRC/artifacts/flagger/crd.yaml h upgrade -i flagger flagger/flagger --namespace=istio-system \ --set crd.create=false \ --set meshProvider=istio \ --set metricsServer=http://prometheus:9090 \ --set istio.kubeconfig.secretName=istio-kubeconfig \ --set istio.kubeconfig.key=kubeconfig
2 部署Gateway
在灰度發布過程中,Flagger會請求ASM更新用于灰度流量配置的VirtualService,這個VirtualService會使用到命名為public-gateway的Gateway。為此我們創建相關Gateway配置文件public-gateway.yaml如下:
apiVersion: networking.istio.io/v1alpha3 kind: Gateway metadata: name: public-gateway namespace: istio-system spec: selector: istio: ingressgateway servers: - port: number: 80 name: http protocol: HTTP hosts: - "*"
執行如下命令部署Gateway:
kubectl --kubeconfig "$MESH_CONFIG" apply -f resources_canary/public-gateway.yaml
3 部署flagger-loadtester
flagger-loadtester是灰度發布階段,用于探測灰度POD實例的應用。
執行如下命令部署flagger-loadtester:
kubectl --kubeconfig "$USER_CONFIG" apply -k "https://github.com/fluxcd/flagger//kustomize/tester?ref=main"
4 部署PodInfo及其HPA
我們首先使用Flagger發行版自帶的HPA配置(這是一個運維級的HPA),待完成完整流程后,我們再使用應用級的HPA。
執行如下命令部署PodInfo及其HPA:
kubectl --kubeconfig "$USER_CONFIG" apply -k "https://github.com/fluxcd/flagger//kustomize/podinfo?ref=main"
1 部署Canary
Canary是基于Flagger進行灰度發布的核心CRD,詳見How it works。我們首先部署如下Canary配置文件podinfo-canary.yaml,完成完整的漸進式灰度流程,然后在此基礎上引入應用維度的監控指標,來進一步實現應用有感知的漸進式灰度發布。
apiVersion: flagger.app/v1beta1 kind: Canary metadata: name: podinfo namespace: test spec: # deployment reference targetRef: apiVersion: apps/v1 kind: Deployment name: podinfo # the maximum time in seconds for the canary deployment # to make progress before it is rollback (default 600s) progressDeadlineSeconds: 60 # HPA reference (optional) autoscalerRef: apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler name: podinfo service: # service port number port: 9898 # container port number or name (optional) targetPort: 9898 # Istio gateways (optional) gateways: - public-gateway.istio-system.svc.cluster.local # Istio virtual service host names (optional) hosts: - '*' # Istio traffic policy (optional) trafficPolicy: tls: # use ISTIO_MUTUAL when mTLS is enabled mode: DISABLE # Istio retry policy (optional) retries: attempts: 3 perTryTimeout: 1s retryOn: "gateway-error,connect-failure,refused-stream" analysis: # schedule interval (default 60s) interval: 1m # max number of failed metric checks before rollback threshold: 5 # max traffic percentage routed to canary # percentage (0-100) maxWeight: 50 # canary increment step # percentage (0-100) stepWeight: 10 metrics: - name: request-success-rate # minimum req success rate (non 5xx responses) # percentage (0-100) thresholdRange: min: 99 interval: 1m - name: request-duration # maximum req duration P99 # milliseconds thresholdRange: max: 500 interval: 30s # testing (optional) webhooks: - name: acceptance-test type: pre-rollout url: http://flagger-loadtester.test/ timeout: 30s metadata: type: bash cmd: "curl -sd 'test' http://podinfo-canary:9898/token | grep token" - name: load-test url: http://flagger-loadtester.test/ timeout: 5s metadata: cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
執行如下命令部署Canary:
kubectl --kubeconfig "$USER_CONFIG" apply -f resources_canary/podinfo-canary.yaml
部署Canary后,Flagger會將名為podinfo的Deployment復制為podinfo-primary,并將podinfo-primary擴容至HPA定義的最小POD數量。然后逐步將名為podinfo的這個Deployment的POD數量將縮容至0。也就是說,podinfo將作為灰度版本的Deployment,podinfo-primary將作為生產版本的Deployment。
同時,創建3個服務——podinfo、podinfo-primary和podinfo-canary,前兩者指向podinfo-primary這個Deployment,最后者指向podinfo這個Deployment。
2 升級podinfo
執行如下命令,將灰度Deployment的版本從3.1.0升級到3.1.1:
kubectl --kubeconfig "$USER_CONFIG" -n test set image deployment/podinfo podinfod=stefanprodan/podinfo:3.1.1
3 漸進式灰度發布
此時,Flagger將開始執行如本系列第一篇所述的漸進式灰度發布流程,這里再簡述主要流程如下:
逐步擴容灰度POD、驗證
漸進式切流、驗證
滾動升級生產Deployment、驗證
100%切回生產
縮容灰度POD至0
我們可以通過如下命令觀察這個漸進式切流的過程:
while true; do kubectl --kubeconfig "$USER_CONFIG" -n test describe canary/podinfo; sleep 10s;done
輸出的日志信息示意如下:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning Synced 39m flagger podinfo-primary.test not ready: waiting for rollout to finish: observed deployment generation less then desired generation Normal Synced 38m (x2 over 39m) flagger all the metrics providers are available! Normal Synced 38m flagger Initialization done! podinfo.test Normal Synced 37m flagger New revision detected! Scaling up podinfo.test Normal Synced 36m flagger Starting canary analysis for podinfo.test Normal Synced 36m flagger Pre-rollout check acceptance-test passed Normal Synced 36m flagger Advance podinfo.test canary weight 10 Normal Synced 35m flagger Advance podinfo.test canary weight 20 Normal Synced 34m flagger Advance podinfo.test canary weight 30 Normal Synced 33m flagger Advance podinfo.test canary weight 40 Normal Synced 29m (x4 over 32m) flagger (combined from similar events): Promotion completed! Scaling down podinfo.test
相應的Kiali視圖(可選),如下圖所示:
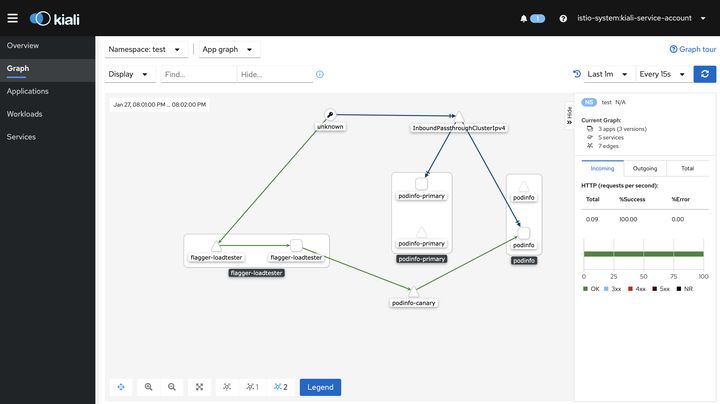
到此,我們完成了一個完整的漸進式灰度發布流程。如下是擴展閱讀。
在完成上述漸進式灰度發布流程的基礎上,我們接下來再來看上述Canary配置中,關于HPA的配置。
autoscalerRef: apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler name: podinfo
這個名為podinfo的HPA是Flagger自帶的配置,當灰度Deployment的CPU利用率達到99%時擴容。完整配置如下:
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 4 metrics: - type: Resource resource: name: cpu target: type: Utilization # scale up if usage is above # 99% of the requested CPU (100m) averageUtilization: 99
我們在前面一篇中講述了應用級擴縮容的實踐,在此,我們將其應用于灰度發布的過程中。
1 感知應用QPS的HPA
執行如下命令部署感知應用請求數量的HPA,實現在QPS達到10時進行擴容(完整腳本參見:advanced_canary.sh):
kubectl --kubeconfig "$USER_CONFIG" apply -f resources_hpa/requests_total_hpa.yaml
相應地,Canary配置更新為:
autoscalerRef: apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler name: podinfo-total
2 升級podinfo
執行如下命令,將灰度Deployment的版本從3.1.0升級到3.1.1:
kubectl --kubeconfig "$USER_CONFIG" -n test set image deployment/podinfo podinfod=stefanprodan/podinfo:3.1.1
3 驗證漸進式灰度發布及HPA
命令觀察這個漸進式切流的過程:
while true; do k -n test describe canary/podinfo; sleep 10s;done
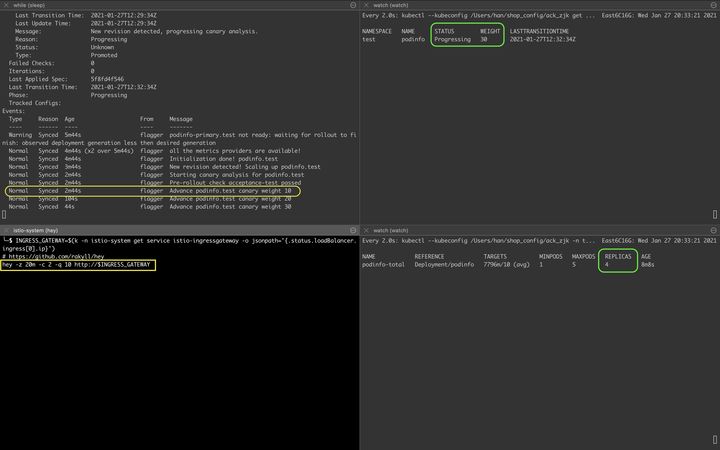
在漸進式灰度發布過程中(在出現Advance podinfo.test canary weight 10信息后,見下圖),我們使用如下命令,從入口網關發起請求以增加QPS:
INGRESS_GATEWAY=$(kubectl --kubeconfig $USER_CONFIG -n istio-system get service istio-ingressgateway -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
hey -z 20m -c 2 -q 10 http://$INGRESS_GATEWAY使用如下命令觀察漸進式灰度發布進度:
watch kubectl --kubeconfig $USER_CONFIG get canaries --all-namespaces
使用如下命令觀察hpa的副本數變化:
watch kubectl --kubeconfig $USER_CONFIG -n test get hpa/podinfo-total
結果如下圖所示,在漸進式灰度發布過程中,當切流到30%的某一時刻,灰度Deployment的副本數為4:
在完成上述灰度中的應用級擴縮容的基礎上,最后我們再來看上述Canary配置中,關于metrics的配置:
analysis: metrics: - name: request-success-rate # minimum req success rate (non 5xx responses) # percentage (0-100) thresholdRange: min: 99 interval: 1m - name: request-duration # maximum req duration P99 # milliseconds thresholdRange: max: 500 interval: 30s # testing (optional)
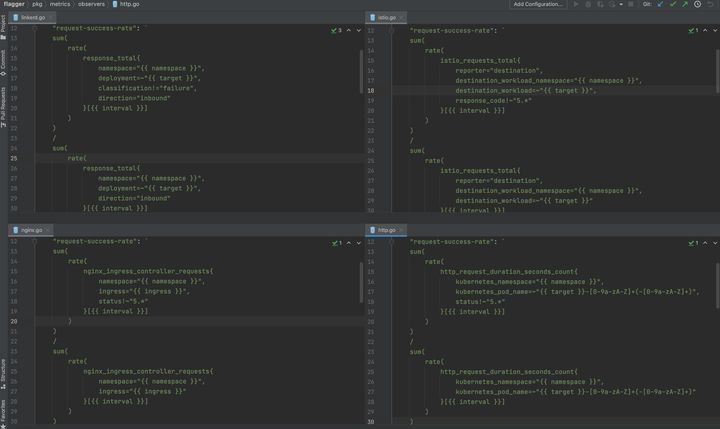
1 Flagger內置監控指標
到目前為止,Canary中使用的metrics配置一直是Flagger的兩個內置監控指標:請求成功率(request-success-rate)和請求延遲(request-duration)。如下圖所示,Flagger中不同平臺對內置監控指標的定義,其中,istio使用的是本系列第一篇介紹的Mixerless Telemetry相關的遙測數據。
2 自定義監控指標
為了展示灰度發布過程中,遙測數據為驗證灰度環境帶來的更多靈活性,我們再次以istio_requests_total為例,創建一個名為not-found-percentage的MetricTemplate,統計請求返回404錯誤碼的數量占請求總數的比例。
配置文件metrics-404.yaml如下(完整腳本參見:advanced_canary.sh):
apiVersion: flagger.app/v1beta1
kind: MetricTemplate
metadata:
name: not-found-percentage
namespace: istio-system
spec:
provider:
type: prometheus
address: http://prometheus.istio-system:9090
query: |
100 - sum(
rate(
istio_requests_total{
reporter="destination",
destination_workload_namespace="{{ namespace }}",
destination_workload="{{ target }}",
response_code!="404"
}[{{ interval }}]
)
)
/
sum(
rate(
istio_requests_total{
reporter="destination",
destination_workload_namespace="{{ namespace }}",
destination_workload="{{ target }}"
}[{{ interval }}]
)
) * 100執行如下命令創建上述MetricTemplate:
k apply -f resources_canary2/metrics-404.yaml
相應地,Canary中metrics的配置更新為:
analysis: metrics: - name: "404s percentage" templateRef: name: not-found-percentage namespace: istio-system thresholdRange: max: 5 interval: 1m
3 最后的驗證
最后,我們一次執行完整的實驗腳本。腳本advanced_canary.sh示意如下:
#!/usr/bin/env sh SCRIPT_PATH="$( cd "$(dirname "$0")" >/dev/null 2>&1 pwd -P )/" cd "$SCRIPT_PATH" || exit source config alias k="kubectl --kubeconfig $USER_CONFIG" alias m="kubectl --kubeconfig $MESH_CONFIG" alias h="helm --kubeconfig $USER_CONFIG" echo "#### I Bootstrap ####" echo "1 Create a test namespace with Istio sidecar injection enabled:" k delete ns test m delete ns test k create ns test m create ns test m label namespace test istio-injection=enabled echo "2 Create a deployment and a horizontal pod autoscaler:" k apply -f $FLAAGER_SRC/kustomize/podinfo/deployment.yaml -n test k apply -f resources_hpa/requests_total_hpa.yaml k get hpa -n test echo "3 Deploy the load testing service to generate traffic during the canary analysis:" k apply -k "https://github.com/fluxcd/flagger//kustomize/tester?ref=main" k get pod,svc -n test echo "......" sleep 40s echo "4 Create a canary custom resource:" k apply -f resources_canary2/metrics-404.yaml k apply -f resources_canary2/podinfo-canary.yaml k get pod,svc -n test echo "......" sleep 120s echo "#### III Automated canary promotion ####" echo "1 Trigger a canary deployment by updating the container image:" k -n test set image deployment/podinfo podinfod=stefanprodan/podinfo:3.1.1 echo "2 Flagger detects that the deployment revision changed and starts a new rollout:" while true; do k -n test describe canary/podinfo; sleep 10s;done
使用如下命令執行完整的實驗腳本:
sh progressive_delivery/advanced_canary.sh
實驗結果示意如下:
#### I Bootstrap #### 1 Create a test namespace with Istio sidecar injection enabled: namespace "test" deleted namespace "test" deleted namespace/test created namespace/test created namespace/test labeled 2 Create a deployment and a horizontal pod autoscaler: deployment.apps/podinfo created horizontalpodautoscaler.autoscaling/podinfo-total created NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo-total Deployment/podinfo <unknown>/10 (avg) 1 5 0 0s 3 Deploy the load testing service to generate traffic during the canary analysis: service/flagger-loadtester created deployment.apps/flagger-loadtester created NAME READY STATUS RESTARTS AGE pod/flagger-loadtester-76798b5f4c-ftlbn 0/2 Init:0/1 0 1s pod/podinfo-689f645b78-65n9d 1/1 Running 0 28s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/flagger-loadtester ClusterIP 172.21.15.223 <none> 80/TCP 1s ...... 4 Create a canary custom resource: metrictemplate.flagger.app/not-found-percentage created canary.flagger.app/podinfo created NAME READY STATUS RESTARTS AGE pod/flagger-loadtester-76798b5f4c-ftlbn 2/2 Running 0 41s pod/podinfo-689f645b78-65n9d 1/1 Running 0 68s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/flagger-loadtester ClusterIP 172.21.15.223 <none> 80/TCP 41s ...... #### III Automated canary promotion #### 1 Trigger a canary deployment by updating the container image: deployment.apps/podinfo image updated 2 Flagger detects that the deployment revision changed and starts a new rollout: Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning Synced 10m flagger podinfo-primary.test not ready: waiting for rollout to finish: observed deployment generation less then desired generation Normal Synced 9m23s (x2 over 10m) flagger all the metrics providers are available! Normal Synced 9m23s flagger Initialization done! podinfo.test Normal Synced 8m23s flagger New revision detected! Scaling up podinfo.test Normal Synced 7m23s flagger Starting canary analysis for podinfo.test Normal Synced 7m23s flagger Pre-rollout check acceptance-test passed Normal Synced 7m23s flagger Advance podinfo.test canary weight 10 Normal Synced 6m23s flagger Advance podinfo.test canary weight 20 Normal Synced 5m23s flagger Advance podinfo.test canary weight 30 Normal Synced 4m23s flagger Advance podinfo.test canary weight 40 Normal Synced 23s (x4 over 3m23s) flagger (combined from similar events): Promo
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





