溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“KAFKA中rebalance是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
讓我們從頭到尾梳理一下rebalance。
中文直譯,就是重平衡。
是什么去重平衡呢?消費組內的消費者成員去重平衡。(消費組的概念如果不清楚各位先自行百度,后續我寫到消費模塊的時候才會提到這些概念)
為什么需要重平衡呢?因為消費組內成員的故障轉移和動態分區分配。
翻譯一下:
消費組內成員的故障轉移:當一個消費組內有三個消費者A,B,C,分別消費分區:a,b,c
A -> a B -> b C -> c
此時如果A消費者出了點問題,那么就意味著a分區沒有消費者進行消費了,那這肯定不行,那么就通過rebalance去將a分區分配給其他還存活著的消費者客戶端,rebalance后可能得到的消費策略:
A -> a (GG) B -> b,a C -> c
這就是消費組內成員的故障轉移,就是某個消費者客戶端出問題之后把它原本消費的分區通過REBALNACE分配給其他存活的消費者客戶端。
動態分區分配:當某個topic的分區數變化,對于消費組而言可消費的分區數變化了,因此就需要rebalance去重新進行動態分區分配,舉個栗子,原本某topic只有3個分區,我現在擴成了10個分區,那么不就意味著多了7個分區沒有消費者消費嗎?這顯然是不行的,因此就需要rebalance過程去進行分區分配,讓現有的消費者去把這10個分區全部消費到。
這個其實在上面一小節已經提到的差不多了,在這個小節再做一點補充和總結。
觸發條件:
消費組內成員變化:下線/上線/故障被踢出。
消費的分區數變化:topic被刪了,topic分區數增加了。
coordinator節點出問題了:因為消費組的元數據信息都是在coordinator節點的,因此coordinator節點出問題也會觸發rebalance去找一個新的coordinator節點。怎么找呢?顯然就是走一遍FIND_COORDINATOR請求嘛,然后找到負載最低的那個節點問一下,我的新的coordinator在哪兒呀?然后得到答案之后讓消費者客戶端去連新的coordinator節點。
整個rebalance的過程,是一個狀態機流轉的過程,整體過程示意圖如下:圖源:https://www.cnblogs.com/huxi2b/p/6815797.html 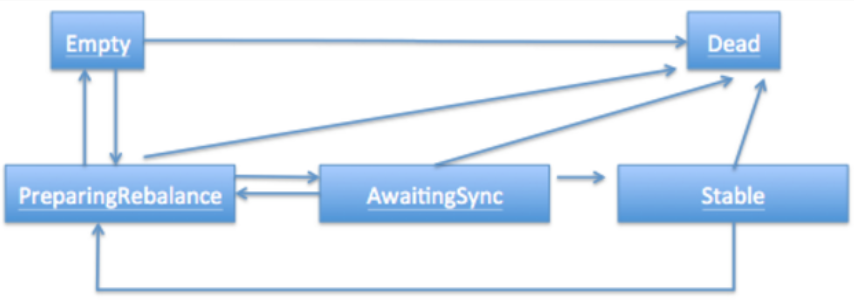
其實上面這個狀態機流轉過程在明白原理的情況下,已經非常清晰了,但是如果沒看過源碼的,依舊不知道為什么是這么流轉的,什么情況下狀態是Empty呢,什么狀態下是Stable呢?什么時候Empty狀態會轉換為PreparingRebalance狀態呢?
下面我就根據請求順序來看下整個狀態的流轉過程: 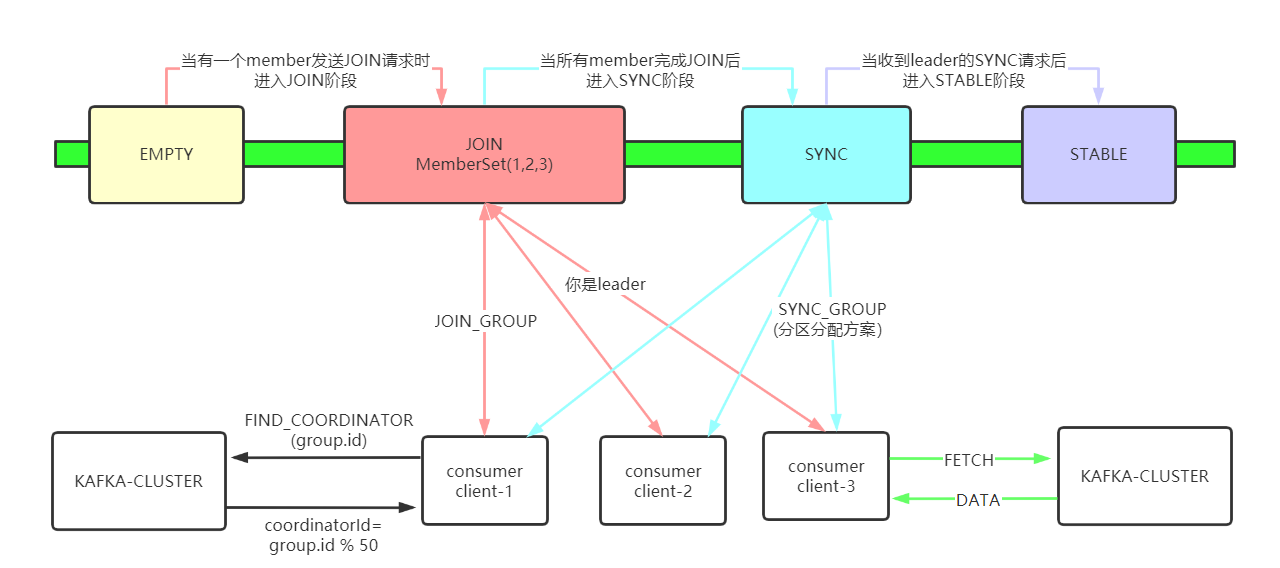
讓我們來回答上個小節后面提出的幾個比較細節的問題:
這些請求都帶有哪些關鍵數據?
在FIND_COORDINATOR請求的時候,會帶上自己的group.id值,這個值是用來計算它的coordinator到底在哪兒的,對應的計算方法就是:coordinatorId=groupId.hash % 50 這個算出來是個數字,代表著具體的分區,哪個topic的分區呢?顯然是__consumer_offsets了。
在JOIN_GROUP請求的時候,是沒帶什么關鍵參數的,但是在響應的時候會挑選一個客戶端作為leader,然后在響應中告訴它被選為了leader并且把消費組元數據信息發給它,然后讓該客戶端去進行分區分配。
在SYNC_GROUP請求的時候,leader就會帶上它根據具體的策略已經分配好的分區分配方案,服務端收到后就更新到元數據里面去,然后其余的consumer客戶端只要一發送SYNC請求過來就告訴它要消費哪些分區,然后讓它自己去消費就ok了。
到底是哪個階段導致rebalance過程會劣化到幾分鐘?
我圖中特意將JOIN階段標位紅色,就是讓這個階段顯得顯眼一些,沒錯就是這個階段會導致rebalance整個過程耗時劣化到幾分鐘。
具體的原因就是JOIN階段會等待原先組內存活的成員發送JOIN_GROUP請求過來,如果原先組內的成員因為業務處理一直沒有發送JOIN_GROUP請求過來,服務端就會一直等待,直到超時。這個超時時間就是max.poll.interval.ms的值,默認是5分鐘,因此這種情況下rebalance的耗時就會劣化到5分鐘,導致所有消費者都無法進行正常消費,影響非常大。
為什么要分為這么多階段?
這個主要是設計上的考慮,整個過程設計的還是非常優雅的,第一次連上的情況下需要三次請求,正常運行的consumer去進行rebalance只需要兩次請求,因為它原先就知道自己的coordinator在哪兒,因此就不需要FIND_COORDINATOR請求了,除非是它的coordinator宕機了。
回答完這些問題,是不是對整個rebalance過程理解加深一些了呢?其實還有很多細節沒有涉及到,例如consumer客戶端什么時候會進入rebalance狀態?服務端是如何等待原先消費組內的成員發送JOIN_GROUP請求的呢?這些問題就只能一步步看源碼了。
FIND_COORDINATOR請求的源碼我就不打寫了,很簡單大家可以自己翻一下,就是帶了個group.id上去,上面都提到了。
從這段函數我們知道,如果加入一個新的消費組,服務端收到第一個JOIN請求的時候會創建group,這個group的初始狀態為Empty
// 如果group都還不存在,就有了memberId,則認為是非法請求,直接拒絕。
groupManager.getGroup(groupId) match {
case None =>
// 這里group都還不存在的情況下,memberId自然是空的
if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID) {
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID))
} else {
// 初始狀態是EMPTY
val group = groupManager.addGroup(new GroupMetadata(groupId, initialState = Empty))
// 執行具體的加組操作
doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
case Some(group) =>
doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}讓我們進入doJoinGroup函數,看下里面的核心邏輯:
case Empty | Stable =>
// 初始狀態是EMPTY,添加member并且執行rebalance
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
// if the member id is unknown, register the member to the group
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
// ...
} else {
//...
} private def addMemberAndRebalance(rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
clientId: String,
clientHost: String,
protocolType: String,
protocols: List[(String, Array[Byte])],
group: GroupMetadata,
callback: JoinCallback) = {
// 根據clientID初始化memberID
val memberId = clientId + "-"> def add(member: MemberMetadata) {
if (members.isEmpty)
this.protocolType = Some(member.protocolType)
assert(groupId == member.groupId)
assert(this.protocolType.orNull == member.protocolType)
assert(supportsProtocols(member.protocols))
// coordinator選舉leader很簡單,就第一個發送join_group請求的那個member
if (leaderId.isEmpty)
leaderId = Some(member.memberId)
members.put(member.memberId, member)
}上面的代碼翻譯一下很簡單,就是新來了一個member,封裝一下,添加到這個group中,需要說一下的就是當組狀態是Empty的情況下,誰先連上誰就是leader。緊接著就準備rebalance:
private def maybePrepareRebalance(group: GroupMetadata) {
group.inLock {
if (group.canRebalance)
prepareRebalance(group)
}
}// 這里是傳入PreparingRebalance狀態,然后獲取到一個SET // 翻譯一下:就是只有這個SET(Stable, CompletingRebalance, Empty)里面的狀態,才能開啟rebalance def canRebalance = GroupMetadata.validPreviousStates(PreparingRebalance).contains(state) private val validPreviousStates: Map[GroupState, Set[GroupState]] = Map(Dead -> Set(Stable, PreparingRebalance, CompletingRebalance, Empty, Dead), CompletingRebalance -> Set(PreparingRebalance), Stable -> Set(CompletingRebalance), PreparingRebalance -> Set(Stable, CompletingRebalance, Empty), Empty -> Set(PreparingRebalance))
private def prepareRebalance(group: GroupMetadata) {
// if any members are awaiting sync, cancel their request and have them rejoin
if (group.is(CompletingRebalance))
resetAndPropagateAssignmentError(group, Errors.REBALANCE_IN_PROGRESS)
val delayedRebalance = if (group.is(Empty))
new InitialDelayedJoin(this,
joinPurgatory,
group,
groupConfig.groupInitialRebalanceDelayMs,// 默認3000ms,即3s
groupConfig.groupInitialRebalanceDelayMs,
max(group.rebalanceTimeoutMs - groupConfig.groupInitialRebalanceDelayMs, 0))
else
new DelayedJoin(this, group, group.rebalanceTimeoutMs)// 這里這個超時時間是客戶端的poll間隔,默認5分鐘
// 狀態機轉換:EMPTY -> PreparingRebalance
group.transitionTo(PreparingRebalance)
// rebalance開始標志日志
info(s"Preparing to rebalance group ${group.groupId} with old generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
// 加入時間輪
val groupKey = GroupKey(group.groupId)
joinPurgatory.tryCompleteElseWatch(delayedRebalance, Seq(groupKey))
}上面這段代碼有兩個關鍵點,一個是判斷當前能否進入rebalance過程,可以看到只有(Stable, CompletingRebalance, Empty)里面的狀態,才能開啟rebalance,而最開始來到第一個member的時候,組的狀態是Empty顯然是能進來的,但是近來之后就給轉換為了PreparingRebalance狀態,那么后續的member發送JOIN請求過來之后就進不來了,就只能設置個回調后一直等。
那么要等到什么時候呢?第二段代碼寫的很清楚就是等待延時任務超時,這個延時任務創建是根據當前狀態來判斷的,如果是Empty就創建一個InitialDelayedJoin延時任務,超時時間是3s;如果不是Empty就創建一個DelayedJoin,超時時間默認是5min。看,源碼出真知,這就是JOIN階段等待member的代碼實現。
這里需要補充一下,為什么Empty的狀態下要等待3s呢?這其實是一個優化,主要就是優化多消費者同時連入的情況。舉個栗子,10個消費者都能在3s內啟動然后練上,如果你等著3s時間那么一次rebalance過程就搞定了,如果你不等,那么就意味著來一個就又要開啟一次rebalance,一共要進行10次rebalance,這個耗時就比較長了。具體的細節可以查看:https://www.cnblogs.com/huxi2b/p/6815797.html
另外就是,為什么狀態不是Empty的時候就延時5分鐘呢?這個其實上面就回答了,要等待原來消費組內在線的消費者發送JOIN請求,這個也是rebalance過程耗時劣化的主要原因。
接下來我們看看這兩個延時任務,在超時的時候分別都會做些啥,首先是InitialDelayedJoin:
/**
* Delayed rebalance operation that is added to the purgatory when a group is transitioning from
* Empty to PreparingRebalance
*
* When onComplete is triggered we check if any new members have been added and if there is still time remaining
* before the rebalance timeout. If both are true we then schedule a further delay. Otherwise we complete the
* rebalance.
*/
private[group] class InitialDelayedJoin(coordinator: GroupCoordinator,
purgatory: DelayedOperationPurgatory[DelayedJoin],
group: GroupMetadata,
configuredRebalanceDelay: Int,
delayMs: Int,
remainingMs: Int) extends DelayedJoin(coordinator, group, delayMs) {
// 這里寫死是false,是為了在tryComplete的時候不被完成
override def tryComplete(): Boolean = false
override def onComplete(): Unit = {
// 延時任務處理
group.inLock {
// newMemberAdded是后面有新的member加進來就會是true
// remainingMs第一次創建該延時任務的時候就是3s。
// 所以這個條件在第一次的時候都是成立的
if (group.newMemberAdded && remainingMs != 0) {
group.newMemberAdded = false
val delay = min(configuredRebalanceDelay, remainingMs)
// 最新計算的remaining恒等于0,其實本質上就是3-3=0,
// 所以哪怕這里是新創建了一個InitialDelayedJoin,這個任務的超時時間就是下一刻
// 這么寫的目的其實就是相當于去完成這個延時任務
val remaining = max(remainingMs - delayMs, 0)
purgatory.tryCompleteElseWatch(new InitialDelayedJoin(coordinator,
purgatory,
group,
configuredRebalanceDelay,
delay,
remaining
), Seq(GroupKey(group.groupId)))
} else
// 如果沒有新的member加入,直接調用父類的函數
// 完成JOIN階段
super.onComplete()
}
}
}大意我都寫在注釋里面了,其實就是等待3s,然后完了之后調用父類的函數完成整個JOIN階段,不過不聯系上下文去看,還是挺費勁的,對了看這個需要對時間輪源碼有了解,正好我前面有寫,大家如果有什么不清楚的可以去看下。
接著看下DelayedJoin超時后會干嘛:
/**
* Delayed rebalance operations that are added to the purgatory when group is preparing for rebalance
*
* Whenever a join-group request is received, check if all known group members have requested
* to re-join the group; if yes, complete this operation to proceed rebalance.
*
* When the operation has expired, any known members that have not requested to re-join
* the group are marked as failed, and complete this operation to proceed rebalance with
* the rest of the group.
*/
private[group] class DelayedJoin(coordinator: GroupCoordinator,
group: GroupMetadata,
rebalanceTimeout: Long) extends DelayedOperation(rebalanceTimeout, Some(group.lock)) {
override def tryComplete(): Boolean = coordinator.tryCompleteJoin(group, forceComplete _)
override def onExpiration() = coordinator.onExpireJoin()
override def onComplete() = coordinator.onCompleteJoin(group)
}
// 超時之后啥也沒干,哈哈,因為確實不用做啥,置空就好了
// 核心是onComplete函數和tryComplete函數
def onExpireJoin() {
// TODO: add metrics for restabilize timeouts
} def tryCompleteJoin(group: GroupMetadata, forceComplete: () => Boolean) = {
group.inLock {
if (group.notYetRejoinedMembers.isEmpty)
forceComplete()
else false
}
}
def notYetRejoinedMembers = members.values.filter(_.awaitingJoinCallback == null).toList
def forceComplete(): Boolean = {
if (completed.compareAndSet(false, true)) {
// cancel the timeout timer
cancel()
onComplete()
true
} else {
false
}
} def onCompleteJoin(group: GroupMetadata) {
group.inLock {
// remove any members who haven't joined the group yet
// 如果組內成員依舊沒能連上,那么就刪除它,接收當前JOIN階段
group.notYetRejoinedMembers.foreach { failedMember =>
group.remove(failedMember.memberId)
// TODO: cut the socket connection to the client
}
if (!group.is(Dead)) {
// 狀態機流轉 : preparingRebalancing -> CompletingRebalance
group.initNextGeneration()
if (group.is(Empty)) {
info(s"Group ${group.groupId} with generation ${group.generationId} is now empty " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
groupManager.storeGroup(group, Map.empty, error => {
if (error != Errors.NONE) {
// we failed to write the empty group metadata. If the broker fails before another rebalance,
// the previous generation written to the log will become active again (and most likely timeout).
// This should be safe since there are no active members in an empty generation, so we just warn.
warn(s"Failed to write empty metadata for group ${group.groupId}: ${error.message}")
}
})
} else {
// JOIN階段標志結束日志
info(s"Stabilized group ${group.groupId} generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
// trigger the awaiting join group response callback for all the members after rebalancing
for (member <- group.allMemberMetadata) {
assert(member.awaitingJoinCallback != null)
val joinResult = JoinGroupResult(
// 如果是leader 就返回member列表及其元數據信息
members = if (group.isLeader(member.memberId)) {
group.currentMemberMetadata
} else {
Map.empty
},
memberId = member.memberId,
generationId = group.generationId,
subProtocol = group.protocolOrNull,
leaderId = group.leaderOrNull,
error = Errors.NONE)
member.awaitingJoinCallback(joinResult)
member.awaitingJoinCallback = null
completeAndScheduleNextHeartbeatExpiration(group, member)
}
}
}
}
}上面這一串代碼有幾個要點,首先,這個任務超時的時候是啥也不干的,為什么呢?這里要了解時間輪的機制,代碼也在上面,當一個任務超時的時候,時間輪強制執行對應任務的onComplete函數,然后執行onExpiration函數,其實onExpiration函數對于這個延時任務來說是沒有意義的,并不需要做什么,打日志都懶得打。
第二點就是這個任務onComplete什么時候會被調用呢?難道就只能等待5分鐘超時才能被調用嗎?那不是每一次rebalance都必須要等待5分鐘?當然不可能啦,這里就需要先看下tryComplete函數的內容,發現這個內容會去檢查還沒連上的member,如果發現到期了,就強制完成。那么我們看下這tryComplete是在哪兒被調用的?這里需要插入一點之前沒貼全的代碼,在doJoinGroup函數中的而最后一段:
if (group.is(PreparingRebalance)) joinPurgatory.checkAndComplete(GroupKey(group.groupId))
這段代碼非常關鍵,當當前狀態是PreparingRebalance的時候,會嘗試去完成當前的延時任務,最終調用的代碼:
private[server] def maybeTryComplete(): Boolean = {
var retry = false
var done = false
do {
if (lock.tryLock()) {
try {
tryCompletePending.set(false)
done = tryComplete()
} finally {
lock.unlock()
}
// While we were holding the lock, another thread may have invoked `maybeTryComplete` and set
// `tryCompletePending`. In this case we should retry.
retry = tryCompletePending.get()
} else {
// Another thread is holding the lock. If `tryCompletePending` is already set and this thread failed to
// acquire the lock, then the thread that is holding the lock is guaranteed to see the flag and retry.
// Otherwise, we should set the flag and retry on this thread since the thread holding the lock may have
// released the lock and returned by the time the flag is set.
retry = !tryCompletePending.getAndSet(true)
}
} while (!isCompleted && retry)
done
}就是上面的tryComplete函數,最終會調用到DelayedJoin中的tryComplete函數,什么意思呢?已經很明顯了,每來一個JOIN請求的時候,如果處于PreparingRebalance階段,都會去檢查一下group中原來的成員是否已經到齊了,到齊了就立刻結束JOIN階段往后走。看到這兒,回頭看下InitialDelayedJoin這個延時任務的tryComplete為什么就默認實現了個false呢?也明白了,就是初始化延時任務的時候不讓你嘗試完成,我就等3s,不需要你們來觸發我提前完成。
以上,我們就看完了整個服務端的JOIN請求處理過程,其實主要核心就是這兩個延時任務,如果不聯系上下文,不了解時間輪機制,看起來確實費勁。接下來就看下SYNC階段是如何處理的。
直接看下面的核心源碼邏輯:
private def doSyncGroup(group: GroupMetadata,
generationId: Int,
memberId: String,
groupAssignment: Map[String, Array[Byte]],
responseCallback: SyncCallback) {
group.inLock {
if (!group.has(memberId)) {
responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID)
} else if (generationId != group.generationId) {
responseCallback(Array.empty, Errors.ILLEGAL_GENERATION)
} else {
group.currentState match {
case Empty | Dead =>
responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID)
case PreparingRebalance =>
responseCallback(Array.empty, Errors.REBALANCE_IN_PROGRESS)
// 只有group處于compeletingRebalance狀態下才會被處理
// 其余狀態都是錯誤的狀態
case CompletingRebalance =>
// 給當前member設置回調,之后就啥也不干,也不返回
// 等到leader的分區方案就緒后,才會被返回。
group.get(memberId).awaitingSyncCallback = responseCallback
// if this is the leader, then we can attempt to persist state and transition to stable
// 只有收到leader的SYNC才會被處理,并進行狀態機流轉
if (group.isLeader(memberId)) {
info(s"Assignment received from leader for group ${group.groupId} for generation ${group.generationId}")
// fill any missing members with an empty assignment
val missing = group.allMembers -- groupAssignment.keySet
val assignment = groupAssignment ++ missing.map(_ -> Array.empty[Byte]).toMap
groupManager.storeGroup(group, assignment, (error: Errors) => {
group.inLock {
// another member may have joined the group while we were awaiting this callback,
// so we must ensure we are still in the CompletingRebalance state and the same generation
// when it gets invoked. if we have transitioned to another state, then do nothing
if (group.is(CompletingRebalance) && generationId == group.generationId) {
if (error != Errors.NONE) {
resetAndPropagateAssignmentError(group, error)
maybePrepareRebalance(group)
} else {
setAndPropagateAssignment(group, assignment)
// 狀態機流轉:CompletingRebalance -> Stable
group.transitionTo(Stable)
}
}
}
})
}
// 如果已經處于stable狀態,說明leader已經把分區分配方案傳上來了
// 那么直接從group的元數據里面返回對應的方案就好了
case Stable =>
// if the group is stable, we just return the current assignment
val memberMetadata = group.get(memberId)
responseCallback(memberMetadata.assignment, Errors.NONE)
// 開啟心跳檢測
completeAndScheduleNextHeartbeatExpiration(group, group.get(memberId))
}
}
}
}我們可能對上面的代碼案處理會有一個疑問,為什么只有leader的SYNC請求才會被處理呢?要是其他consumer比leader早上來了難道就卡這兒不管了?不像JOIN階段那樣加入個時間輪設置個最大超時時間?這要是leader一直不發送SNYC請求,那不就所有成員都這兒干等著,無限等待了?
我們一個個來回答,首先,我們看上面的代碼,每個請求過來第一件事是先設置回調,然后才去卡住等著,直到leader把分區分配方案通過SYNC請求帶上來。
第二個問題,如果其他consumer比leader早到了就這么干等著嗎?是的,沒錯,代碼就是這么寫的。
第三個問題,為什么不設置個最大超時時間啥的?我們可以看下客戶端的代碼,一旦開啟rebalance之后,就只會進行相關請求的收發,意味著leader在收到JOIN階段的返回后,中間不會有任何業務代碼的影響,直接就是分配完分區然后發送SYNC請求;這就意味著leader的JOIN響應和SYNC請求之間理論上是不存在阻塞的,因此就可以不用設置超時,就不用加入時間輪了。
第四個問題,leader一直不發送SYNC請求就干等著?是的,代碼就是這么寫的。不過你想想,哪些情況能讓leader一直不發送SYNC請求?我能想到的就是GC/leader宕機了,無論是哪種情況都會因為心跳線程出了問題被服務端檢測到,因此在對應的心跳任務超時后重新開啟下一輪的rebalance。哪怕是GC很長時間之后恢復了繼續發SYNC請求過來,也會因為generation不匹配而得到錯誤返回開啟下一輪rebalance。
最后再看下leader到了之后會具體做啥:
private def setAndPropagateAssignment(group: GroupMetadata, assignment: Map[String, Array[Byte]]) {
assert(group.is(CompletingRebalance))
// 給每個member的分配方案賦值
group.allMemberMetadata.foreach(member => member.assignment = assignment(member.memberId))
// 在整個group中傳播這個分配方案
propagateAssignment(group, Errors.NONE)
}
private def propagateAssignment(group: GroupMetadata, error: Errors) {
// 遍歷
// 如果是follower比leader先到SYNC請求
// 那么就只會設置個callback,就啥都不干了,也不會返回
// 直到leader帶著分配方案來了以后,把狀態更改為stable之后,才會遍歷
// 看看有哪些member已經發送了請求過來,設置了callback,然后一次性給他們返回回去對應的分區方案
// 所以這個名稱叫做【傳播分配方案】
// 真是絕妙
for (member <- group.allMemberMetadata) {
if (member.awaitingSyncCallback != null) {
// 通過回調告訴member對應的分配方案
member.awaitingSyncCallback(member.assignment, error)
member.awaitingSyncCallback = null
// reset the session timeout for members after propagating the member's assignment.
// This is because if any member's session expired while we were still awaiting either
// the leader sync group or the storage callback, its expiration will be ignored and no
// future heartbeat expectations will not be scheduled.
completeAndScheduleNextHeartbeatExpiration(group, member)
}
}
}看,最開始設置的回調,在收到leader請求時候,起了作用;會被挨個遍歷后響應具體的分區分配方案,另外就是kafka里面的命名都很準確。
SYNC階段簡單說起來就是等待leader把分區分配方案傳上來,如果member先到就設置個回調先等著,如果leader先到,就直接把分區分配方案存到group的元數據中,然后狀態修改為Stable,后續其他member來的SYNC請求就直接從group的元數據取分區分配方案,然后自己消費去了。
八、線上如何排查rebalance問題?
看完理論,讓我們來看下線上問題怎么排查rebalance問題。 rebalance有哪些問題呢?我們來整理一下:
為什么會rebalance呢?是什么引起的?能定位到是哪個客戶端嘛?
rebalance耗時了多久?為什么會劣化? 常見的就上面兩個問題,我們按個來回答。
首先,為什么會rebalance,這個就三種情況,分區信息變化、客戶端變化、coordinator變化。
一般線上常見的就是客戶端變化,那么客戶端有哪些可能的變化呢?——新增成員,減少成員。
新增成員怎么看呢?很簡單嘛,找到coordinator,然后去kafka-request.log里面搜:cat kafka-request.log |grep -i find | grep -i ${group.id} 不過一般FIND_COORDINATOR請求的處理時間都小于10ms,所以只能打開debug日志才能看到。一般這種讓客戶自己看,對應的時間點是不是有啟動kafka-consumer就行了,其實也不常見,這種情況。畢竟很少有人頻繁開啟關閉消費者,就算是有也是不好的業務使用方式。
減少成員呢?又分為兩種:心跳超時,poll間隔超過配置 心跳超時的標識日志:
def onExpireHeartbeat(group: GroupMetadata, member: MemberMetadata, heartbeatDeadline: Long) {
group.inLock {
if (!shouldKeepMemberAlive(member, heartbeatDeadline)) {
// 標識日志
info(s"Member ${member.memberId} in group ${group.groupId} has failed, removing it from the group")
removeMemberAndUpdateGroup(group, member)
}
}
}很遺憾poll間隔超時,在1.1.0版本的info級別下并沒有可查找的日志,檢測poll時間間隔超時的是對應客戶端的心跳線程,在檢測到超過配置后就會主動leaveGroup從而觸發rebalance,而這個請求在服務端依舊沒有info級別的請求,因此,要判斷是poll間隔超時引起的rebalance,就只能看下有沒有上面心跳超時的日志,如果沒有可能就是因為這個原因造成的。目前大多數的rebalance都是因為這個原因造成的,而且這個原因引發的rebalance同時還可能伴隨著很長的rebalance耗時。
來看下服務端是如何做poll間隔超時的呢?
} else if (heartbeat.pollTimeoutExpired(now)) {
// the poll timeout has expired, which means that the foreground thread has stalled
// in between calls to poll(), so we explicitly leave the group.
maybeLeaveGroup();
}
public boolean sessionTimeoutExpired(long now) {
return now - Math.max(lastSessionReset, lastHeartbeatReceive) > sessionTimeout;
}
public synchronized void maybeLeaveGroup() {
if (!coordinatorUnknown() && state != MemberState.UNJOINED && generation != Generation.NO_GENERATION) {
// this is a minimal effort attempt to leave the group. we do not
// attempt any resending if the request fails or times out.
log.debug("Sending LeaveGroup request to coordinator {}", coordinator);
LeaveGroupRequest.Builder request =
new LeaveGroupRequest.Builder(groupId, generation.memberId);
client.send(coordinator, request)
.compose(new LeaveGroupResponseHandler());
client.pollNoWakeup();
}
resetGeneration();
}總結一下,怎么定位rebalance的問題,就是找標志日志,然后排除法,實在不行了就打開debug日志。
接著看第二個問題,rebalance一次的時間耗費了多久?為什么會劣化到幾分鐘? 因為整個rebalance過程是線性的過程,就是狀態按照請求順序流轉,因此呢找到對應的標志日志就好啦。 開啟的標志日志:
// rebalance開始標志日志
info(s"Preparing to rebalance group ${group.groupId} with old generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")結束的兩種標識日志:這兩種結束日志都行,因為都差不多代表著rebalance過程完成,原因在上面已經講的很清楚了。
// JOIN階段標志結束日志
info(s"Stabilized group ${group.groupId} generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
// SYNC階段結束日志
info(s"Assignment received from leader for group ${group.groupId} for generation ${group.generationId}")那么如何統計整個rebalance過程的時間呢? 顯而易見,結束時間 - 開始時間呀。
知道是怎么什么原因開啟了rebalance之后,該怎么定位業務問題呢? 心跳超時:因為心跳線程是守護線程,一般都是因為客戶端的機器負載太高導致心跳現場無法獲取到CPU導致的。
poll間隔超過配置:顯然嘛,就是poll出來數據之后,進行業務處理的時候太慢了,建議根據業務優化消費邏輯,改成多線程消費或者異步消費。
這個很簡單,我們想一下,與這個group有關的元數據全部都在coordinator那里,哪些請求會與coordinator交互呢?HEARTBEAT/OFFSET_COMMIT嘛,就這倆,那么其實正常的member都是靠這兩個請求來感知到自己要去進行rebalance的,我們分別來看下。
首先是HEARTBEAT請求,每次都會帶上當前消費組的generation值,也就是紀元值,要是服務端rebalance已經完成了,紀元值+1,那么此時就會發現自己沒匹配上,然后緊接著就去設置自己的RejoinNeeded的標識,在下一輪poll 的時候就會去開啟rebalance。
如果說是rebalance還沒完成,那就更簡單了,發現group的狀態不是stable,直接就返回對應的錯誤,然后設置標識,加入到rebalance過程中。
服務端源碼:
case Some(group) =>
group.inLock {
group.currentState match {
case Dead =>
// if the group is marked as dead, it means some other thread has just removed the group
// from the coordinator metadata; this is likely that the group has migrated to some other
// coordinator OR the group is in a transient unstable phase. Let the member retry
// joining without the specified member id,
responseCallback(Errors.UNKNOWN_MEMBER_ID)
case Empty =>
responseCallback(Errors.UNKNOWN_MEMBER_ID)
case CompletingRebalance =>
if (!group.has(memberId))
responseCallback(Errors.UNKNOWN_MEMBER_ID)
else
responseCallback(Errors.REBALANCE_IN_PROGRESS)
case PreparingRebalance =>
if (!group.has(memberId)) {
responseCallback(Errors.UNKNOWN_MEMBER_ID)
} else if (generationId != group.generationId) {
responseCallback(Errors.ILLEGAL_GENERATION)
} else {
val member = group.get(memberId)
completeAndScheduleNextHeartbeatExpiration(group, member)
responseCallback(Errors.REBALANCE_IN_PROGRESS)
}
case Stable =>
if (!group.has(memberId)) {
responseCallback(Errors.UNKNOWN_MEMBER_ID)
// 紀元切換
} else if (generationId != group.generationId) {
responseCallback(Errors.ILLEGAL_GENERATION)
} else {
val member = group.get(memberId)
// 完成上次的延時,新建新的延時任務
completeAndScheduleNextHeartbeatExpiration(group, member)
// 回調響應
responseCallback(Errors.NONE)
}客戶端源碼:
private class HeartbeatResponseHandler extends CoordinatorResponseHandler<HeartbeatResponse, Void> {
@Override
public void handle(HeartbeatResponse heartbeatResponse, RequestFuture<Void> future) {
sensors.heartbeatLatency.record(response.requestLatencyMs());
Errors error = heartbeatResponse.error();
if (error == Errors.NONE) {
log.debug("Received successful Heartbeat response");
future.complete(null);
} else if (error == Errors.COORDINATOR_NOT_AVAILABLE
|| error == Errors.NOT_COORDINATOR) {
log.debug("Attempt to heartbeat since coordinator {} is either not started or not valid.",
coordinator());
markCoordinatorUnknown();
future.raise(error);
} else if (error == Errors.REBALANCE_IN_PROGRESS) {
log.debug("Attempt to heartbeat failed since group is rebalancing");
requestRejoin();
future.raise(Errors.REBALANCE_IN_PROGRESS);
} else if (error == Errors.ILLEGAL_GENERATION) {
log.debug("Attempt to heartbeat failed since generation {} is not current", generation.generationId);
resetGeneration();
future.raise(Errors.ILLEGAL_GENERATION);
} else if (error == Errors.UNKNOWN_MEMBER_ID) {
log.debug("Attempt to heartbeat failed for since member id {} is not valid.", generation.memberId);
resetGeneration();
future.raise(Errors.UNKNOWN_MEMBER_ID);
} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
future.raise(new GroupAuthorizationException(groupId));
} else {
future.raise(new KafkaException("Unexpected error in heartbeat response: " + error.message()));
}
}
}
protected synchronized void requestRejoin() {
this.rejoinNeeded = true;
}所以我們客戶端看到這種異常,就知道怎么回事了,就是我在rebalance的過程中,或者已經完成了,客戶端的紀元不對。
REBALANCE_IN_PROGRESS(27, "The group is rebalancing, so a rejoin is needed.",
new ApiExceptionBuilder() {
@Override
public ApiException build(String message) {
return new RebalanceInProgressException(message);
}
}),
ILLEGAL_GENERATION(22, "Specified group generation id is not valid.",
new ApiExceptionBuilder() {
@Override
public ApiException build(String message) {
return new IllegalGenerationException(message);
}
}),我們再看OFFSET_COMMIT請求,其實和HEARTBEAT請求是基本一致的。
服務端:
group.inLock {
if (group.is(Dead)) {
responseCallback(offsetMetadata.mapValues(_ => Errors.UNKNOWN_MEMBER_ID))
} else if ((generationId < 0 && group.is(Empty)) || (producerId != NO_PRODUCER_ID)) {
// The group is only using Kafka to store offsets.
// Also, for transactional offset commits we don't need to validate group membership and the generation.
groupManager.storeOffsets(group, memberId, offsetMetadata, responseCallback, producerId, producerEpoch)
} else if (group.is(CompletingRebalance)) {
responseCallback(offsetMetadata.mapValues(_ => Errors.REBALANCE_IN_PROGRESS))
} else if (!group.has(memberId)) {
responseCallback(offsetMetadata.mapValues(_ => Errors.UNKNOWN_MEMBER_ID))
} else if (generationId != group.generationId) {
responseCallback(offsetMetadata.mapValues(_ => Errors.ILLEGAL_GENERATION))
} else {
val member = group.get(memberId)
completeAndScheduleNextHeartbeatExpiration(group, member)
groupManager.storeOffsets(group, memberId, offsetMetadata, responseCallback)
}
}
}客戶端:
else if (error == Errors.UNKNOWN_MEMBER_ID
|| error == Errors.ILLEGAL_GENERATION
|| error == Errors.REBALANCE_IN_PROGRESS) {
// need to re-join group
resetGeneration();
future.raise(new CommitFailedException());
return;
/**
* Reset the generation and memberId because we have fallen out of the group.
*/
protected synchronized void resetGeneration() {
this.generation = Generation.NO_GENERATION;
this.rejoinNeeded = true;
this.state = MemberState.UNJOINED;
}從源碼我們可以看到,客戶端在感知rebalance主要通過兩個機制,一個是狀態,一個是紀元;狀態生效于rebalance過程中,紀元生效于rebalance的JOIN階段結束后。
與coordinator交互的這兩個請求都會帶上自己的紀元信息,在服務端處理前都會校驗一下狀態已經紀元信息,一旦不對,就告訴客戶端你需要rebalance了。
首先明確下,rebalance會有什么影響?引用JVM的術語來說,就是STOP THE WORLD。
一旦開啟rebalance過程,在消費者進入JOIN階段后就無法再繼續消費,就是整個group的成員全部STW,所以對業務的影響還是很大的。
“KAFKA中rebalance是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





