溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Linux中內核調度器如何初始化,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
在分析調度器的相關代碼之前,需要先了解一下調度器涉及的核心數據(結構)以及它們的作用
內核會為每個 CPU 創建一個運行隊列,系統中的就緒態(處于 Running 狀態的)進程(task)都會被組織到內核運行隊列上,然后根據相應的策略,調度運行隊列上的進程到 CPU 上執行。
內核將調度策略(sched_class)進行了高度的抽象,形成調度類(sched_class)。通過調度類可以將調度器的公共代碼(機制)和具體不同調度類提供的調度策略進行充分解耦,是典型的 OO(面向對象)的思想。通過這樣的設計,可以讓內核調度器極具擴展性,開發者通過很少的代碼(基本不需改動公共代碼)就可以增加一個新的調度類,從而實現一種全新的調度器(類),比如,deadline調度類就是3.x中新增的,從代碼層面看只是增加了 dl_sched_class 這個結構體的相關實現函數,就很方便的添加了一個新的實時調度類型。
目前的5.4內核,有5種調度類,優先級從高到底分布如下:
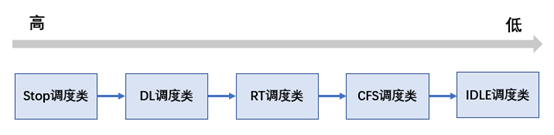
優先級最高的調度類,它與 idle_sched_class 一樣,是一個專用的調度類型(除了 migration 線程之外,其他的 task 都是不能或者說不應該被設置為 stop 調度類)。該調度類專用于實現類似 active balance 或 stop machine 等依賴于 migration 線程執行的“緊急”任務。
deadline 調度類的優先級僅次于 stop 調度類,它是一種基于 EDL 算法實現的實時調度器(或者說調度策略)。
rt 調度類的優先級要低于 dl 調度類,是一種基于優先級實現的實時調度器。
CFS 調度器的優先級要低于上面的三個調度類,它是基于公平調度思想而設計的調度類型,是 Linux 內核的默認調度類。
idle 調度類型是 swapper 線程,主要是讓 swapper 線程接管 CPU,通過 cpuidle/nohz 等框架讓 CPU 進入節能狀態。
調度域是在2.6里引入內核的,通過多級調度域引入,能夠讓調度器更好的適應硬件的物理特性(調度域可以更好的適配 CPU 多級緩存以及 NUMA 物理特性對負載均衡所帶來的挑戰),實現更好的調度性能(sched_domain 是為 CFS 調度類負載均衡而開發的機制)。
調度組是與調度域一起被引入內核的,它會與調度域一起配合,協助 CFS 調度器完成多核間的負載均衡。
根域主要是負責實時調度類(包括 dl 和 rt 調度類)負載均衡而設計的數據結構,協助 dl 和 rt 調度類完成實時任務的合理調度。在沒有用 isolate 或者 cpuset cgroup 修改調度域的時候,那么默認情況下所有的CPU都會處于同一個根域。
為了能夠對系統里的資源進行更精細的控制,內核引入了 cgroup 機制來進行資源控制。而 group_sched 就是 cpu cgroup 的底層實現機制,通過 cpu cgroup 我們可以將一些進程設置為一個 cgroup,并且通過 cpu cgroup 的控制接口配置相應的帶寬和 share 等參數,這樣我們就可以按照 group 為單位,對 CPU 資源進行精細的控制。
下面進入正題,開始分析內核調度器的初始化流程,希望能通過這里的分析,讓大家了解:
1、運行隊列是如何被初始化的
2、組調度是如何與 rq 關聯起來的(只有關聯之后才能通過 group_sched 進行組調度)
3、CFS 軟中斷 SCHED_SOFTIRQ 注冊
調度初始化(sched_init)
start_kernel
|----setup_arch
|----build_all_zonelists
|----mm_init
|----sched_init 調度初始化
調度初始化位于 start_kernel 相對靠后的位置,這個時候內存初始化已經完成,所以可以看到 sched_init 里面已經可以調用 kzmalloc 等內存申請函數了。
sched_init 需要為每個 CPU 初始化運行隊列(rq)、dl/rt 的全局默認帶寬、各個調度類的運行隊列以及 CFS 軟中斷注冊等工作。
接下來我們看看 sched_init 的具體實現(省略了部分代碼):
void __init sched_init(void)
{
unsigned long ptr = 0;
int i;
/*
* 初始化全局默認的rt和dl的CPU帶寬控制數據結構
*
* 這里的rt_bandwidth和dl_bandwidth是用來控制全局的DL和RT的使用帶寬,防止實時進程
* CPU使用過多,從而導致普通的CFS進程出現饑餓的情況
*/
init_rt_bandwidth(&def_rt_bandwidth, global_rt_period(), global_rt_runtime());
init_dl_bandwidth(&def_dl_bandwidth, global_rt_period(), global_rt_runtime());
#ifdef CONFIG_SMP
/*
* 初始化默認的根域
*
* 根域是dl/rt等實時進程做全局均衡的重要數據結構,以rt為例
* root_domain->cpupri 是這個根域范圍內每個CPU上運行的RT任務的最高優先級,以及
* 各個優先級任務在CPU上的分布情況,通過cpupri的數據,那么在rt enqueue/dequeue
* 的時候,rt調度器就可以根據這個rt任務分布情況來保證高優先級的任務得到優先
* 運行
*/
init_defrootdomain();
#endif
#ifdef CONFIG_RT_GROUP_SCHED
/*
* 如果內核支持rt組調度(RT_GROUP_SCHED), 那么對RT任務的帶寬控制將可以用cgroup
* 的粒度來控制每個group里rt任務的CPU帶寬使用情況
*
* RT_GROUP_SCHED可以讓rt任務以cpu cgroup的形式來整體控制帶寬
* 這樣可以為RT帶寬控制帶來更大的靈活性(沒有RT_GROUP_SCHED的時候,只能控制RT的全局
* 帶寬使用,不能通過指定group的形式控制部分RT進程帶寬)
*/
init_rt_bandwidth(&root_task_group.rt_bandwidth,
global_rt_period(), global_rt_runtime());
#endif /* CONFIG_RT_GROUP_SCHED */
/* 為每個CPU初始化它的運行隊列 */
for_each_possible_cpu(i) {
struct rq *rq;
rq = cpu_rq(i);
raw_spin_lock_init(&rq->lock);
/*
* 初始化rq上cfs/rt/dl的運行隊列
* 每個調度類型在rq上都有各自的運行隊列,每個調度類都是各自管理自己的進程
* 在pick_next_task()的時候,內核根據調度類優先級的順序,從高到底選擇任務
* 這樣就保證了高優先級調度類任務會優先得到運行
*
* stop和idle是特殊的調度類型,是為專門的目的而設計的調度類,并不允許用戶
* 創建相應類型的進程,所以內核也沒有在rq里設計對應的運行隊列
*/
init_cfs_rq(&rq->cfs);
init_rt_rq(&rq->rt);
init_dl_rq(&rq->dl);
#ifdef CONFIG_FAIR_GROUP_SCHED
/*
* CFS的組調度(group_sched),可以通過cpu cgroup來對CFS進行進行控制
* 可以通過cpu.shares來提供group之間的CPU比例控制(讓不同的cgroup按照對應
* 的比例來分享CPU),也可以通過cpu.cfs_quota_us來進行配額設定(與RT的
* 帶寬控制類似)。CFS group_sched帶寬控制是容器實現的基礎底層技術之一
*
* root_task_group 是默認的根task_group,其他的cpu cgroup都會以它做為
* parent或者ancestor。這里的初始化將root_task_group與rq的cfs運行隊列
* 關聯起來,這里做的很有意思,直接將root_task_group->cfs_rq[cpu] = &rq->cfs
* 這樣在cpu cgroup根下的進程或者cgroup tg的sched_entity會直接加入到rq->cfs
* 隊列里,可以減少一層查找開銷。
*/
root_task_group.shares = ROOT_TASK_GROUP_LOAD;
INIT_LIST_HEAD(&rq->leaf_cfs_rq_list);
rq->tmp_alone_branch = &rq->leaf_cfs_rq_list;
init_cfs_bandwidth(&root_task_group.cfs_bandwidth);
init_tg_cfs_entry(&root_task_group, &rq->cfs, NULL, i, NULL);
#endif /* CONFIG_FAIR_GROUP_SCHED */
rq->rt.rt_runtime = def_rt_bandwidth.rt_runtime;
#ifdef CONFIG_RT_GROUP_SCHED
/* 初始化rq上的rt運行隊列,與上面的CFS的組調度初始化類似 */
init_tg_rt_entry(&root_task_group, &rq->rt, NULL, i, NULL);
#endif
#ifdef CONFIG_SMP
/*
* 這里將rq與默認的def_root_domain進行關聯,如果是SMP系統,那么后面
* 在sched_init_smp的時候,內核會創建新的root_domain,然后替換這里
* def_root_domain
*/
rq_attach_root(rq, &def_root_domain);
#endif /* CONFIG_SMP */
}
/*
* 注冊CFS的SCHED_SOFTIRQ軟中斷服務函數
* 這個軟中斷住要是周期性負載均衡以及nohz idle load balance而準備的
*/
init_sched_fair_class();
scheduler_running = 1;
}start_kernel
|----rest_init
|----kernel_init
|----kernel_init_freeable
|----smp_init
|----sched_init_smp
|---- sched_init_numa
|---- sched_init_domains
|---- build_sched_domains
多核調度初始化主要是完成調度域/調度組的初始化(當然根域也會做,但相對而言,根域的初始化會比較簡單)。
Linux 是一個可以跑在多種芯片架構,多種內存架構(UMA/NUMA)上運行的操作系統,所以 Linu x需要能夠適配多種物理結構,所以它的調度域設計與實現也是相對比較復雜的。
在講具體的調度域初始化代碼之前,我們需要先了解調度域與物理拓撲結構之間的關系(因為調度域的設計是與物理拓撲結構息息相關的,如果不理解物理拓撲結構,那么就沒有辦法真正理解調度域的實現)
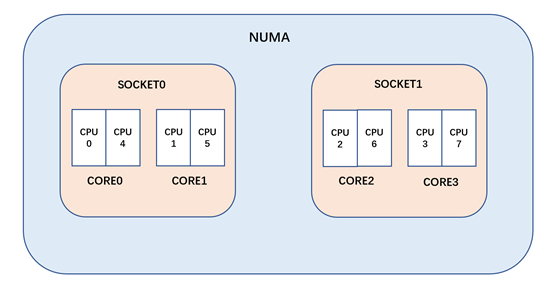
我們假設一個計算機系統(與 intel 芯片類似,但縮小 CPU 核心數,以方便表示):
雙 socket 的計算機系統,每個 socket 都是2核4線程組成,那么這個計算機系統就應該是一個4核8線程的 NUMA 系統(上面只是 intel 的物理拓撲結構,而像 AMD ZEN 架構采用了 chiplet 的設計,它在 MC 與 NUMA 域之間會多一層 DIE 域)。
如上圖的 CORE0,2個超線程構成了 SMT 域。對于 intel cpu 而言,超線程共享了 L1 與 L2(甚至連 store buffe 都在一定程度上共享),所以 SMT 域之間互相遷移是沒有任何緩存熱度損失的
如上圖 CORE0 與 CORE1,他們位于同一個 SOCKET,屬于 MC 域。對于 intel cpu 而言,他們一般共享 LLC(一般是 L3),在這個域里進程遷移雖然會失去 L1 與 L2 的熱度,但 L3 的緩存熱度還是可以保持的
第三層(NUMA域):
如上圖的 SOCKET0 和 SOCKET1,它們之間的進程遷移會導致所有緩存熱度的損失,會有較大的開銷,所以 NUMA 域的遷移需要相對的謹慎。
正是由于這樣的硬件物理特性(不同層級的緩存熱度、NUMA 訪問延遲等硬件因素),所以內核抽象了 sched_domain 和 sched_group 來表示這樣的物理特性。在做負載均衡的時候,根據相應的調度域特性,做不同的調度策略(例如負載均衡的頻率、不平衡的因子以及喚醒選核邏輯等),從而在CPU 負載與緩存親和性上做更好的平衡。
接下來我們可以看看內核如何在上面的物理拓撲結構上建立調度域與調度組的

內核會根據物理拓撲結構建立對應層次的調度域,然后在每層調度域上再建立相應的調度組。調度域在做負載均衡,是在對應層次的調度域里找到負載最重的 busiest sg(sched_group),然后再判斷 buiest sg 與 local sg(但前 CPU 所在的調度組)的負載是否不均。如果存在負載不均的情況,則會從 buiest sg 里選擇 buisest cpu,然后進行2個 CPU 間的負載平衡。
SMT 域是最底層的調度域,可以看到每個超線程對就是一個 smt domain。smt domain 里有2個 sched_group,而每個 sched_group 則只會有一個CPU。所以 smt 域的負載均衡就是執行超線程間的進程遷移,這個負載均衡的時間最短,條件最寬松。
而對于不存在超線程的架構(或者說芯片沒有開啟超線程),那么最底層域就是MC域(這個時候就只有2層域,MC 與 NUMA)。這樣 MC 域里每個 CORE 都是一個 sched_group,內核在調度的時候也可以很好的適應這樣的場景。
MC 域則是 socket 上 CPU 所有的 CPU 組成,而其中每個 sg 則為上級 smt domain 的所有CPU構成。所以對于上圖而言,MC 的 sg 則由2個 CPU 組成。內核在 MC 域這樣設計,可以讓 CFS 調度類在喚醒負載均衡以及空閑負載均衡時,要求 MC 域的 sg 間需要均衡。
這個設計對于超線程來說很重要,我們在一些實際的業務里也可以觀察到這樣的情況。例如,我們有一項編解碼的業務,發現它在某些虛擬機里的測試數據較好,而在某些虛擬機里的測試數據較差。通過分析后發現,這是由于是否往虛擬機透傳超線程信息導致的。當我們向虛擬機透傳超線程信息后,虛擬機會形成2層調度域(SMT 與 MC域),而在喚醒負載均衡的時候,CFS 會傾向于將業務調度到空閑的 sg 上(即空閑的物理 CORE,而不是空閑的 CPU),這個時候業務在 CPU 利用率不高(沒有超過40%)的時候,可以更加充分的利用物理CORE的性能(還是老問題,一個物理CORE上的超線程對,它們同時運行 CPU 消耗型業務時,所獲得的性能增益只相當于單線程1.2倍左右。),從而獲得較好的性能增益。而如果沒有透傳超線程信息,那么虛擬機只有一層物理拓撲結構(MC域),那么由于業務很可能被調度通過一個物理 CORE 的超線程對上,這樣會導致系統無法充分利用物理CORE 的性能,從而導致業務性能偏低。
NUMA 域則是由系統里的所有 CPU 構成,SOCKET 上的所有 CPU 構成一個 sg,上圖的 NUMA 域由2個 sg 構成。NUMA 的 sg 之間需要有較大的不平衡時(并且這里的不平衡是 sg 級別的,即要 sg 上所有CPU負載總和與另外一個 sg 不平衡),才能進行跨 NUMA 的進程遷移(因為跨 NUMA 的遷移會導致 L1 L2 L3 的所有緩存熱度損失,以及可能引發更多的跨 NUMA 內存訪問,所以需要小心應對)。
從上面的介紹可以看到,通過 sched_domain 與 sched_group 的配合,內核能夠適配各種物理拓撲結構(是否開啟超線程、是否開啟使用 NUMA),高效的使用 CPU 資源。
/*
* Called by boot processor to activate the rest.
*
* 在SMP架構里,BSP需要將其他的非boot cp全部bring up
*/
void __init smp_init(void)
{
int num_nodes, num_cpus;
unsigned int cpu;
/* 為每個CPU創建其idle thread */
idle_threads_init();
/* 向內核注冊cpuhp線程 */
cpuhp_threads_init();
pr_info("Bringing up secondary CPUs ...\n");
/*
* FIXME: This should be done in userspace --RR
*
* 如果CPU沒有online,則用cpu_up將其bring up
*/
for_each_present_cpu(cpu) {
if (num_online_cpus() >= setup_max_cpus)
break;
if (!cpu_online(cpu))
cpu_up(cpu);
}
.............
}在真正開始 sched_init_smp 調度域初始化之前,需要先 bring up 所有非 boot cpu,保證這些 CPU 處于 ready 狀態,然后才能開始多核調度域的初始化。
那這里我們來看看多核調度初始化具體的代碼實現(如果沒有配置 CONFIG_SMP,那么則不會執行到這里的相關實現)
sched_init_numa() 是用來檢測系統里是否為 NUMA,如果是的則需要動態添加 NUMA 域。
/*
* Topology list, bottom-up.
*
* Linux默認的物理拓撲結構
*
* 這里只有三級物理拓撲結構,NUMA域是在sched_init_numa()自動檢測的
* 如果存在NUMA域,則會添加對應的NUMA調度域
*
* 注:這里默認的 default_topology 調度域可能會存在一些問題,例如
* 有的平臺不存在DIE域(intel平臺),那么就可能出現LLC與DIE域重疊的情況
* 所以內核會在調度域建立好后,在cpu_attach_domain()里掃描所有調度
* 如果存在調度重疊的情況,則會destroy_sched_domain對應的重疊調度域
*/
static struct sched_domain_topology_level default_topology[] = {
#ifdef CONFIG_SCHED_SMT
{ cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) },
#endif
#ifdef CONFIG_SCHED_MC
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
{ NULL, },
};Linux默認的物理拓撲結構
/*
* NUMA調度域初始化(根據硬件信息創建新的sched_domain_topology物理拓撲結構)
*
* 內核在默認情況下并不會主動添加NUMA topology,需要根據配置(如果開啟了NUMA)
* 如果開啟了NUMA,這里就要根據硬件拓撲信息來判斷是否需要添加
* sched_domain_topology_level 域(只有添加了這個域之后,內核才會在后面初始化
* sched_domain的時候創建NUMA DOMAIN)
*/
void sched_init_numa(void)
{
...................
/*
* 這里會根據distance檢查是否存在NUMA域(甚至存在多級NUMA域),然后根據
* 情況將其更新到物理拓撲結構里。后面的建立調度域的時候,就會這個新的
* 物理拓撲結構來建立新的調度域
*/
for (j = 1; j < level; i++, j++) {
tl[i] = (struct sched_domain_topology_level){
.mask = sd_numa_mask,
.sd_flags = cpu_numa_flags,
.flags = SDTL_OVERLAP,
.numa_level = j,
SD_INIT_NAME(NUMA)
};
}
sched_domain_topology = tl;
sched_domains_numa_levels = level;
sched_max_numa_distance = sched_domains_numa_distance[level - 1];
init_numa_topology_type();
}檢測系統的物理拓撲結構,如果存在 NUMA 域則需要將其加到 sched_domain_topology 里,后面就會根據 sched_domain_topology 這個物理拓撲結構來建立相應的調度域。
下面接著分析 sched_init_domains 這個調度域建立函數
/*
* Set up scheduler domains and groups. For now this just excludes isolated
* CPUs, but could be used to exclude other special cases in the future.
*/
int sched_init_domains(const struct cpumask *cpu_map)
{
int err;
zalloc_cpumask_var(&sched_domains_tmpmask, GFP_KERNEL);
zalloc_cpumask_var(&sched_domains_tmpmask2, GFP_KERNEL);
zalloc_cpumask_var(&fallback_doms, GFP_KERNEL);
arch_update_cpu_topology();
ndoms_cur = 1;
doms_cur = alloc_sched_domains(ndoms_cur);
if (!doms_cur)
doms_cur = &fallback_doms;
/*
* doms_cur[0] 表示調度域需要覆蓋的cpumask
*
* 如果系統里用isolcpus=對某些CPU進行了隔離,那么這些CPU是不會加入到調度
* 域里面,即這些CPU不會參于到負載均衡(這里的負載均衡包括DL/RT以及CFS)。
* 這里用 cpu_map & housekeeping_cpumask(HK_FLAG_DOMAIN) 的方式將isolate
* cpu去除掉,從而在保證建立的調度域里不包含isolate cpu
*/
cpumask_and(doms_cur[0], cpu_map, housekeeping_cpumask(HK_FLAG_DOMAIN));
/* 調度域建立的實現函數 */
err = build_sched_domains(doms_cur[0], NULL);
register_sched_domain_sysctl();
return err;
}/*
* Build sched domains for a given set of CPUs and attach the sched domains
* to the individual CPUs
*/
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
enum s_alloc alloc_state = sa_none;
struct sched_domain *sd;
struct s_data d;
struct rq *rq = NULL;
int i, ret = -ENOMEM;
struct sched_domain_topology_level *tl_asym;
bool has_asym = false;
if (WARN_ON(cpumask_empty(cpu_map)))
goto error;
/*
* Linux里的絕大部分進程都為CFS調度類,所以CFS里的sched_domain將會被頻繁
* 的訪問與修改(例如nohz_idle以及sched_domain里的各種統計),所以sched_domain
* 的設計需要優先考慮到效率問題,于是內核采用了percpu的方式來實現sched_domain
* CPU間的每級sd都是獨立申請的percpu變量,這樣可以利用percpu的特性解決它們
* 間的并發競爭問題(1、不需要鎖保護 2、沒有cachline偽共享)
*/
alloc_state = __visit_domain_allocation_hell(&d, cpu_map);
if (alloc_state != sa_rootdomain)
goto error;
tl_asym = asym_cpu_capacity_level(cpu_map);
/*
* Set up domains for CPUs specified by the cpu_map:
*
* 這里會遍歷cpu_map里所有CPU,為這些CPU創建與物理拓撲結構對應(
* for_each_sd_topology)的多級調度域。
*
* 在調度域建立的時候,會通過tl->mask(cpu)獲得cpu在該級調度域對應
* 的span(即cpu與其他對應的cpu組成了這個調度域),在同一個調度域里
* 的CPU對應的sd在剛開始的時候會被初始化成一樣的(包括sd->pan、
* sd->imbalance_pct以及sd->flags等參數)。
*/
for_each_cpu(i, cpu_map) {
struct sched_domain_topology_level *tl;
sd = NULL;
for_each_sd_topology(tl) {
int dflags = 0;
if (tl == tl_asym) {
dflags |= SD_ASYM_CPUCAPACITY;
has_asym = true;
}
sd = build_sched_domain(tl, cpu_map, attr, sd, dflags, i);
if (tl == sched_domain_topology)
*per_cpu_ptr(d.sd, i) = sd;
if (tl->flags & SDTL_OVERLAP)
sd->flags |= SD_OVERLAP;
if (cpumask_equal(cpu_map, sched_domain_span(sd)))
break;
}
}
/*
* Build the groups for the domains
*
* 創建調度組
*
* 我們可以從2個調度域的實現看到sched_group的作用
* 1、NUMA域 2、LLC域
*
* numa sched_domain->span會包含NUMA域上所有的CPU,當需要進行均衡的時候
* NUMA域不應該以cpu為單位,而是應該以socket為單位,即只有socket1與socket2
* 極度不平衡的時候才在這兩個SOCKET間遷移CPU。如果用sched_domain來實現這個
* 抽象則會導致靈活性不夠(后面的MC域可以看到),所以內核會以sched_group來
* 表示一個cpu集合,每個socket屬于一個sched_group。當這兩個sched_group不平衡
* 的時候才會允許遷移
*
* MC域也是類似的,CPU可能是超線程,而超線程的性能與物理核不是對等的。一對
* 超線程大概等于1.2倍于物理核的性能。所以在調度的時候,我們需要考慮超線程
* 對之間的均衡性,即先要滿足CPU間均衡,然后才是CPU內的超線程均衡。這個時候
* 用sched_group來做抽象,一個sched_group表示一個物理CPU(2個超線程),這個時候
* LLC保證CPU間的均衡,從而避免一種極端情況:超線程間均衡,但是物理核上不均衡
* 的情況,同時可以保證調度選核的時候,內核會優先實現物理線程,只有物理線程
* 用完之后再考慮使用另外的超線程,讓系統可以更充分的利用CPU算力
*/
for_each_cpu(i, cpu_map) {
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
sd->span_weight = cpumask_weight(sched_domain_span(sd));
if (sd->flags & SD_OVERLAP) {
if (build_overlap_sched_groups(sd, i))
goto error;
} else {
if (build_sched_groups(sd, i))
goto error;
}
}
}
/*
* Calculate CPU capacity for physical packages and nodes
*
* sched_group_capacity 是用來表示sg可使用的CPU算力
*
* sched_group_capacity 是考慮了每個CPU本身的算力不同(最高主頻設置不同、
* ARM的大小核等等)、去除掉RT進程所使用的CPU(sg是為CFS準備的,所以需要
* 去掉CPU上DL/RT進程等所使用的CPU算力)等因素之后,留給CFS sg的可用算力(因為
* 在負載均衡的時候,不僅應該考慮到CPU上的負載,還應該考慮這個sg上的CFS
* 可用算力。如果這個sg上進程較少,但是sched_group_capacity也較小,也是
* 不應該遷移進程到這個sg上的)
*/
for (i = nr_cpumask_bits-1; i >= 0; i--) {
if (!cpumask_test_cpu(i, cpu_map))
continue;
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
claim_allocations(i, sd);
init_sched_groups_capacity(i, sd);
}
}
/* Attach the domains */
rcu_read_lock();
/*
* 將每個CPU的rq與rd(root_domain)進行綁定,并且會檢查sd是否有重疊
* 如果是的則需要用destroy_sched_domain()將其去掉(所以我們可以看到
* intel的服務器是只有3層調度域,DIE域其實與LLC域重疊了,所以在這里
* 會被去掉)
*/
for_each_cpu(i, cpu_map) {
rq = cpu_rq(i);
sd = *per_cpu_ptr(d.sd, i);
/* Use READ_ONCE()/WRITE_ONCE() to avoid load/store tearing: */
if (rq->cpu_capacity_orig > READ_ONCE(d.rd->max_cpu_capacity))
WRITE_ONCE(d.rd->max_cpu_capacity, rq->cpu_capacity_orig);
cpu_attach_domain(sd, d.rd, i);
}
rcu_read_unlock();
if (has_asym)
static_branch_inc_cpuslocked(&sched_asym_cpucapacity);
if (rq && sched_debug_enabled) {
pr_info("root domain span: %*pbl (max cpu_capacity = %lu)\n",
cpumask_pr_args(cpu_map), rq->rd->max_cpu_capacity);
}
ret = 0;
error:
__free_domain_allocs(&d, alloc_state, cpu_map);
return ret;
}到目前為止,我們已經將內核的調度域構建起來了,CFS 可以利用 sched_domain 來完成多核間的負載均衡了。
以上是“Linux中內核調度器如何初始化”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





