溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Flume基礎用法和Kafka集成是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Flume是Cloudera提供的一個高可用的,高可靠的,分布式的海量日志采集、聚合和傳輸的系統,Flume支持在日志系統中定制各類數據發送方,用于收集數據;
特點:分布式、高可用、基于流式架構,通常用來收集、聚合、搬運不同數據源的大量日志到數據倉庫。
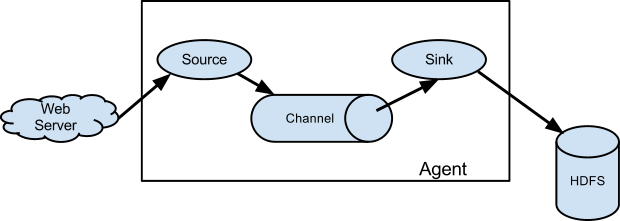
Agent包括三個核心組成,Source、Channel、Sink。Source負責接收數據源,并兼容多種類型,Channel是數據的緩沖區,Sink處理數據輸出的方式和目的地。
Event是Flume定義的一個數據流傳輸的基本單元,將數據從源頭送至目的地。
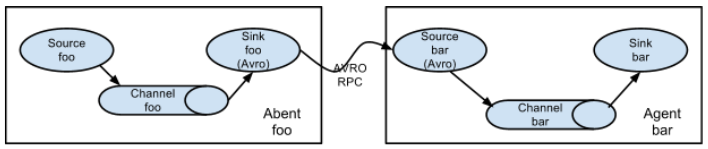
Flume可以設置多級Agent連接的方式傳輸Event數據,從最初的source開始到最終sink傳送的目的存儲系統,如果數量過多會影響傳輸速率,并且傳輸過程中單節點故障也會影響整個傳輸通道。
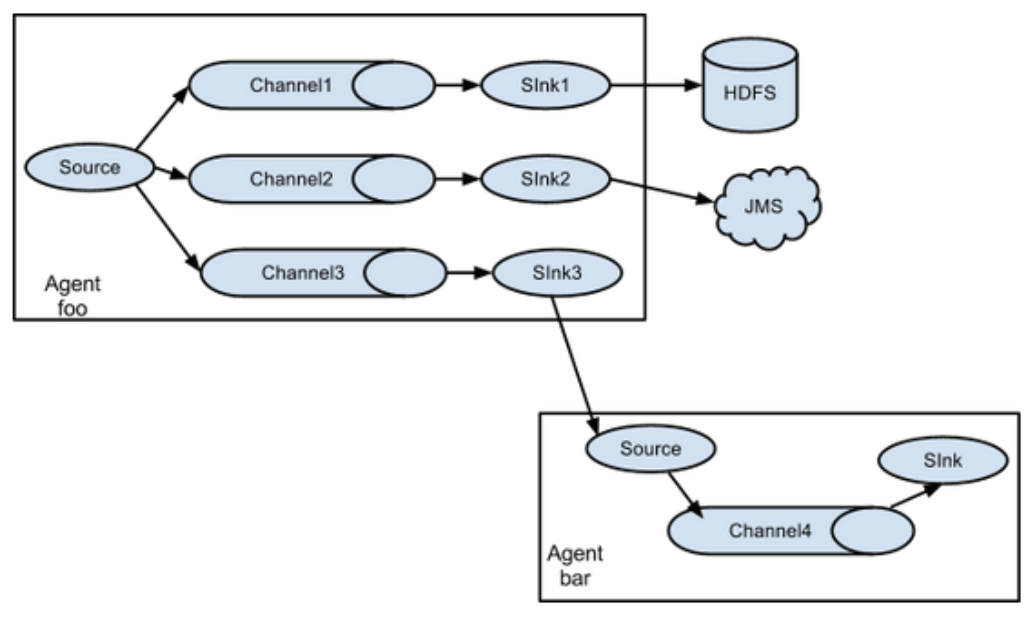
Flume支持多路復用數據流到一個或多個目的地,這種模式可以將相同數據復制到多個channel中,或者將不同數據分發到不同的channel中,并且sink可以選擇傳送到不同的目的地。
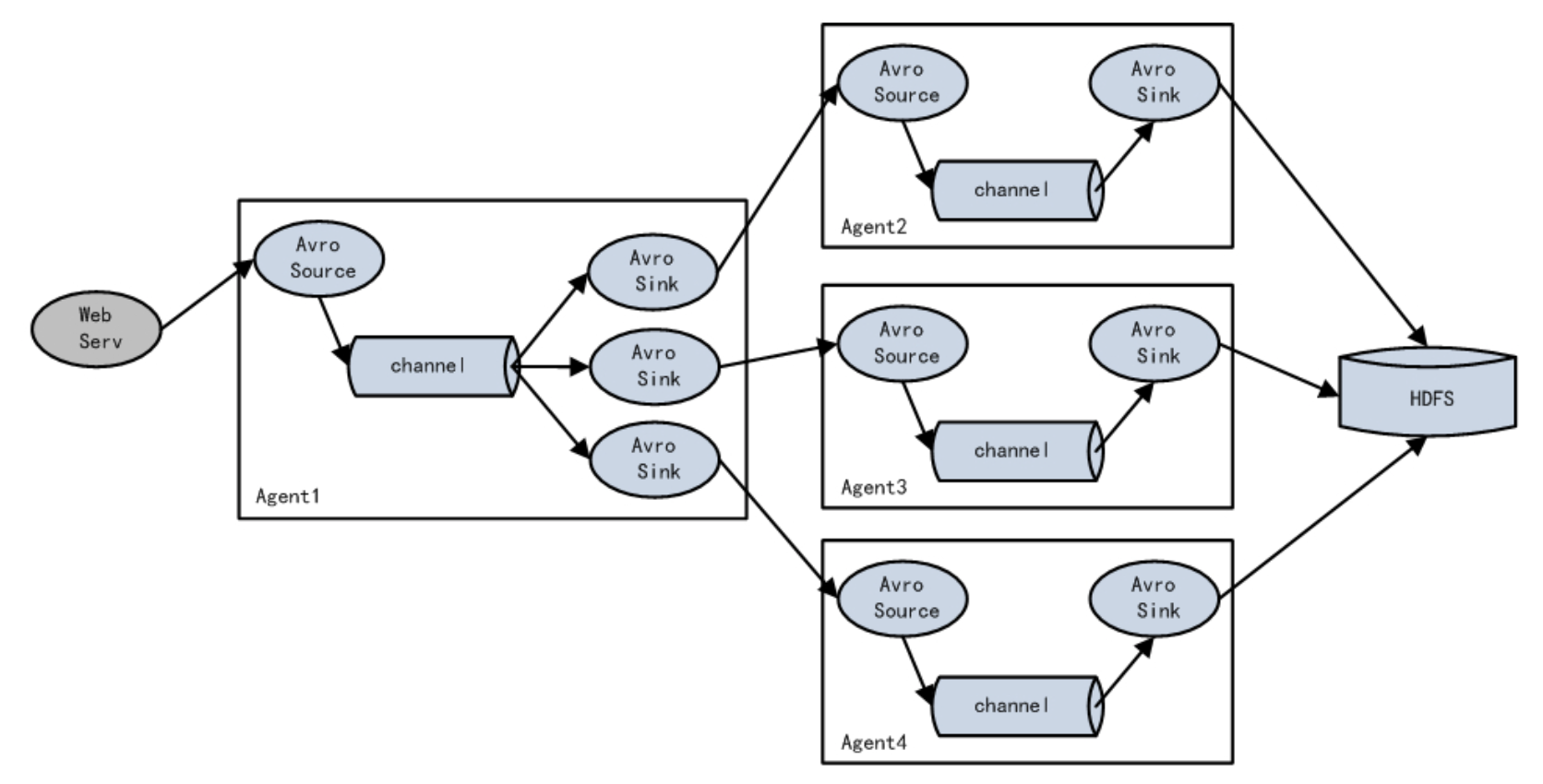
Agent1理解為路由節點負責Channel的Event均衡到多個Sink組件,每個Sink組件分別連接到獨立的Agent上,實現負載均衡和錯誤恢復的功能。
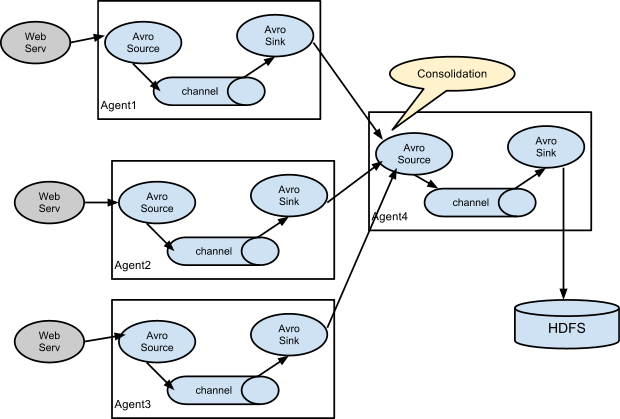
Flume的使用組合方式做數據聚合,每臺服務器部署一個flume節點采集日志數據,再匯聚傳輸到存儲系統,例如HDFS、Hbase等組件,高效且穩定的解決集群數據的采集。
apache-flume-1.7.0-bin.tar.gz
[root@hop01 opt]# pwd /opt [root@hop01 opt]# tar -zxf apache-flume-1.7.0-bin.tar.gz [root@hop01 opt]# mv apache-flume-1.7.0-bin flume1.7
配置路徑:/opt/flume1.7/conf
mv flume-env.sh.template flume-env.sh
添加JDK依賴
vim flume-env.sh export JAVA_HOME=/opt/jdk1.8
安裝netcat工具
sudo yum install -y nc
創建任務配置
[root@hop01 flume1.7]# cd job/ [root@hop01 job]# vim flume-netcat-test01.conf
添加基礎任務配置
注意:a1表示agent名稱。
# this agent a1.sources = sr1 a1.sinks = sk1 a1.channels = sc1 # the source a1.sources.sr1.type = netcat a1.sources.sr1.bind = localhost a1.sources.sr1.port = 55555 # the sink a1.sinks.sk1.type = logger # events in memory a1.channels.sc1.type = memory a1.channels.sc1.capacity = 1000 a1.channels.sc1.transactionCapacity = 100 # Bind the source and sink a1.sources.sr1.channels = sc1 a1.sinks.sk1.channel = sc1
開啟flume監聽端口
/opt/flume1.7/bin/flume-ng agent --conf /opt/flume1.7/conf/ --name a1 --conf-file /opt/flume1.7/job/flume-netcat-test01.conf -Dflume.root.logger=INFO,console
使用netcat工具向55555端口發送數據
[root@hop01 ~]# nc localhost 55555 hello,flume
查看flume控制面

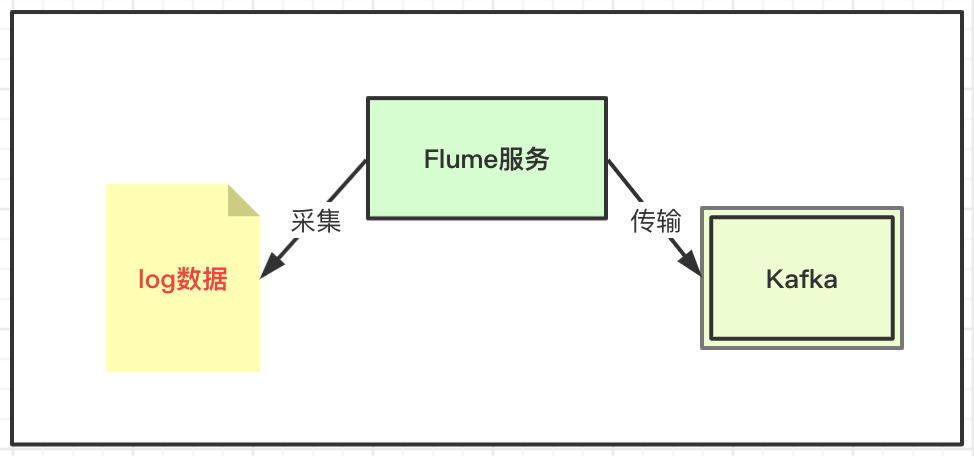
基于flume在各個集群服務進行數據采集,然后數據傳到kafka服務,再考慮數據的消費策略。
采集:基于flume組件的便捷采集能力,如果直接使用kafka會產生大量的埋點動作不好維護。
消費:基于kafka容器的數據臨時存儲能力,避免系統高度活躍期間采集數據過大沖垮數據采集通道,并且可以基于kafka做數據隔離并針對化處理。
[root@hop01 job]# pwd /opt/flume1.7/job [root@hop01 job]# vim kafka-flume-test01.conf
# the sink a1.sinks.sk1.type = org.apache.flume.sink.kafka.KafkaSink # topic a1.sinks.sk1.topic = kafkatest # broker地址、端口號 a1.sinks.sk1.kafka.bootstrap.servers = hop01:9092 # 序列化方式 a1.sinks.sk1.serializer.class = kafka.serializer.StringEncoder
上述配置文件中名稱:kafkatest,下面執行創建命令之后查看topic信息。
[root@hop01 bin]# pwd /opt/kafka2.11 [root@hop01 kafka2.11]# bin/kafka-topics.sh --create --zookeeper hop01:2181 --replication-factor 1 --partitions 1 --topic kafkatest [root@hop01 kafka2.11]# bin/kafka-topics.sh --describe --zookeeper hop01:2181 --topic kafkatest
[root@hop01 kafka2.11]# bin/kafka-console-consumer.sh --bootstrap-server hop01:2181 --topic kafkatest --from-beginning
這里指定topic是kafkatest。
/opt/flume1.7/bin/flume-ng agent --conf /opt/flume1.7/conf/ --name a1 --conf-file /opt/flume1.7/job/kafka-flume-test01.conf -Dflume.root.logger=INFO,console
“Flume基礎用法和Kafka集成是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





