溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“TiDB+FLINK進行數據實時統計的方法是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“TiDB+FLINK進行數據實時統計的方法是什么”吧!
# 指定配置文件中涉及的庫名、表名是否為大小寫敏感
# 該配置會同時影響 filter 和 sink 相關配置,默認為 true
case-sensitive = true
# 是否輸出 old value,從 v4.0.5 開始支持
enable-old-value = true
[filter]
# 忽略指定 start_ts 的事務
ignore-txn-start-ts = [1, 2]
# 過濾器規則
# 過濾規則語法:https://docs.pingcap.com/zh/tidb/stable/table-filter#表庫過濾語法 指定了我的銷售表
rules = ['dspdev.sales_order_header']
[mounter]
# mounter 線程數,用于解碼 TiKV 輸出的數據
worker-num = 16
[sink]
# 對于 MQ 類的 Sink,可以通過 dispatchers 配置 event 分發器
# 支持 default、ts、rowid、table 四種分發器,分發規則如下:
# - default:有多個唯一索引(包括主鍵)時按照 table 模式分發;只有一個唯一索引(或主鍵)按照 rowid 模式分發;如果開啟了 old value 特性,按照 table 分發
# - ts:以行變更的 commitTs 做 Hash 計算并進行 event 分發
# - rowid:以所選的 HandleKey 列名和列值做 Hash 計算并進行 event 分發
# - table:以表的 schema 名和 table 名做 Hash 計算并進行 event 分發
# matcher 的匹配語法和過濾器規則語法相同
dispatchers = [
{matcher = ['dspdev.*'], dispatcher = "ts"}
]
# 對于 MQ 類的 Sink,可以指定消息的協議格式
# 目前支持 default、canal、avro 和 maxwell 四種協議。default 為 TiCDC Open Protocol
protocol = "canal"
[cyclic-replication]
# 是否開啟環形同步
enable = false
# 當前 TiCDC 的復制 ID
replica-id = 1
# 需要過濾掉的同步 ID
filter-replica-ids = [2,3]
# 是否同步 DDL
sync-ddl = true--sink-uri="kafka://127.0.0.1:9092/cdc-test?kafka-version=2.4.0&partition-num=6&max-message-bytes=67108864&replication-factor=1"
這樣就會將tidb cdc 數據以protobuf數據發完kafka,我們只需要在下游做解析就好 具體配置解釋參考:tidb配置連接
pom引入如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.konka.dsp</groupId>
<artifactId>kafka-parse</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>kafka-parse</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>11</java.version>
<fastjson.version>1.2.70</fastjson.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.springframework.cloud</groupId>-->
<!-- <artifactId>spring-cloud-starter</artifactId>-->
<!-- </dependency>-->
<!-- <dependency>-->
<!-- <groupId>org.springframework.cloud</groupId>-->
<!-- <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>-->
<!-- </dependency>-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>properties 如下:
###########【Kafka集群】###########
spring.kafka.bootstrap-servers=192.168.8.71:9092
###########【初始化生產者配置】###########
# 重試次數
spring.kafka.producer.retries=0
# 應答級別:多少個分區副本備份完成時向生產者發送ack確認(可選0、1、all/-1)
spring.kafka.producer.acks=1
# 批量大小
spring.kafka.producer.batch-size=16384
# 提交延時
spring.kafka.producer.properties.linger.ms=0
# 當生產端積累的消息達到batch-size或接收到消息linger.ms后,生產者就會將消息提交給kafka
# linger.ms為0表示每接收到一條消息就提交給kafka,這時候batch-size其實就沒用了
?
# 生產端緩沖區大小
spring.kafka.producer.buffer-memory = 33554432
# Kafka提供的序列化和反序列化類
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 自定義分區器
# spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
###########【初始化消費者配置】###########
# 默認的消費組ID
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
# 是否自動提交offset
spring.kafka.consumer.enable-auto-commit=true
# 提交offset延時(接收到消息后多久提交offset)
spring.kafka.consumer.auto.commit.interval.ms=1000
# 當kafka中沒有初始offset或offset超出范圍時將自動重置offset
# earliest:重置為分區中最小的offset;
# latest:重置為分區中最新的offset(消費分區中新產生的數據);
# none:只要有一個分區不存在已提交的offset,就拋出異常;
spring.kafka.consumer.auto-offset-reset=latest
# 消費會話超時時間(超過這個時間consumer沒有發送心跳,就會觸發rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
# 消費請求超時時間
spring.kafka.consumer.properties.request.timeout.ms=180000
# Kafka提供的序列化和反序列化類
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=com.alibaba.otter.canal.client.kafka.MessageDeserializer
# 消費端監聽的topic不存在時,項目啟動會報錯(關掉)
spring.kafka.listener.missing-topics-fatal=false
#過濾table和字段
table.data = {"sales_order_header":"id,customer_name,total_amount,created_date"}
# 設置批量消費
# spring.kafka.listener.type=batch
# 批量消費每次最多消費多少條消息sprint boot kafka 消費端代碼如下:
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.serializer.SerializerFeature;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.FlatMessage;
import com.alibaba.otter.canal.protocol.Message;
import com.konka.dsp.kafkaparse.CanalKafkaClientExample;
import com.konka.dsp.kafkaparse.tidb.KafkaMessage;
import com.konka.dsp.kafkaparse.tidb.TicdcEventData;
import com.konka.dsp.kafkaparse.tidb.TicdcEventDecoder;
import com.konka.dsp.kafkaparse.tidb.TicdcEventFilter;
import com.konka.dsp.kafkaparse.tidb.value.TicdcEventDDL;
import com.konka.dsp.kafkaparse.tidb.value.TicdcEventResolve;
import com.konka.dsp.kafkaparse.tidb.value.TicdcEventRowChange;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Optional;
@Component
public class kafkaConsumer {
protected final static Logger logger = LoggerFactory.getLogger(CanalKafkaClientExample.class);
// 消費監聽
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Value("#{${table.data}}")
private Map<String,String> map;
@KafkaListener(topics = {"cdc-test"})
public void onMessage1(ConsumerRecord<String, Message> consumerRecord) throws UnsupportedEncodingException {
Message message = consumerRecord.value();
long batchId = message.getId();
FlatMessage fm = new FlatMessage();
List<CanalEntry.Entry> entrys = message.getEntries();
for (CanalEntry.Entry entry : entrys) {
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChage = null;
try {
rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
fm.setId(entry.getHeader().getExecuteTime());
fm.setDatabase(entry.getHeader().getSchemaName());
fm.setEs(entry.getHeader().getExecuteTime());
fm.setTs(entry.getHeader().getExecuteTime());
fm.setTable(entry.getHeader().getTableName());
fm.setType(rowChage.getEventType().name());
CanalEntry.EventType eventType = rowChage.getEventType();
fm.setIsDdl(rowChage.getIsDdl());
fm.setSql(rowChage.getSql());
Map<String,String> mysqlTypes = new HashMap<>();
Map<String,Integer> sqlType = new HashMap<>();
List<String> pkNames = new ArrayList<>();
logger.info(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
String[] filtercolumn = map.get(entry.getHeader().getTableName()).split(",");
logger.info(" filter --> column {}",filtercolumn);
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
fm.setData(saveRowData(rowData.getBeforeColumnsList(),pkNames,filtercolumn));
fm.setMysqlType(setMysqlTypes(rowData.getBeforeColumnsList(),filtercolumn));
fm.setSqlType(setSqlTypes(rowData.getBeforeColumnsList(),filtercolumn));
} else if (eventType == CanalEntry.EventType.INSERT) {
fm.setData(saveRowData(rowData.getAfterColumnsList(),pkNames,filtercolumn));
fm.setMysqlType(setMysqlTypes(rowData.getAfterColumnsList(),filtercolumn));
fm.setSqlType(setSqlTypes(rowData.getAfterColumnsList(),filtercolumn));
} else {
logger.info("-------> before->{}",rowData.getBeforeColumnsList().size());
fm.setOld(saveRowData(rowData.getBeforeColumnsList(),pkNames,filtercolumn));
logger.info("-------> after");
fm.setData(saveRowData(rowData.getAfterColumnsList(),pkNames,filtercolumn));
fm.setMysqlType(setMysqlTypes(rowData.getAfterColumnsList(),filtercolumn));
fm.setSqlType(setSqlTypes(rowData.getAfterColumnsList(),filtercolumn));
if(rowData.getBeforeColumnsList().size()==0&&rowData.getAfterColumnsList().size()>0){
fm.setType("INSERT");
}
}
}
HashSet h = new HashSet(pkNames);
pkNames.clear();
pkNames.addAll(h);
fm.setPkNames(pkNames);
}
logger.info("json解析:{}",JSON.toJSONString(fm, SerializerFeature.WriteMapNullValue));
kafkaTemplate.send("canal-data",JSON.toJSONString(fm, SerializerFeature.WriteMapNullValue));
//
// FlatMessage flatMessage = (FlatMessage)JSON.parseObject(flatMessageJson, FlatMessage.class);
// 消費的哪個topic、partition的消息,打印出消息內容
// KafkaMessage kafkaMessage = new KafkaMessage();
// kafkaMessage.setKey(consumerRecord.key());
// kafkaMessage.setValue(consumerRecord.value());
// kafkaMessage.setOffset(consumerRecord.offset());
// kafkaMessage.setPartition(consumerRecord.partition());
// kafkaMessage.setTimestamp(consumerRecord.timestamp());
// TicdcEventFilter filter = new TicdcEventFilter();
// TicdcEventDecoder ticdcEventDecoder = new TicdcEventDecoder(kafkaMessage);
// while (ticdcEventDecoder.hasNext()) {
// TicdcEventData data = ticdcEventDecoder.next();
// if (data.getTicdcEventValue() instanceof TicdcEventRowChange) {
// boolean ok = filter.check(data.getTicdcEventKey().getTbl(), data.getTicdcEventValue().getKafkaPartition(), data.getTicdcEventKey().getTs());
// if (ok) {
// // deal with row change event
// } else {
// // ignore duplicated messages
// }
// } else if (data.getTicdcEventValue() instanceof TicdcEventDDL) {
// // deal with ddl event
// } else if (data.getTicdcEventValue() instanceof TicdcEventResolve) {
// filter.resolveEvent(data.getTicdcEventValue().getKafkaPartition(), data.getTicdcEventKey().getTs());
// // deal with resolve event
// }
// System.out.println(JSON.toJSONString(data, true));
// }
}
private List<Map<String,String>> saveRowData(List<CanalEntry.Column> columns,List<String> pkNames,String[] filter) {
Map map = new HashMap<>();
List<Map<String,String>> rowdata = new ArrayList<>();
columns.forEach(column -> {
if(column.hasIsKey()){
pkNames.add(column.getName());
}
if(Arrays.asList(filter).contains(column.getName())){
map.put(column.getName(),column.getValue().equals("")?"NULL":column.getValue());
}
//防止flink接收""報錯
});
rowdata.add(map);
return rowdata;
// rabbitTemplate.convertAndSend(tableEventType.toUpperCase(),JSON.toJSONString(map));
}
private Map<String,String> setMysqlTypes(List<CanalEntry.Column> columns,String[] filter){
Map<String,String> map = new HashMap<>();
columns.forEach(column -> {
if(Arrays.asList(filter).contains(column.getName())){
map.put(column.getName(),column.getMysqlType());
}
});
return map;
}
private Map<String,Integer> setSqlTypes(List<CanalEntry.Column> columns,String[] filter){
Map<String,Integer> map = new HashMap<>();
columns.forEach(column -> {
if(Arrays.asList(filter).contains(column.getName())){
map.put(column.getName(),column.getSqlType());
}
});
return map;
}
private static void printColumn(List<CanalEntry.Column> columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}這里基本上將 tidb的數據轉化為canal-json格式數據,這里我們繼續將轉化后的數據發完kafka,以便kafka 繼續消費,這里有個點就是不知道為什么tidb出來的insert和update eventtype類型都是UPDATE,所以我在代碼做了判斷沒有OLD的話基本上就是INSERT了
具體參考官網 flinktable配置 把table相關jar包拷貝到flink下的lib目錄下即可 這里的會用到另外一個知乎開源的相關包項目地址如下: https://github.com/pingcap-incubator/TiBigData/ 把項目編譯完成以后把flink相關jar包拷貝到flink下的lib下 
import org.apache.flink.api.java.DataSet;
import org.apache.flink.table.api.*;
import org.apache.flink.table.expressions.TimeIntervalUnit;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.*;
public class SalesOrderStream {
public static Table report(Table transactions) {
return transactions.select(
$("customer_name"),
$("created_date"),
$("total_amount"))
.groupBy($("customer_name"), $("created_date"))
.select(
$("customer_name"),
$("total_amount").sum().as("total_amount"),
$("created_date")
);
}
public static void main(String[] args) throws Exception {
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
// tEnv.executeSql("CREATE TABLE sales_order_header_stream (\n" +
//// " id BIGINT not null,\n" +
// " customer_name STRING,\n"+
//// " dsp_org_name STRING,\n"+
// " total_amount DECIMAL(38,2),\n" +
//// " total_discount DECIMAL(16,2),\n" +
//// " pay_amount DECIMAL(16,2),\n" +
//// " total_amount DECIMAL(16,2),\n" +
// " created_date TIMESTAMP(3)\n" +
// ") WITH (\n" +
// " 'connector' = 'mysql-cdc',\n" +
// " 'hostname' = '192.168.8.73',\n" +
// " 'port' = '4000',\n"+
// " 'username' = 'flink',\n"+
// " 'password' = 'flink',\n"+
// " 'database-name' = 'dspdev',\n"+
// " 'table-name' = 'sales_order_header'\n"+
// ")");
tEnv.executeSql("CREATE TABLE sales_order_header_stream (\n" +
" `id` BIGINT,\n"+
" `total_amount` DECIMAL(16,2) ,\n"+
" `customer_name` STRING,\n"+
" `created_date` TIMESTAMP(3) ,\n"+
" PRIMARY KEY (`id`) NOT ENFORCED "+
") WITH (\n" +
"'connector' = 'kafka',\n"+
"'topic' = 'canal-data',\n"+
"'properties.bootstrap.servers' = '192.168.8.71:9092',\n"+
"'properties.group.id' = 'test',\n"+
"'scan.startup.mode' = 'earliest-offset',\n"+
"'format' = 'canal-json'\n"+
")");
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" customer_name STRING,\n" +
// " total_amount DECIMAL(16,2),\n" +
// " total_discount DECIMAL(16,2),\n" +
// " pay_amount DECIMAL(16,2),\n" +
" total_amount DECIMAL(16,2),\n" +
" created_date TIMESTAMP(3),\n" +
" PRIMARY KEY (customer_name,created_date) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'tidb',\n" +
" 'tidb.database.url' = 'jdbc:mysql://192.168.8.73:4000/dspdev',\n" +
" 'tidb.username' = 'flink',\n"+
" 'tidb.password' = 'flink',\n"+
" 'tidb.database.name' = 'dspdev',\n"+
" 'tidb.table.name' = 'spend_report'\n"+
")");
Table transactions = tEnv.from("sales_order_header_stream");
report(transactions).executeInsert("spend_report");
}
}這樣在我數據庫里面就可以實時統計當前的銷售總價并寫入數據庫里,最后數據庫數據如下: 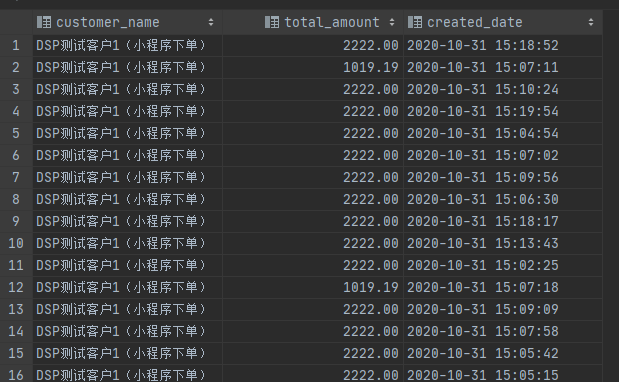
到此,相信大家對“TiDB+FLINK進行數據實時統計的方法是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





