溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
4種語義分割數據集Cityscapes上SOTA方法分別是什么,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
Cityscapes評測數據集即城市景觀數據集,在2015年由奔馳公司推動發布,是目前公認的機器視覺領域內最具權威性和專業性的圖像分割數據集之一。Cityscapes擁有5000張精細標注的在城市環境中駕駛場景的圖像(2975train,500 val,1525test)。它具有19個類別的密集像素標注(97%coverage),其中8個具有實例級分割。具體類別名稱見于下表1。
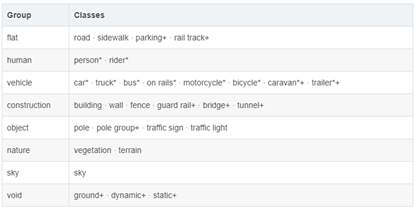
表1 Cityscapes數據集中的類別名稱
當前語義分割方法面臨3個挑戰,其中第一個挑戰是基于FCN的分辨率由高到低會損失信息。
語義分割方法需要高分辨率特征,圖中1展示了幾種基于FCN的經典方法的,它們的共同點通過一個網絡得到 低分辨 feature map,然后通過上采樣或反卷積恢復到高分辨率。
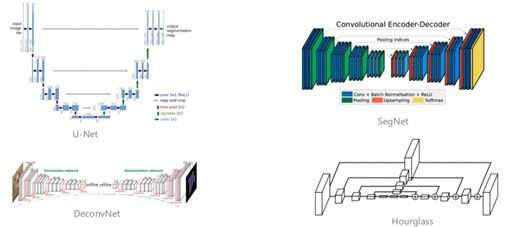
圖1 基于FCN方法的幾種經典結構
這些看起來不同,但本質核心思路是差不多的。這些方法存在一個缺點,分辨率由高到低會損失信息!
為了解決2.1中的問題,作者團隊(MSRA和中科院)提出一個方法,核心思路是“不恢復高分辨率,而是保持分辨率”。如下圖2中是一個基本的高分辨率保持網絡結構,該結構把不同分辨率的feature map并聯,相同分辨率的占一條分支,不同分辨率的占不同分支。并在不同分支之間添加通路(圖中的斜線),形成high-resolution network。

圖2 基本的high-resolution network結構
圖2中的機構由4個stage組成,每一個藍底色塊為一個stage。在SOTA方法中,采用的是HRNet-W48,其結構圖如圖3所示。
圖3 HRNet-W48結構圖
HRNet V2-W48是在4個stage(圖3中藍、綠、紅、黃4種底色區域)的頭部加上stem net(圖3中白色底色區域),尾部加上segment head后(圖中未畫出)組成。下面按照先后順序依次對stem net、4個stage以及segment head進行介紹。
(1)stem net
stem net由兩個Bottelneck組成,與Resnet的結構一樣,經過兩個Bottelneck以后,輸入圖像的維度由H*W*3變成了(H/4)*(W/4)*256
(2)4個stage
每個 stage 上的各個組件配置如下表2,以 hrnet_48 為例
stage之間通過transition_layer連接,stage內由重復的基本單元HighResolutionModule組成。
HighResolutionModule由分支以及分支末尾的fuse_layers組成。
每條分支內由重復的basicblock組成,具體數量見表2
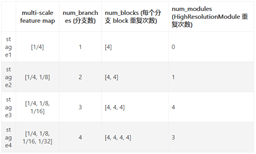
表2 HRNet-W48模型配置表
A:stage間的transition layer:完成 stage之間通道轉換和尺寸下采樣,即圖3中不同底色之間連接的直線和斜線stage之間的斜線,指向不做任何處理。
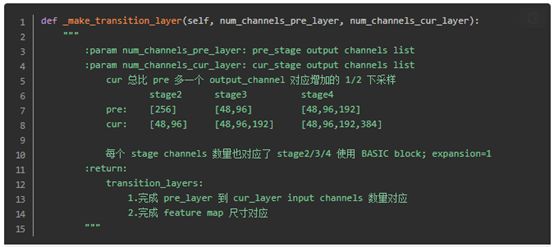
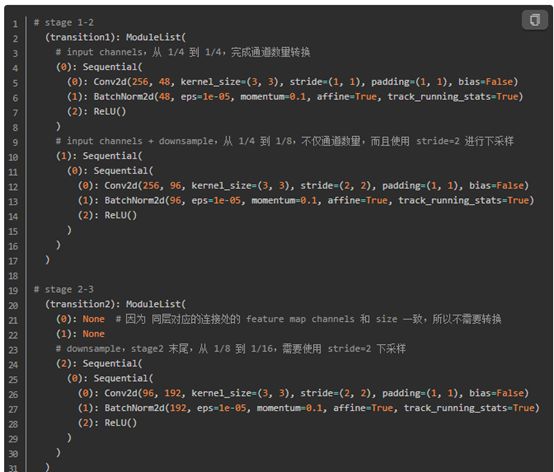
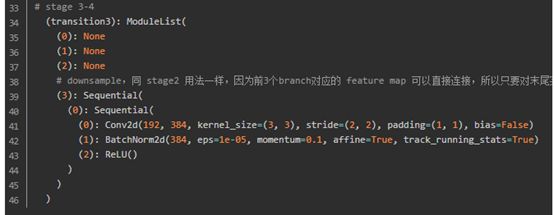
圖4 stage間的transition layer構建代碼
B:構建stage
每個stag均是有若干重復的HighResolutionModule組成,因此構架stage的核心在與構建HighResolutionModule。構建HighResolutionModule分兩步:構建分支、構建分支末尾的fuse_layers。
構建分支:圖3種的4個連續的basicblock即一個分支。
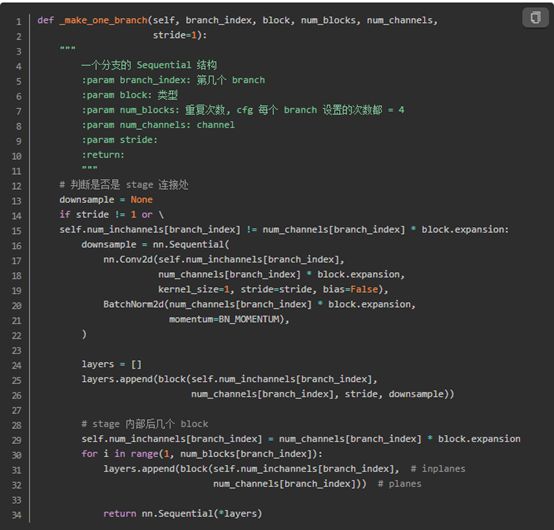
圖5 HighResolutionModule內分支構建代碼
構建fuselayer:
以下圖中藍色框為例說明fuselayer層的處理過程:

圖6 fuselayer層
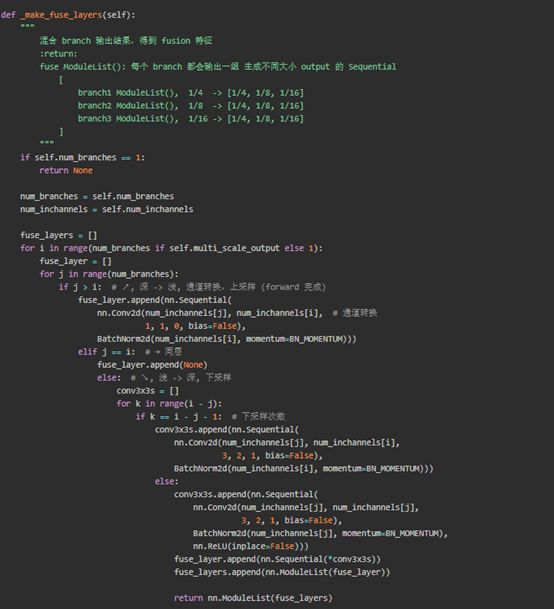
圖6 HighResolutionModule內fuselayer層構建代碼
當前語義分割方法面臨3個挑戰中第二個挑戰是沒有解決好物體上下文信息。
上下文特征:圖像中的每一個像素點不可能是孤立的,一個像素一定和周圍像素是有一定的關系的,大量像素的互相聯系才產生了圖像中的各種物體,所以上下文特征就指像素以及周邊像素的某種聯系。具體到圖像語義分割,就是在判斷某一個位置上的像素屬于哪種類別的時候,不僅考察到該像素的灰度值,還充分考慮和它臨近的像素。
當前方法分析上下文信息如下圖7所示,比如說紅色點是我們關注的點,周圍綠色幾個點是采樣出來的,可以看到,綠色點分為兩部分,一部分是屬于車的,還有一部分是屬于背景的。當前方法并沒有進行區分。

圖7 上下文信息圖
那我們該怎么辦?我們找這個物體,要通過周圍物體的象素表征來幫助。因此,我們需要把紅色像素周圍屬于 object 的pixel取出來做為上下文,如下圖8所示:

圖8 對象區域上下文信息圖
核心思路:OCR提出了一種新的關系上下文方法,該方法根據粗分割結果學習像素與對象區域特征之間的關系來增強像素特征的描述。模型結構如下圖所示。
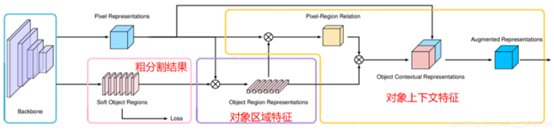
圖9 OCR模型結構圖
計算步驟:
STEP1:獲得粗分割結果。
從backbone最后輸出的FM,在接上一組conv的操作,然后計算cross-entropy loss。
STEP2:獲得對象區域特征。
結合圖9中可知,該步驟需要兩個分支的tensor進行矩陣乘:
Tensor1:pixel representation,骨干網絡最后一層FM,維度為b×c×h×w->b×c×hw
Tensor2:soft object region,FM經過softmax后的結果,維度為b×k×h×w->b×k×hw
將Tensor1和tensor2相乘后的輸出結果為b×k×c,b×k×c便是圖9中對象區域特征的表示。
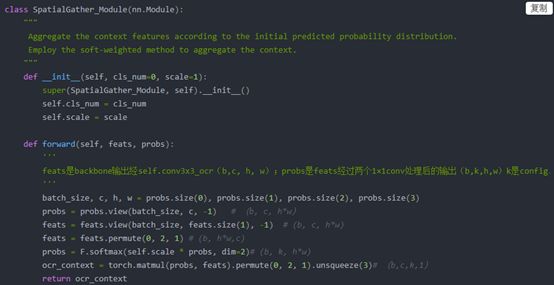
圖10 對象區域特征計算代碼
STEP3:獲得pixel-region relation。
結合圖9中可知,該步驟需要兩個分支的tensor進行矩陣乘:
Tensor1:pixel representation,骨干網絡最后一層FM,維度為b×c×h×w->b×c×hw
Tensor2:STEP2中的對象區域特征,維度為b×k×c
代碼中將兩個tensor的維度進行了轉化,轉化兩個tensor的維度分別為b×key×hw和b×key×k。兩個tensor相乘后得到pixel-region relation的表達式為b×k×h×w。
STEP4:計算最終對象特征上下文表示。
結合圖9中可知,該步驟需要兩個分支的tensor進行矩陣乘:
Tensor1:STEP3中獲得的pixel-region relation,維度為b×k×h×w
Tensor2:STEP2中的對象區域特征,維度為b×k×c
兩個特征相乘后便得到對象上下文特征,即圖10中的紅色塊。
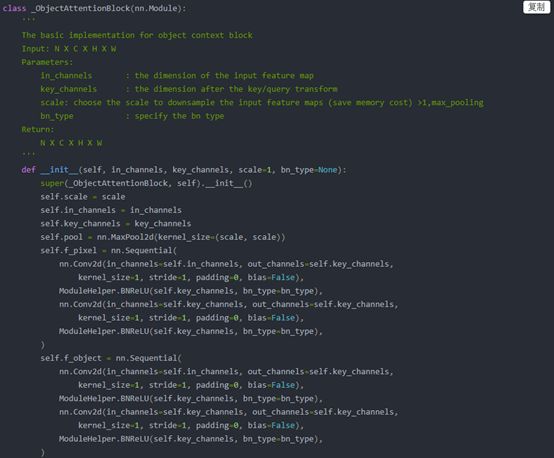
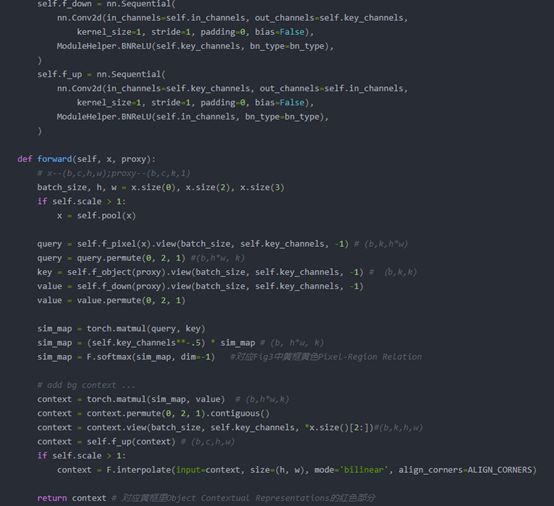
圖11 step2-step4中相關代碼
基于FCN的方法面臨的第三個挑戰是邊緣分割不準確。下圖12顯示了分割結果的誤差圖。下圖12中的第一列顯示了分割GT圖,第二列/第三/ 第四列分別顯示了DeepLabv3 / HRNet / Gated-SCNN的誤差圖。 這些示例是從Cityscapes val set中裁剪的。 我們可以看到,對于這三種方法,在細邊界上都存在許多錯誤。
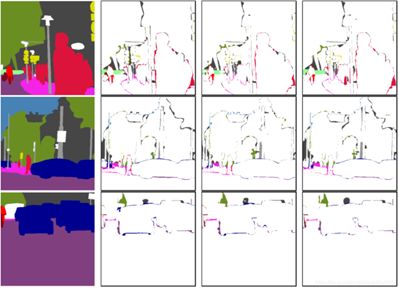
圖12 模型分割結果誤差圖
基于經驗觀察的結果,即內部像素的標簽預測更加可靠,因此用內部像素的預測代替邊界像素的最初不可靠的預測,可能提高模型對邊緣的分割效果。提出了一種新穎的模型無關的后處理機制,通過將邊界像素的標簽替換為對應內部像素的標簽來減少分割結果,從而減少了邊界誤差。
根據4.1中的描述,理所當然的會牽引出兩個問題:(1)如何確定邊緣(2)如何關聯邊緣像素與內部像素。這里借助于一個邊緣預測分支和一個方向預測分支來完成。在獲得良好的邊界和方向預測之后,就可以直接拿來優化現有方法預測的分割圖了。所以另一問題在于,如何將現有的針對邊緣的關聯方向的預測應用到實際的預測優化上。這主要借助于一個坐標偏移分支。這三個分支構成了SegFix的主要結構,其結構圖如圖13所示。
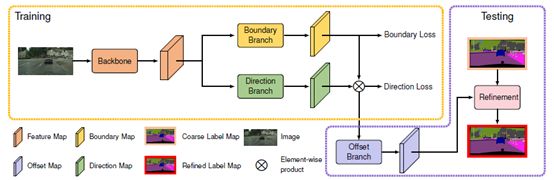
圖13 SegFix模型結構圖
邊緣預測分支:

方向預測分支:

獲取真值:


坐標偏移分支:

大尺度物體在較小分辨率的特征圖上會分割的更好,而小尺度物體則需要精細的細節去推理分割結果,所以在較高分辨率的特征圖上進行預測結果會更好。且論文也舉例分析了此情況的緣由,如下圖所示。
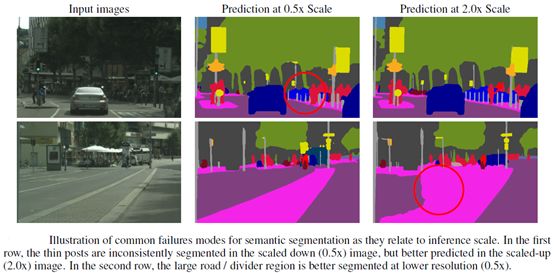
圖12 不同尺寸物體在不同分辨率上的分割表現
因此本文采用注意力機制的方法讓網絡去學習如何最好地組合多個尺度的推理預測。非常直觀的做法就是輸入不同分辨率的圖片,讓網絡學習一下,什么樣的物體應該用什么樣的分辨率。
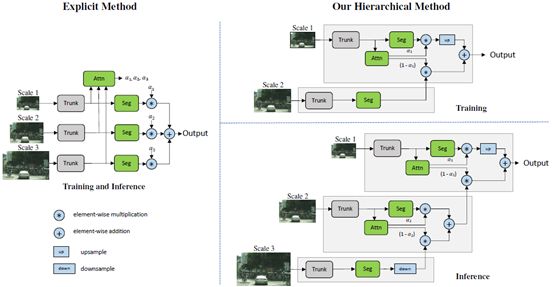
圖13 分層多尺度注意力機制
訓練階段:
上面提出的attention機制與之前的某個方法類似(Attention to scale: Scale-aware semantic image segmentation,圖13中左側方法),對于每個尺度學習一個密集的mask,然后不同尺度的預測再結合起來,這些多尺度預測通過在mask之間進行像素相乘,然后在不同尺度之間進行像素求和,從而得到最終結果。
在本文的分層方法中,學習相鄰尺度之間的相對attention掩碼,而不是學習每個固定尺度集的所有attention掩碼。在訓練網絡時,只訓練相鄰尺度對。如上圖13所示,給出一組來自lower scale的特征圖,預測一個兩個圖像尺度之間的密集的相關attention。在實驗中,為了得到scaled圖像對,使用一個輸入圖像然后將其下采樣兩倍利用scale尺度2,這樣,就有一個1x的輸入和一個0.5x的縮放輸入,當然其他scale-down尺度也可以選擇。需要注意的是,網絡輸入本身是原始訓練圖像的重新縮放版本,因為我們在訓練時使用圖像縮放增強。這使得網絡學會預測一個范圍內的圖像尺度的相對注意力。
在訓練過程中,給定的輸入圖像按因子r進行縮放,其中r= 0.5表示向下采樣按因子2進行,r= 2.0表示向上采樣按因子2進行,r= 1表示不進行操作。對于訓練過程,選擇r= 0.5和r= 1.0。因此,對于兩種尺度的訓練和推斷,以U為雙線性上采樣操作,將?和+分別作為像素級的乘法和加法,方程可以形式化為:
上式中注意力權重α的計算步驟:
1)獲得OCR模塊輸出的augmentations,即圖9中的正藍色塊。
2)見過若干次連續的conv-bn-relu后,獲得維度為b×1的向量
3)對b×1的向量進行sogmoid后,便獲得一個batch上的注意力權重α。
推理階段:
在推理階段,分層的應用學到的注意力來結合N個不同的scale預測。關于各尺度的組合優先考慮較低的scale,然后逐步上升到較高的scale,因為,它們具有更多的全局上下文信息,對于需要改進的scale可以使用更高scale的預測。
多尺度推理時,各尺度組合先后順序:{2.0,1.5,1.0,0.5}

關于4種語義分割數據集Cityscapes上SOTA方法分別是什么問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





