溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關正則表達式關鍵詞的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
在使用正則表達式的時候,我們經常會使用()把某個部分括起來,稱為一個子模式。
子模式有Capturing和Non-Capturing兩種情況。
Capturing指獲取匹配or捕獲匹配 ,是指系統會在幕后將所有的子模式匹配結果保存起來,供我們查找或者替換。如后向引用的使用;
Non-Capturing指非獲取匹配or非捕獲匹配 ,這時系統并不會保存子模式的匹配結果,子模式的匹配更多的只是作為一種限制條件使用,如正向預查,反向預查,正向肯定預查,正向否定預查等。
使用"\數字"代表前面某個子模式的匹配內容。
我們使用正則表達式,在很多場景下的作用是為了查找和替換。在查找時,使用后向引用來代表一個子模式,語法是"\數字",而在替換中,語法是"$數字"。數字 表示這里引用的是前面的第幾個子模式。可參考命名捕獲分組
包括正向預查,反向預查,細分了還各自有肯定預查和否定預查。
特點:
所有的預查都是非獲取匹配,不消耗字符。也就是說,在一個匹配發生后,在匹配字符之后立即開始下一次匹配的搜索,而不是從包含預查的字符之后開始。
匹配后面跟著的東西是否等于/不等于
匹配前面跟著的東西是否等于/不等于
匹配后面/前面跟著的東西是否等于
匹配后面/前面跟著的東西是否不等于
(?=pattern) 預測后面的字符串必須匹配上pattern
先給一個簡單的例子:
匹配英文句子中帶ing的單詞,但是不要ing。
varcon="coming soon,going gogogo"varreg = /\b[\w]+(?=ing\b)/g;//匹配帶ing的單詞,但是不要ing。注意:如果ing后不加\b,類似于goingabc也會匹配。console.log(con.match(reg));
結果匹配到["com", "go"]。先匹配單詞邊界\b,然后+匹配前面多次或者一次,然后到這個正向預查,(?=ing)表示先向后探測,看看有沒有ing。
如果有,則把前面的匹配出來;如果沒有,則光標往后移一位,繼續探測。
這個過程就是正向預查:預先判斷為某個值。然后匹配到的東西不包含這個元素,這里也就是ing。
官方原話是該匹配不需要獲取供以后使用,是一個非捕獲匹配。
(?!pattern) 預測后面的字符串必須匹配不上pattern
(?<=pattern) 預測前面的字符串必須匹配上pattern
(?<!pattern) 預測前面的字符串必須匹配不上pattern
反向預查,pattern長度必須是固定的,也就是說pattern中不能出現諸如*.等這類字符使得pattern匹配的長度不固定;但是正向沒有這個要求。
考慮這樣一個應用情景:對于一個大的數值,比如35689412,西方國家習慣三位一個量級,中間以逗號隔開,方便一眼看出大小,也即是35,689,412。那么現在有一堆數,請用正則表達式完成替換,替換成諸如35,689,412的格式。
題目分析:也就是從右往左數,每隔三個數,如果前面還有數的話就在前面加個逗號。也就是找到這些特定的位置,在該位置處加上“,”。
varnumber = "82359123650916359816359";varregex = /(?<=\d)(?=(\d{3})+$)/g;
number.replace(regex,",");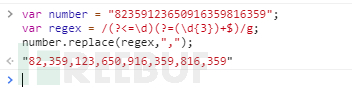
例子中使用的正則表達式:/(?<=\d)(?=(\d{3})+$)/g;
(\d{3})+ 作用:匹配3個數字 6個數字 或9個數字……
(\d{3})+$ 作用:匹配3個數字結尾, 6個數字結尾 或9個數字結尾……
(?=(\d{3})+$) 作用:匹配后面跟著 “3個數字結尾, 6個數字結尾 或9個數字結尾…… ” 的位置
(?<=\d) 作用:匹配前面跟著一個數字的位置,這就確保不會把“123,456” 轉成“,123,456”
該正則表達式全由預查結構組成,沒有匹配任何字符(如果用match()函數看的話,結果是多個空字符串,看下圖),但是卻匹配了一堆位置。再用:replace(",”),即可完成問題要求。$的作用可以優先匹配行末
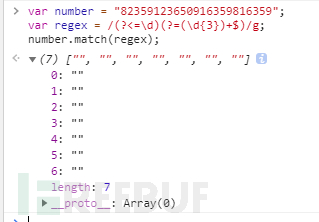
需要注意的點:與消費不消費字符 不能混為一談
可以通過一個正則表達式的模式,或者部分模式兩邊添加圓括號將導致相關匹配存儲到一個臨時緩沖區中,所捕獲的每個子匹配都按照在正則表達式模式中從左到右出現的順序存儲。緩沖區編號從 1 開始,最多可存儲 99 個捕獲的子表達式。
舉例:
1varstr='2016-05-01';2varpattern=/(\d{4})-(\d{2})-(\d{2})/;3str.match(pattern)4str.replace(pattern,'$2$3$1')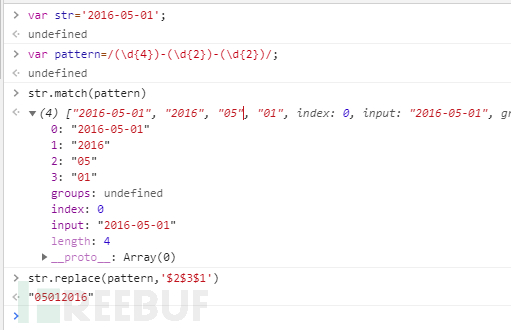
如果我們不想捕獲我們的文本,可以使用非捕獲元字符 '?:'、'?=' 或 '?!' ,這種分組正則表達式引擎不會捕獲它所匹配的內容即不會為非捕獲型分組分配組號,也就是不放在我們的內存當中,這樣也能提高我們的性能。
當正則表達式中包含能接受重復的量詞(指定數量的代碼,例如*,{5,12}等)時,通常的行為是匹配盡可能多的字符。考慮這個表達式:a.*b,它將會匹配最長的以a開始,以b結束的字符串。如果用它來搜索aabab的話,它會匹配整個字符串aabab。這被稱為貪婪匹配。
有時,我們更需要懶惰匹配,也就是匹配盡可能少的字符。前面給出的量詞都可以被轉化為懶惰匹配模式,只要在它后面加上一個問號?。這樣.*?就意味著匹配任意數量的重復,但是在能使整個匹配成功的前提下使用最少的重復。現在看看懶惰版的例子吧:
a.*?b匹配最短的,以a開始,以b結束的字符串。如果把它應用于aabab的話,它會匹配aab和ab。
(?:pattern)則跟預查那四種匹配模式根本就不是一類東西,只是長得比較像,他們的最大區別就是:(?:pattern)是匹配字符,也就是會消耗字符。
(?:pattern)是和(pattern)相對應的,他們的區別在于:(pattern)是獲取匹配,pattern內容會出現在匹配結果的中;(?:pattern)是非獲取匹配。
(?:pattern)相比(pattern)不會改變正則表達式的處理方式,只是這樣的組匹配的內容不會像(pattern)那樣被捕獲到某個組里面
例:
var reg1=/windows(?:2000|NT|98)/i var reg2=/windows(2000|NT|98)/i var str='windows2000' str.match(reg1) // ["windows2000", index: 0, input: "windows2000"] str.match(reg2) // ["windows2000", "2000", index: 0, input: "windows2000"] reg1.test(str) //true reg2.test(str) //true
可以注意到 第一個正則匹配返回的結果中沒有子匹配的返回內容
reg1和reg2匹配"windows2000"字符串都可以完全被匹配到。 ?:的結果中:只是2000沒有作為單獨的匹配結果放到組里。
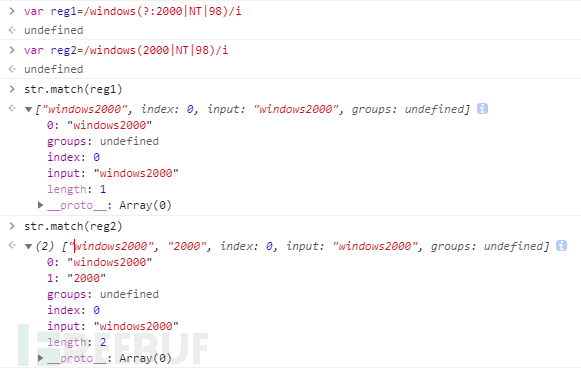
匹配一個位置,也就是不獲取字符串,不消費字符
| 代碼/語法 | 說明 |
|---|---|
| \b | 匹配單詞的開始或結束 |
| ^ | 匹配字符串的開始 |
| $ | 匹配字符串的結束 |
| \B | 匹配不是單詞開頭或結束的位置 |
| (?=exp) | 匹配后面跟著exp的位置,也就是exp前面的位置 |
| (?!exp) | 匹配后面跟的不是exp的位置 |
| (?<=exp) | 匹配前面跟著exp的位置,也就是exp后面的位置 |
| (?<!exp) | 匹配前面不是exp的位置 |
關于“正則表達式關鍵詞的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





