溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么理解大數據Lambda架構”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么理解大數據Lambda架構”吧!
縷一縷it的發展,第一階段是各大系統各大平臺的出現,解決的是線下搬到線上的效率問題,而下一個階段是數據時代,處理這些各大平臺積累的數據,積累的數據,一般比較大,大數據做的是什么,大規模的數據處理,主要是離線為主,所以就出現了hadoop的三大基礎組件,分別解決大數據存儲,計算,大表存儲,這個階段基本解決了大數據的計算,也即可以編寫出程序,完成大數據的大規模運算,后面又出現了實時處理,第一個出現的就是storm,可以處理實時的單個數據,這樣就展現了最新的數據,但是同時也看到了,如果既想要最新的又想要歷史的,要怎么辦呢,所以Storm的作者Nathan Mara提出了Lambda架構,這種架構主要解決離線數據計算結果怎么和實時處理的結果合并提供最后的結果。
首先縷縷需求,我們要的就是一種在線計算結果和離線計算結果合并的架構,試想一種信貸場景,我要得到某個用戶交易過的所有貸款機構,假設用這個結果來算多頭分,需求場景就是要實時取到最新的數據,比如上一秒交易是A機構,那下一秒交易就得拿到這個機構,那么對于歷史數據必然是要存量計算,這種計算必然是需要花費一定時間的,而上一秒交易的A機構,一般在離線倉庫里面不會馬上放進去,只能將這種數據放到實時處理里邊, 細想這種結構,要有下面幾個特點,
至少保證離線exact-once,環境有時候是不可靠的,尤其是在線系統,在保證exact-once又更差一點,通過離線復算 覆蓋在線的方式,即是重刷數據的過程
可擴展性,比如離線計算效率不行,可以通過加資源來實現
維護性,lambda架構需要保證在線離線的計算邏輯一致,盡量將邏輯用相同的方式來實現在線離線一致性
可以通過查詢接口查詢離線在線計算出來的數據
總的來說本質就是,數據記錄 + 查詢服務
前面從需求角度來說明了,一個lambda架構要滿足什么特點,我們就得到了數據記錄 + 查詢服務的這種模式,由于數據記錄的寫入方式不同,lambda架構里面把寫數據記錄的曾分為離線批計算層和在線實時計算層
我們得到下面的一個公式
為了方便查詢Query又常常作為一個view, 這樣的一個lambda架構,其實現方案又很多,比如批計算層,可以使用spark,hive等來計算 離線批大數據,而實時層可以使用程序實時計算,可以選擇Flink等框架,如果邏輯不復雜也可以使用程序直接生成,至于存儲,又可以將離線計算和實時計算的結果分開存儲或者使用時序數據庫合并存儲,另外對于查詢,既可以用程序來合并讀全部數據,有可以在視圖級別做合并。
前面講到大概lambda架構里面的三個模塊,分別為離線計算層,在線計算層,查詢服務層
首先是離線計算層,由于歷史數據較多,會放到hdfs上面,計算方式,使用mr的模型計算 就可,如果有問題,是支持批量重新計算來修復的。
其次是查詢view,對于離線預處理好的數據和在線計算結果進行合并提供服務。
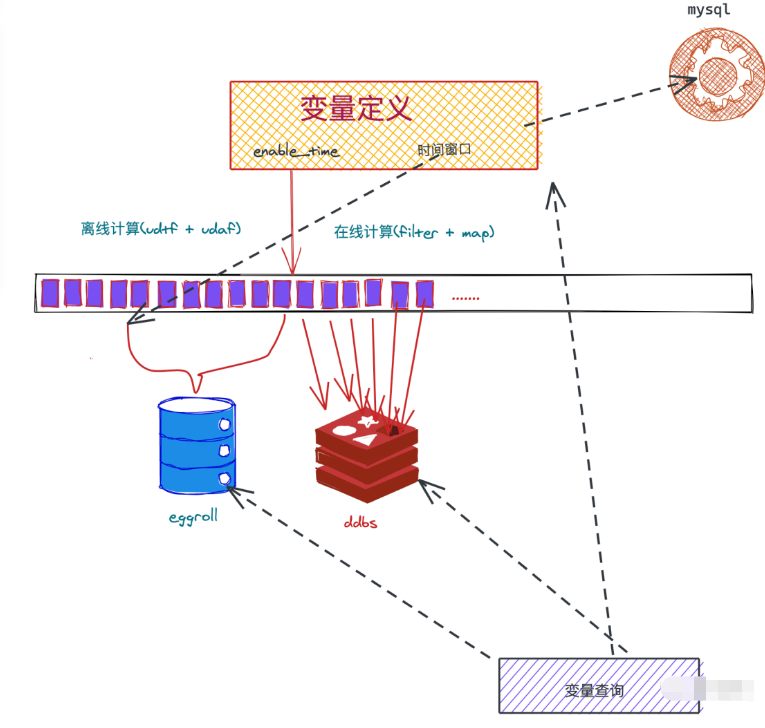
這個架構,是一種實現方式,離線計算采用hive和spark,為了和在線計算邏輯對齊,采用相同jar依賴的方式,只不過離線計算的邏輯是在udf里面,同時有個enable_time來區分在線離線數據時間點,eggroll可以理解為類似于hbase的離線kv存儲數據庫。
Lambda架構經歷多年的發展,其優點是穩定,對于實時計算部分的計算成本可控,批量處理可以用晚上的時間來整體批量計算,這樣把實時計算和離線計算高峰分開,這種架構支撐了數據行業的早期發展,但是它也有一些致命缺點,并在大數據3.0時代越來越不適應數據分析業務的需求。缺點如下:
實時與批量計算結果不一致引起的數據口徑問題:因為批量和實時計算走的是兩個計算框架和計算程序,算出的結果往往不同,經常看到一個數字當天看是一個數據,第二天看昨天的數據反而發生了變化。
批量計算在計算窗口內無法完成:在IOT時代,數據量級越來越大,經常發現夜間只有4、5個小時的時間窗口,已經無法完成白天20多個小時累計的數據,保證早上上班前準時出數據已成為每個大數據團隊頭疼的問題。
開發和維護的復雜性問題:Lambda 架構需要在兩個不同的 API(application programming interface,應用程序編程接口)中對同樣的業務邏輯進行兩次編程:一次為批量計算的ETL系統,一次為流式計算的Streaming系統。針對同一個業務問題產生了兩個代碼庫,各有不同的漏洞。這種系統實際上非常難維護
服務器存儲大:數據倉庫的典型設計,會產生大量的中間結果表,造成數據急速膨脹,加大服務器存儲壓力。
感謝各位的閱讀,以上就是“怎么理解大數據Lambda架構”的內容了,經過本文的學習后,相信大家對怎么理解大數據Lambda架構這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





