溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Hadoop無法解決的問題是什么樣的,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
因為項目的需要,學習使用了Hadoop,和所有過熱的技術一樣,“大數據”、“海量”這類詞語在互聯網上滿天亂飛。Hadoop是一個非常優秀的分布式編程框架,設計精巧而且目前沒有同級別同重量的替代品。另外也接觸到一個內部使用的框架,對于Hadoop做了封裝和定制,使得更滿足業務需求。我最近也想寫一些Hadoop的學習和使用心得,但是看到網上那么泛濫的文章,我覺得再寫點筆記一樣的東西實在是沒有價值。倒不如在漫天頌歌的時候冷靜下來看看,有哪些不適合Hadoop解決的難題呢?
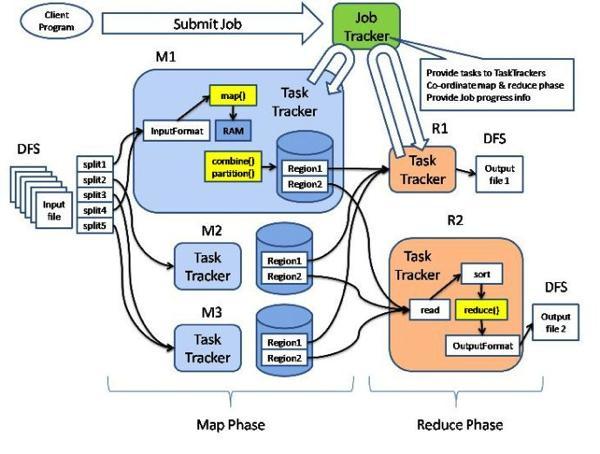
這張圖就是Hadoop的架構圖,Map和Reduce是兩個最基本的處理階段,之前有輸入數據格式定義和數據分片,之后有輸出數據格式定義,二者中間還可以實現combine這個本地reduce操作和partition這個重定向mapper輸出的策略行為。可以增加的定制和增強包括:
輸入數據和輸出數據的強化,例如通過數據集管理起來,可以統一、合并各式數據集,甚至也可以給數據增加過濾操作作為初篩,事實上業務上的核心數據源是種類繁多的;
數據分片策略的擴展,我們經常需要把具備某些業務共性的數據放到一起處理;
combine和partition的擴展,主要是有一些策略實現是在很多Hadoop的job中都是通用的;
監控工具的擴展,這方面我也見過別的公司內部定制的工具;
通訊協議和文件系統的增強,尤其是文件系統,***能用起來像接近本地命令一樣,這樣的定制在互聯網上也能找得到;
數據訪問的編程接口的進一步封裝,主要也是為了更切合業務,用著方便;
這些定制從某種程度上也反應了Hadoop在實際使用中略感局限或者設計時無暇顧及的地方,但是這些都是小問題,都是通過定制和擴展能夠修復的。但是有一些問題,是Hadoop天生無法解決的,或者說,是不適合使用Hadoop來解決的問題。
1、最最重要一點,Hadoop能解決的問題必須是可以MapReduce的。這里有兩個特別的含義,一個是問題必須可以拆分,有的問題看起來很大,但是拆分很困難;第二個是子問題必須獨立——很多Hadoop的教材上面都舉了一個斐波那契數列的例子,每一步數據的運算都不是獨立的,都必須依賴于前一步、前二步的結果,換言之,無法把大問題劃分成獨立的小問題,這樣的場景是根本沒有辦法使用Hadoop的。
2、數據結構不滿足key-value這樣的模式的。在Hadoop In Action中,作者把Hadoop和關系數據庫做了比較,結構化數據查詢是不適合用Hadoop來實現的(雖然像Hive這樣的東西模擬了ANSI SQL的語法)。即便如此,性能開銷不是一般關系數據庫可以比擬的,而如果是復雜一點的組合條件的查詢,還是不如SQL的威力強大。編寫代碼調用也是很花費時間的。
3、Hadoop不適合用來處理大批量的小文件。其實這是由namenode的局限性所決定的,如果文件過小,namenode存儲的元信息相對來說就會占用過大比例的空間,內存還是磁盤開銷都非常大。如果一次task的文件處理較大,那么虛擬機啟動、初始化等等準備時間和任務完成后的清理時間,甚至shuffle等等框架消耗時間所占的比例就小得多;反之,處理的吞吐量就掉下來了。(有人做了一個實驗,參閱:鏈接)
4、Hadoop不適合用來處理需要及時響應的任務,高并發請求的任務。這也很容易理解,上面已經說了虛擬機開銷、初始化準備時間等等,即使task里面什么都不做完整地跑一遍job也要花費幾分鐘時間。
5、Hadoop要處理真正的“大數據”,把scale up真正變成scale out,兩臺小破機器,或者幾、十幾GB這種數據量,用Hadoop就顯得粗笨了。異步系統本身的直觀性并不像那些同步系統來得好,這是顯而易見的。所以基本上來說,維護成本不會低。
上述內容就是Hadoop無法解決的問題是什么樣的,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





